從計算機出現以來,人們便孜孜不倦地追求著高效管理數據的辦法,IBM的System R,U.C. Berkeley PostgreSQL以及Oracle MySQL的誕生,無一不表明人們對于高效、快捷的數據管理的不懈追求。雖然Oracle、MySQL廣泛應用于國內外各大互聯網公司的基礎架構中,但作為另一款優秀的開源關系數據庫,PostgreSQL同樣也得到了各大互聯網公司的持續關注。
PostgreSQL概述
PostgreSQL作為關系數據庫中學院派的代表,在U.C. Berkeley完成了初始版本,其后U.C. Berkeley將其源碼交于開源社區,PostgreSQL現由開源社區對其進行維護。PostgreSQL代碼具有簡潔、結構清晰、濃重的學院派氣息等特性。雖然,其在國內并未像MySQL一樣廣泛在互聯網公司內部使用,但是隨著國內對PostgreSQL的認識加深,越來越多的公司逐漸采用PostgreSQL作為其解決方案中數據的基礎架構部件;更有許多公司在PostgreSQL的基礎上進行二次開發來滿足自己的需求。
同時,隨著數據倉庫(Dataware house)及Bussinesss Intelligence(BI)等對PostgreSQL處理能力要求的提高,眾多開源界內核開發人員以單機PostgreSQL為基礎,構建基于PostgreSQL的大規模分布式應用PostgreSQL-XL及PostgreSQL-XC。上述所有案例無一不表明雖然在MySQL大行其道的情況下,PostgreSQL仍然在開源關系型數據庫市場中占有一席之地并值得我們給予其足夠的重視。
作為數據庫內核中的重要一環,查詢引擎在整個數據庫管理系統中起到了“大腦”的作用。查詢語句是否以最優的方式來執行等均與查詢引擎有著密不可分的聯系;不同的數據庫對同一條查詢語句的執行時間各不相同,有快有慢。究其原因,除了存儲引擎之間的差別,查詢引擎生成的查詢計劃和執行計劃的優劣直接影響數據庫在查詢時的性能表現。不同的查詢引擎產生的查詢計劃千差萬別,表現在查詢效率上也千差萬別。例如,查詢語句中的連接操作(Join Operation),不同的查詢引擎產生的優化策略會導致執行時間存在著數倍甚至數百倍的差距。
作為學院派代表的PostgreSQL有著一套復雜的查詢優化策略,例如對子鏈接的處理,基于代價的優化策略,基于規則的查詢優化策略等。對于這些優化策略,PostgreSQL并非墨守成規,而是也將這些優化策略的實現接口開放給第三方的內核開發者,使得用戶可以靈活地使用適用于特定應用場景的自有優化策略。例如,pg_rewrite中描述的基于查詢語法樹的改寫(Rewrite)規則pg_rules,等等。
作為連接服務器層(Server Framework)與存儲引擎層(Storage Engine)的中間層,查詢引擎將用戶發送來的SQL語句按照scan.l和gram.y中預先定義的SQL詞法(Lexcial Rules)及語法規則(Grammatic Rules)生成查詢引擎系統內部使用的查詢語法樹形式(Abstract Syntax Tree,AST),查詢引擎會將該查詢語法樹進行預處理:將其轉換為查詢引擎可處理的形式——查詢樹Query。
