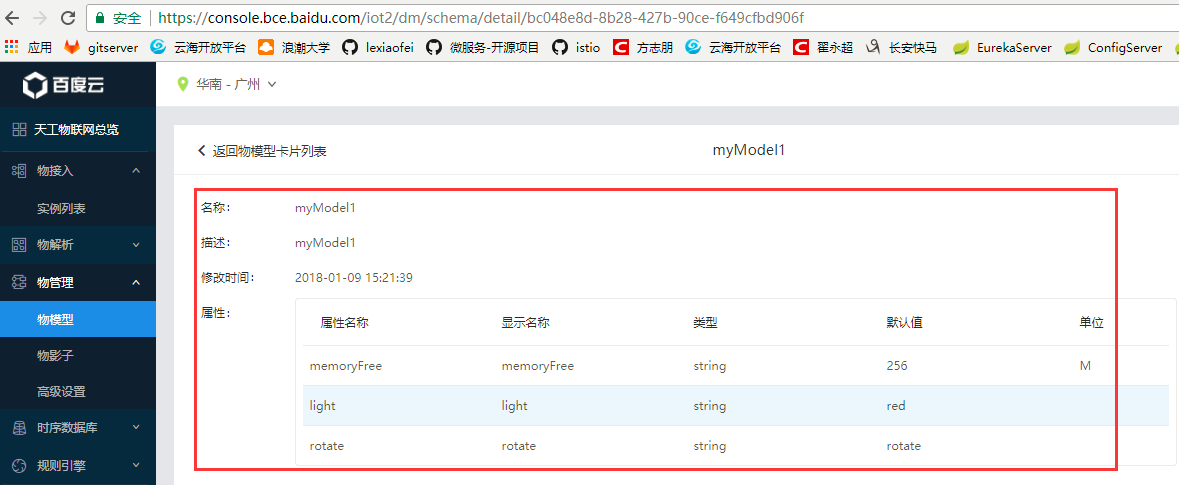
MLlib 是 Spark 的機器學習 (ML) 庫。其目標是使實用的機器學習變得可擴展且簡單。在高級別上,它提供了各種工具::
ML 算法:常見的學習算法,如分類、回歸、聚類和協作篩選
實現:特征提取、變換、尺寸減小和選擇
管道:用于構建、評估和調整 ML 管道的工具
持久性:保存和加載算法、模型和管道
實用工具:線性代數、統計、數據處理等。
hadoop菜鳥入門、計算兩個數據系列之間的相關性是統計學中的常見操作。
import org.apache.spark.ml.linalg.{Matrix, Vectors}
import org.apache.spark.ml.stat.Correlation
import org.apache.spark.sql.{DataFrame, Row, SparkSession}object MLTest {def main(args: Array[String]): Unit = {val spark: SparkSession = SparkSession.builder().master("local").getOrCreate()import spark.implicits._val data = Seq(//使用無序(索引,值)對創建稀疏向量。Vectors.sparse(4, Seq((0, 1.0), (3, -2.0))),//根據其值創建密集向量。Vectors.dense(4.0, 5.0, 0.0, 3.0),Vectors.dense(6.0, 7.0, 0.0, 8.0),Vectors.sparse(4, Seq((0, 9.0), (3, 1.0))))val df = data.map(Tuple1.apply).toDF("features")//計算向量輸入數據集的皮爾遜相關矩陣。//Returns the first row.val Row(coeff1: Matrix) = Correlation.corr(df, "features").headprintln(s"Pearson correlation matrix:\n $coeff1")val Row(coeff2: Matrix) = Correlation.corr(df, "features", "spearman").headprintln(s"Spearman correlation matrix:\n $coeff2")}
}
Spearman correlation matrix:1.0 0.10540925533894532 NaN 0.40000000000000174
0.10540925533894532 1.0 NaN 0.9486832980505141
NaN NaN 1.0 NaN
0.40000000000000174 0.9486832980505141 NaN 1.0
Basic Statistics - Spark 3.0.1 Documentation
版权声明:本站所有资料均为网友推荐收集整理而来,仅供学习和研究交流使用。

工作时间:8:00-18:00
客服电话
电子邮件
admin@qq.com
扫码二维码
获取最新动态