一个MapReduce作业的计算工作都由TaskTracker完成, 用户向Hadoop提交作业,JobTracke:会将该作业拆分为多个任务,并根据心跳信息交由空闲的TaskTracker启动。一个TaskTracker能够启动的任务数量是由TaskTracker配置的任务槽(slot)决定。槽是Hadoop的计算资源的表示模型,Hadoop将各个节点上的多维度资源(CPU、内存等)抽象成一维度的槽,这样就将多维度资源分配问题转换成一维度的槽分配的问题。在实际情况中,Map任务和Reduce任务需要的计算资源不尽相同,Hadoop又将槽分成Map槽和Reduce槽,并且 Map任务只能使用Map槽,Reduce任务只能使用Reduce槽,如图示。
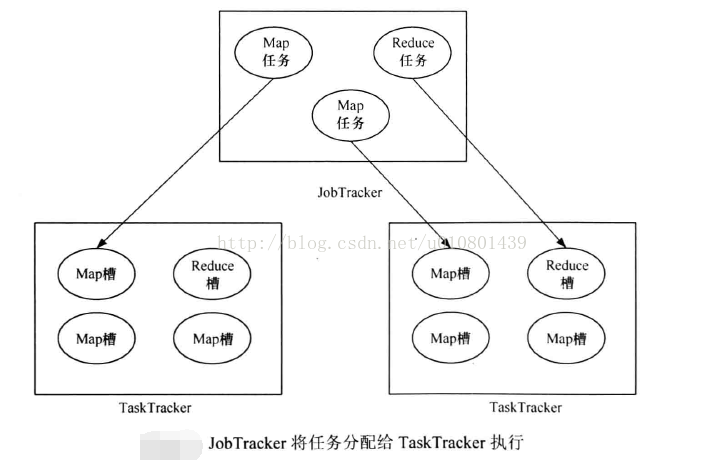
Hadoop的资源管理采用了静态资源设置方案,即每个节点配置好Map槽和Reduce槽的数量(配置项为mapred-site.xml的mapred.tasktracker.map.tasks.maximum和mapred.tasktracker.reduce.tasks.maximum ),一旦 Hadoop启动后将无法动态更改。
这样的资源管理方案是有一定的弊端。
(1)槽被设定为Map槽和Reduce槽,会导致在某一时刻Map槽或Reduce槽紧缺,降低
了槽的使用率。
(2)不能动态地设置槽数量,可能会导致某一个TaskTracker资源使用率过高或过低。
(3)提交的作业是多样化的,如果一个任务需要1 GB内存,将会产生资源浪费,如果一
个任务需要3 GB内存,则会发生资源抢占的情况。
在Hadoop(CDH4, CDH5)中,上述的弊端已经得到了很大程度地解决。
本文参考书籍------Hadoop海量数据处理 技术详解与项目实战