在由語法樹到查詢樹的轉換過程中,查詢引擎會將查詢語句中的某些部分進行轉換。例如,“*”會被為被擴展為相對應關系表的所有列,并在后續轉換的過程中,根據語法樹所標示的類型進行分類處理,如SELECT類型語句、UPDATE類型語句、CREATE類型語句等。
在查詢引擎語法樹到查詢樹轉換后,PostgreSQL查詢引擎會使用pg_rewrite中設定的轉換規則進行所謂的基于規則的轉換,例如,PostgreSQL查詢引擎會將VIEW進行轉換,為后續的優化提供可能。
在完成了基于規則的優化后,PostgreSQL查詢引擎進入到我們稱之為邏輯優化的階段。在該階段中,PostgreSQL查詢引擎將完成對公共表達式的優化,子鏈接的上提,對JOIN/IN/ NOT IN的優化處理(進行Semi-Join、Anti-Semi-Join處理等),Lateral Join的優化等優化操作。
在執行上述優化操作中,我們將遵循一條“簡單”法則:先做選擇運行(? Operation),后做投影運算(? Operation)。經過此階段的優化操作后,所得到的查詢樹為一棵遵循了先選擇后投影規則的最優查詢樹,并以此為基礎構建最優查詢訪問路徑(Cheapest Access Path)。
在完成了對查詢樹的優化處理并獲得最優查詢訪問路徑后,PostgreSQL查詢引擎接下來要做另外一件非常重要的事情是查詢計劃的生成(Plans Generating)。PostgreSQL查詢引擎會依據最優查詢訪問路徑,通過遍歷該查詢訪問路徑,來構建最優查詢訪問路徑對應的查詢計劃(Query Plans or Plans)。
在查詢計劃的生成過程中,PostgresQL查詢引擎會在所有可行的查詢訪問路徑中選擇一條最優的查詢訪問路徑來構建查詢計劃。不同方式所構建的查詢訪問路徑的代價不盡相同,例如,執行多表JOIN操作時,不同的JOIN順序產生的查詢訪問路徑不同,而這直接導致了查詢訪問路徑中的中間元組規模的不同;同時,關系表上索引的有無也將影響查詢訪問路徑的代價,不同的表掃描方式將會極大地影響執行效率。
通常,我們依據COST = CPU_cost + IO_cost 公式來選擇一條最優的執行路徑,其中,CPU_cost表示執行該條執行計劃需要的CPU代價,IO_cost則為相應的I/O代價(啟動代價,這里我們將其計入到IO_cost中)。
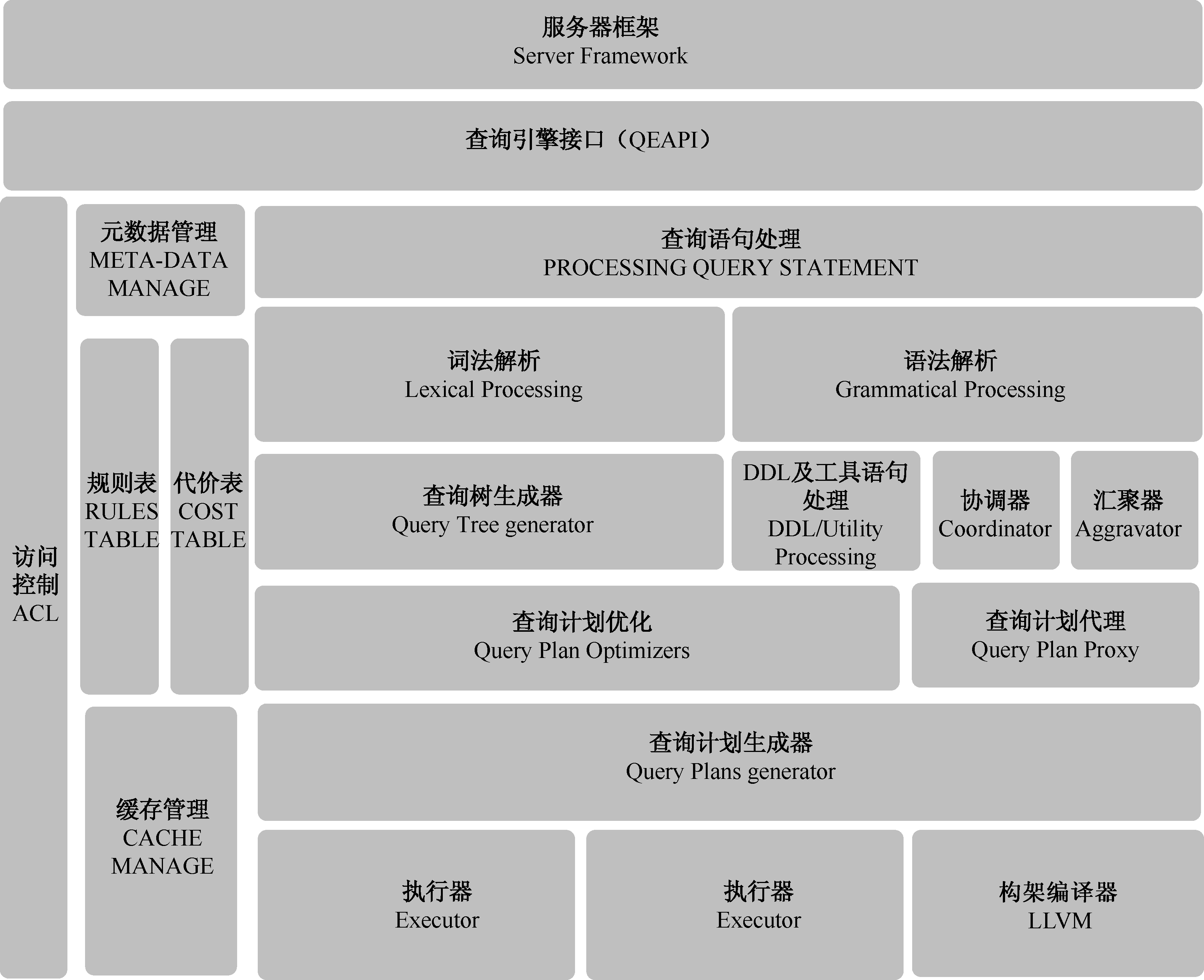
綜上所述,一個查詢引擎應該包括:查詢語句接收模塊、詞法解析模塊、語法解析模塊、查詢樹改寫模塊(規則優化模塊)、查詢優化模塊(包括邏輯優化和物理優化兩部分)、查詢計劃生成模塊、元數據管理模塊、訪問控制模塊等基本模塊。當然不同的查詢引擎在實現時,這些模塊的劃分可能不同,但是一個普通的查詢查詢都應含有上述模塊,圖1-1為一個常規的查詢引擎架構圖。
