初學 Go 語言的朋友總會在傳 []byte 和 string 之間有著很多糾結,實際上是沒有了解 string 與 slice 的本質,而且讀了一些程序源碼,也發現很多與之相關的問題,下面類似的代碼估計很多初學者都寫過,也充分說明了作者當時內心的糾結:
package mainimport "bytes"func xx(s []byte) []byte{ .... return s}func main(){ s := "xxx" s = string(xx([]byte(s))) s = string(bytes.Replace([]byte(s), []byte("x"), []byte(""), -1))}雖然這樣的代碼并不是來自真實的項目,但是確實有人這樣設計,單從設計上看就很糟糕了,這樣設計的原因很多人說:“slice 是引用類型,傳遞引用類型效率高呀”,主要原因不了解兩者的本質,加上文檔上說 Go 的引用類型有兩種:slice 和 map ,這個在面試中也是經常遇到的吧。
上面這個例子如果覺得有點基礎和可愛,下面這個例子貌似并不那么容易說明其存在的問題了吧。
package mainfunc xx(s *string) *string{ .... return s}func main(){ s := "xx" s = *xx(&s) ss :=[]*string{} ss = append(ss, &s)}指針效率高,我就用指針多好,可以減少內存分配呀,設計函數都接收指針變量,程序性能會有很大提升,在實際的項目中這種例子也不少見,我想通過這篇文檔來幫助初學者走出誤區,減少適得其反的優化技巧。
string byte 互相轉換?slice 的定義
slice 本身包含一個指向底層數組的指針,一個 int 類型的長度和一個 int 類型的容量, 這就是 slice 的本質, []byte 本身也是一個 slice,只是底層數組存儲的元素是 byte。下面這個圖就是 slice 的在內存中的狀態:
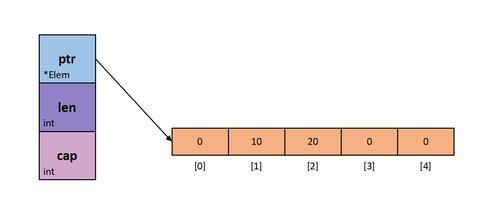
看一下 reflect.SliceHeader 如何定義 slice 在內存中的結構吧:
type SliceHeader struct { Data uintptr Len int Cap int}slice 是引用類型是 slice 本身會包含一個地址,在傳遞 slice 時只需要分配 SliceHeader 就好了, 而 SliceHeader只包含了三個 int 類型,相當于傳遞一個 slice 就只需要拷貝 SliceHeader,而不用拷貝整個底層數組,所以才說 slice是引用類型的。
那么字符串呢,計算機中我們處理的大多數問題都和字符串有關,難道傳遞字符串真的需要那么高的成本,需要借助 slice 和指針來減少內存開銷嗎。
java三個引用類型、string 的定義
reflect 包里面也定義了一個 StringHeader 看一下吧:
type StringHeader struct { Data uintptr Len int}字符串只包含了兩個 int 類型的數據,其中一個是指針,一個是字符串的長度,從定義上來看 string 也是引用類型。
借助 unsafe 來分析一下情況是不是這樣吧:
package mainimport ( "reflect" "unsafe" "github.com/davecgh/go-spew/spew")func xx(s string) { sh := *(*reflect.StringHeader)(unsafe.Pointer(&s)) spew.Dump(sh)}func main() { s := "xx" sh := *(*reflect.StringHeader)(unsafe.Pointer(&s)) spew.Dump(sh) xx(s) xx(s[:1]) xx(s[1:])}上面這段代碼的輸出如下:
(reflect.StringHeader) { Data: (uintptr) 0x10f5ee0, Len: (int) 2}(reflect.StringHeader) { Data: (uintptr) 0x10f5ee0, Len: (int) 2}(reflect.StringHeader) { Data: (uintptr) 0x10f5ee0, Len: (int) 1}(reflect.StringHeader) { Data: (uintptr) 0x10f5ee1, Len: (int) 1}golang數據類型,可以發現前三個輸出的指針都是同一個地址,第四個的地址發生了一個字節的偏移,分析來看傳遞字符串確實沒有分配新的內存,同時和 slice 一樣即使傳遞字符串的子串也不會分配新的內存空間,而是指向原字符串的中的一個位置。
這樣說來把 string 轉成 []byte 還浪費的一個 int 的空間呢,需要分配更多的內存,真是適得其反呀,而且類型轉換會發生內存拷貝,從 string 轉為 []byte 才是真的把 string 底層數據全部拷貝一遍呢,真是得不償失呀。
string 的兩個小特性
字符串還有兩個小特性,針對字面量(就是直接寫在程序中的字符串),會創建在只讀空間上,并且被復用,看一下下面的一個小例子:
package mainimport ( "reflect" "unsafe" "github.com/davecgh/go-spew/spew")func main() { a := "xx" b := "xx" c := "xxx" spew.Dump(*(*reflect.StringHeader)(unsafe.Pointer(&a))) spew.Dump(*(*reflect.StringHeader)(unsafe.Pointer(&b))) spew.Dump(*(*reflect.StringHeader)(unsafe.Pointer(&c)))}從輸出可以了解到,相同的字面量會被復用,但是子串是不會復用空間的,這就是編譯器給我們帶來的福利了,可以減少字面量字符串占用的內存空間。
(reflect.StringHeader) { Data: (uintptr) 0x10f5ea0, Len: (int) 2}(reflect.StringHeader) { Data: (uintptr) 0x10f5ea0, Len: (int) 2}(reflect.StringHeader) { Data: (uintptr) 0x10f5f2e, Len: (int) 3}java byte類型。另一個小特性大家都知道,就是字符串是不能修改的,如果我們不希望調用函數修改我們的數據,最好傳遞字符串,高效有安全。
不過有了 unsafe 這個黑魔法,字符串的這一個特性也就不那么可靠了。
package mainimport ( "fmt" "reflect" "strings" "unsafe")func main() { a := strings.Repeat("x版权声明:本站所有资料均为网友推荐收集整理而来,仅供学习和研究交流使用。

工作时间:8:00-18:00
客服电话
电子邮件
admin@qq.com
扫码二维码
获取最新动态