圖1-1 查詢引擎架構圖
查詢語句優化
當查詢引擎接收到一條用戶查詢請求后,查詢引擎會依據該查詢語句的類型進行分類處理;但在處理查詢語句之前,考慮到復雜查詢語句求解最優訪問路徑時的代價,有些查詢引擎會使用查詢計劃緩存機制(Query Plans Caching或Query Paths Caching):數據庫管理系統提供原生的最優查詢訪問路徑代價緩存機制或使用第三方的查詢計劃緩存解決方案。但在使用此緩存機制時需要注意:查詢語句需滿足一定條件,例如滿足不含有易失函數(Volatile Function),語句中涉及的基表定義發生變化后的正確處理等條件后,才能對其使用緩存機制,否則可能導致查詢結果不正確。
查詢引擎對不同類型的查詢語句有著不同的處理機制,對于工具類查詢語句以及非工具類查詢語句,PostgreSQL有著截然不同的處理流程。
-工具類語句
當查詢語句為工具類查詢(Utility Statements)語句時,查詢引擎將經過詞法分析和語法分析后獲得的查詢語句作為其執行計劃。工具類查詢語句由ProcessUtility函數調用standard_ProcessUtility依據該語句的類型進行分類處理。例如,對于CreateTableSpace、Truncate、PrePare、Execute、Grant等命令,查詢引擎將分別使用CreateTableSpace、ExecuteTruncate、PrepareQuery、ExecuteQuery、ExecuteGrantStmt等函數對這些命令進行分類處理。那么哪些語句可歸為工具類語句呢?
PostgreSQL將如下語句歸為工具類型語句并將其交由standard_ProcessUtility函數處理。
工具類語句中包含:事務(Transaction)類語句,例如,開始事務、提交事務、回滾事務、創建SavePoint等;游標(Cursor)類語句,例如,打開游標、遍歷游標、關閉游標等;內聯過程語句類語句(Inline Procedural-Langauge);表空間(TableSpace)操作類型語句,例如,創建表空間、刪除表空間、修改表空間參數等;Truncate類語句;注釋類語句;數據庫對象安全標簽類語句(Security Label to a Database Object);SQL Copy類語句;Prepare類型語句;權限或角色操作相關類語句;數據庫操作類語句,例如,創建數據庫、刪除數據庫等;索引維護類語句;Explain語句;Vacuum語句。
PostgreSQL調用相應的命令處理函數對上述工具類語句進行分類處理,因此,對于standard_ProcessUtility函數的實現,讀者可輕松地猜到如下的實現方式,對應其中的某類具體實現,在這里就不再詳細給出,還請讀者自行分析。函數原型如程序片段1-1所示。
程序片段1-1 standard_ProcessUtility 函數的原型
查詢類語句的處理
對于非工具類查詢語句,即普通查詢類語句,除了經歷與工具類查詢語句一樣的語法分析過程和詞法分析過程,還需完成:將原始語法樹轉換為查詢語法樹;以查詢語法樹為基礎對其進行邏輯優化;對查詢語句進行物理優化;查詢計劃創建等過程。
經過詞法分析(Lexical Processing)和語法分析(Grammatical Processing)后,PostgreSQL需要將原始語法樹轉換為查詢語法樹并在轉換過程中進行語義方面的合法性檢查。例如,基表(Base Relation)的有效性檢查,目標列(Target List)的有效性檢查及展開,基表的Namespace沖突檢查等。
transformStmt函數依據查詢語句的類型進行相應語法樹到查詢樹的轉換工作,例如,由transformSelectStmt函數完成對SELECT類型查詢語句的轉換操作,由函數transformInsertStmt完成對INSERT類型語句的語法樹的轉換。
查詢引擎將對SELECT類型查詢語句中不同的語法部分進行分類處理。由transform- TargetList函數對目標列子句進行轉換處理;transformWhereClause函數完成WHERE、HAVING子句的語法樹轉換處理;transformLimitClause函數完成Limit和Offset語句的轉換工作;transformSortClause函數和transformGroupClause分別完成對ORDER BY語句及GROUP BY語句的轉換。經過上述轉換后,我們將獲得一棵(或數棵)由原始語法樹轉換而得到的Query類型查詢樹,并以此為基礎進入到查詢優化的下一階段:基于規則的查詢改寫。
原始語法樹經過上述轉換操作后,查詢引擎獲得Query類型的查詢樹,接下來,查詢將依據系統中定義的規則,對該查詢樹進行依據規則的改寫操作,例如,視圖的改寫等。元數據表pg_rules中描述了當前系統中具有的規則說明。除了使用CREATE RULE、ALTER RULE、DROP RULE命令來維護該規則系統,我們還可以通過“暴力”手段,直接修改pg_rules元數據表來“維護”規則系統。在完成基于規則的改寫后,查詢引擎將進入下一階段的優化:查詢邏輯優化(Logical Optimization)。
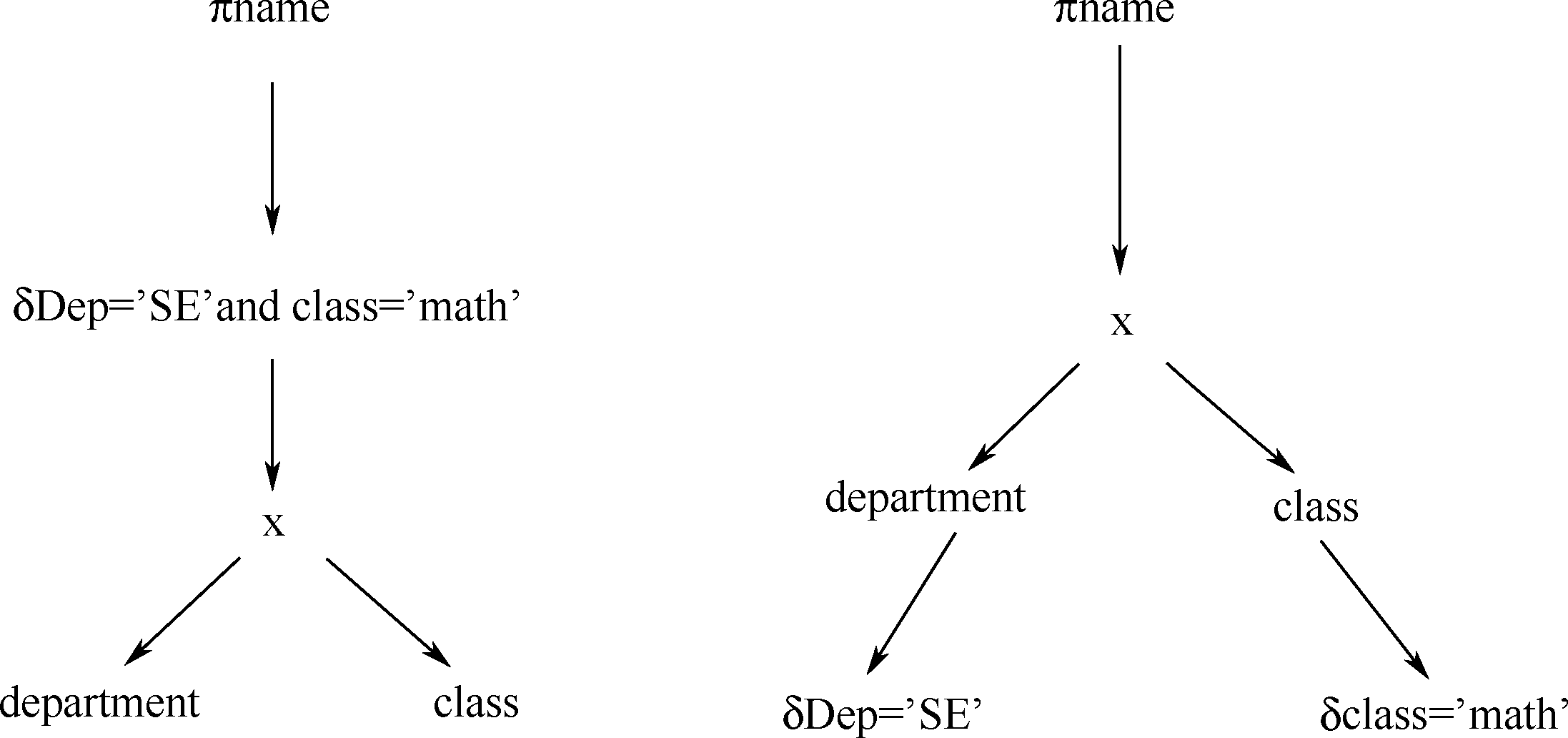
邏輯優化階段中,會對所有導致查詢變慢的語句進行等價變換,依據數據庫理論中給出的經典優化策略:選擇下推,從而盡可能減少中間結果的產生。即所謂的先做選擇操作,后做投影操作。優化原則如圖1-2所示。
首先,查詢引擎由函數pull_up_sublinks分別對IN和EXISTS類型子鏈接(SubLink)進行優化處理:將子鏈接轉為SEMI-JOIN,使得子鏈接中的子查詢有機會與父查詢語句進行合并優化。函數pull_up_sublinks中,PostgreSQL在確定子鏈接滿足SEMI-JOIN轉換的條件后,分別由convert_ANY_sublink_to_join函數及convert_EXISTS_sublink_to_join函數將IN和EXISTS類型的子鏈接轉換為SEMI-JOIN類型的JOIN連接。經過轉換后,查詢效率較低的IN/EXISTS子鏈接操作轉換為查詢效率較高的JOIN操作。
圖1-2 優化原則
完成子鏈接轉換后,查詢引擎將使用函數pull_up_subqueries對查詢樹中的子查詢(SubQuery)進行上提操作,將子查詢中的基表(Base Relation)上提至父查詢中,從而使子查詢中的基表有機會與父查詢中的基表進行合并,由查詢引擎統一進行優化處理。
接下來,查詢引擎使用preprocess_expression函數對查詢樹中的表達式進行預處理,例如,將表達式進行規則化,常量表達式求值優化等。
在完成對查詢樹中表達式的優化處理后,查詢引擎將對查詢約束條件進行相關優化處理。例如,約束條件的下推,約束條件的合并、推導及無效約束條件的移除等。隨后,查詢引擎將優化處理后的約束條件綁定到其對應的基表之上,即所謂的約束條件的分配(Distribute the Restriction Clauses)。在完成上述操作后,查詢引擎將進入全新的優化階段:查詢物理優化(Physical Optimization)。
查詢物理優化階段最主要的任務是選擇出一條查詢代價最優的查詢訪問路徑(Query Access Path,Path)。依據邏輯優化階段所得的查詢樹為基礎構建一條最小查詢訪問代價的查詢路徑。為了能夠正確且高效地計算出不同查詢訪問路徑下的查詢代價,查詢引擎依據基表之上存在的約束條件,估算出獲取滿足該約束條件的元組需要的I/O代價和CPU代價。我們以概率論和統計分析為工具,通過元數據表pg_statistic中的統計信息計算出滿足該約束條件的元組占整個元組的比重,以此來估算該約束條件下的元組數量。通常,我們使用選擇率(Selectivity)來描述上述的比重。
在完成對查詢語句中涉及的各個基表的物理參數和約束條件的設置后,查詢引擎將考察各個基表所能形成的連接關系。若計算后,兩個基表可形成連接關系,則查詢引擎將進一步嘗試確立連接類型并完成對此種連接條件下的查詢代價估算。例如,兩個基表是否可以構成MergeJoin?HashJoin?還是傳統的NestLoopJoin?上述就是我們通常所說的查詢路徑尋優的過程。當查詢語句中涉及的基表數量較小時,由于其對應的最優解(最優查詢訪問路徑)搜索空間較小,PostgreSQL將采用動態規劃算法(Dynamic Programming)來求解最優查詢訪問路徑;但當查詢中涉及的基表數量較多時(該閾值將在后續章節進行討論),將導致最優解的搜索空間以指數倍(Exponential)增長。此時,傳統的動態規劃算法將無法滿足求解要求。為解決由于基表數量的增加所帶來最優解求解時間的極速增長,PostgreSQL查詢引擎引入了基因遺傳算法(Genetic Algorithm)來加速最優解的求解。
在成功地獲得一條(相對)最優的查詢訪問路徑后。接下來,查詢引擎將以該查詢訪問路徑為藍本,構建查詢訪問路徑所對應的查詢計劃。
創建查詢計劃
作為查詢引擎所有工作的最終結果——查詢計劃描述了對查詢語句的求解過程。按照查詢計劃所描述的步驟,執行引擎只需“按部就班”地操作即可獲取最終的查詢結果。
與查詢語句在邏輯優化和物理優化階段不同,查詢計劃創建階段的模塊的功能相對單一,無須較多的查詢優化理論知識,只需依照最優查詢訪問路徑所描述的步驟,分類創建其對應的查詢計劃節點(Plans),最后將所有查詢計劃節點合并形成最后的查詢計劃樹。
在create_plan函數中,查詢引擎將依據查詢訪問路徑中的各個節點類型,分類創建其對應的查詢計劃:由create_seqscan_plan函數創建順序掃描查詢計劃;由create_mergejoin_ plan函數創建MergeJoin查詢計劃;create_hashjoin_plan函數則以HashJoin類型的查詢訪問路徑為參數構建HashJoin查詢計劃。
在獲得查詢計劃后,PostgreSQL將查詢計劃送入執行器(Executor)中,執行器依據查詢計劃執行給出的表掃描操作獲取滿足條件的元組后按照指定的格式進行輸出。
小結
我們將上述的優化過程簡短地描述為如下流程:
(1)由應用程序建立到PostgreSQL服務器的連接。應用服務器發送查詢請求至PostgresSQL服務器并從PostgreSQL服務器接收查詢結果。
(2)查詢引擎將查詢語句依據所定義的詞法規則和語法規則構建原始查詢語法樹。
(3)查詢分析階段,查詢引擎將原始語法樹轉換為查詢樹。
(4)查詢改寫階段,查詢引擎將查詢樹依據系統中預先定義的規則對查詢樹進行轉換。
(5)優化器(Planner)接收改寫后的查詢樹并依據該查詢樹完成查詢邏輯優化。
(6)優化器(Planner)繼續對已完成邏輯優化的查詢樹進行查詢物理優化并求解最優查詢訪問路徑。
(7)執行器(Executor)依據最優查詢訪問路徑進行表掃描操作并將獲取的數據按一定格式創建返回值,然后將結果返回應用程序。
那么上述討論的查詢引擎所完成的工作是如何將數據庫查詢優化理論具體化的呢?那些pull_up函數和約束條件的處理又是如何完成的呢?是否所有的子鏈接和子查詢都可以進行轉換?兩個基表構成連接所需要滿足什么樣的條件呢?PostgreSQL查詢引擎在系統實現上又有什么值得我們學習的地方呢?帶著種種的疑問,打開《PostgreSQL查詢引擎源碼技術探析》開始我們的查詢引擎內核分析之旅吧。
相關圖書
《PostgreSQL查詢引擎源碼技術探析》
騰訊TDSQL數據庫技術專家、
MySQL技術專家力薦
李浩 編著
2016年8月出版
以內核開發人員的角度抽絲剝繭,帶您深入淺出PostgreSQL查詢引擎內核技術內幕。
版权声明:本站所有资料均为网友推荐收集整理而来,仅供学习和研究交流使用。

工作时间:8:00-18:00
客服电话
电子邮件
admin@qq.com
扫码二维码
获取最新动态






![Bzoj4822 [Cqoi2017]老C的任务](/upload/rand_pic/2-001.jpg)







