HashShuffle
所謂Shuffle就是將不同節點上相同的Key拉取到一個節點的過程。這之中涉及到各種IO,所以執行時間勢必會較長,Spark的Shuffle在1.2之前默認的計算引擎是HashShuffleManager,不過HashShuffleManager有一個十分嚴重的弊端,就是會產生大量的中間文件。在1.2之后默認Shuffle改為SortShuffleManager,相對于之前,在每個Task雖然也會產生大量中間文件,但是最后會將所有的臨時文件合并(merge)成一個文件。因此Shuffle read只需要讀取時,根據索引拿到每個磁盤的部分數據就可以了
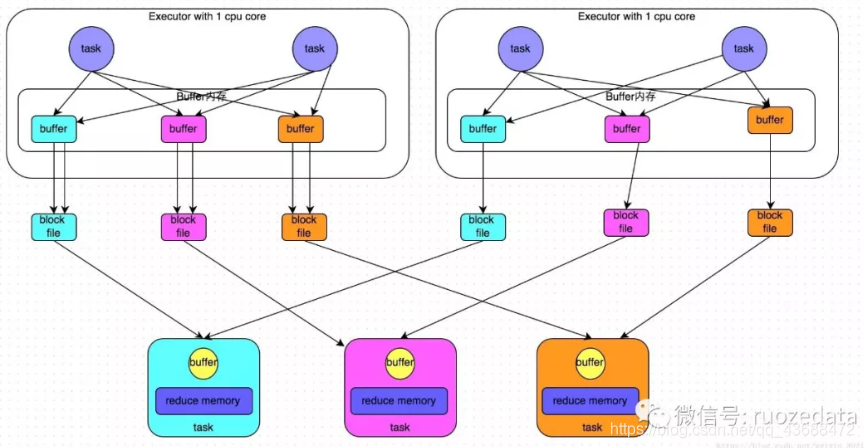
每個Executor只有一個CUP(core),同一時間每個Executor只能執行一個task
首先從shuffle write階段,主要是在一個stage結束后,為了下一個stage可以執行shuffle,將每一個task的數據按照key進行分類,對key進行hash算法,從而使相同的key寫入同一個文件,每個磁盤文件都由下游stage的一個task讀取。在寫入磁盤時,先將數據寫入內存緩沖,當內存緩沖填滿后,才會溢寫到磁盤文件(似乎所以寫文件都需要寫入先寫入緩沖區,然后再溢寫,防止頻繁IO)
我們可以先算一下當前stage的一個task會為下一個stage創建多少個磁盤文件。若下一個stage有100個task,則當前stage的每一個task都將創建100個文件,若當前stage要處理的task為50個,共有10個Executor,也就是說每個Executor共執行5個task,5x100x10=1000。也就是說這么一個小規模的操作會生產5000個文件。這是相當可觀的。
而shuffle read 通常是一個stage一開始要做的事情。此時stage的每一個task去將上一個stage的計算結果的所有相同的key從不同節點拉到自己所在節點。進行聚合或join操作。在shuffle write過程,每個task給下游的每個task都創建了一個磁盤文件。在read過程task只需要去上游stage的task中拉取屬于自己的磁盤文件。
shuffle read是邊拉取邊聚合。每一個read task都有一個buffer緩沖,然后通過內存中的Map進行聚合,每次只拉取buffer大小的數據,放到緩沖區中聚合,直到所有數據都拉取完。
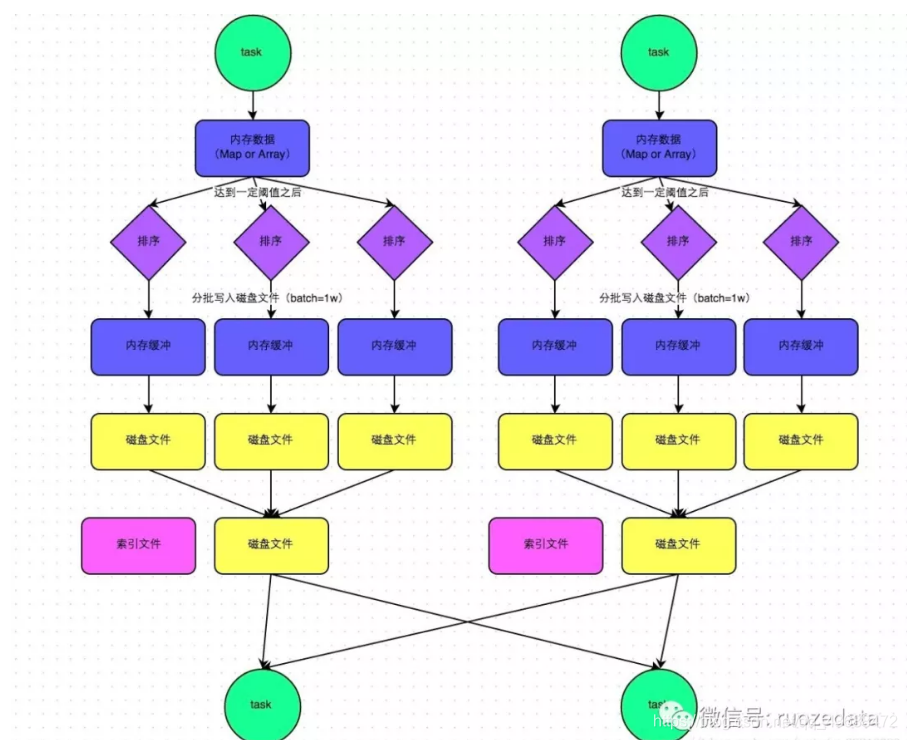
在Spark1.2版本之后,出現了SortShuffle,這種方式以更少的中間磁盤文件產生而遠遠優于HashShuffle。而它的運行機制主要分為兩種。一種為普通機制,另一種為bypass機制。而bypass機制的啟動條件為,當shuffle read task的數量小于等于spark.shuffle.sort.bypassMergeThreshold參數的值時(默認為200),就會啟用bypass機制。即當read task不是那么多的時候,采用bypass機制是更好的選擇。
在該模式下,數據會先寫入一個數據結構,聚合算子寫入Map,一邊通過Map局部聚合,一遍寫入內存。Join算子寫入ArrayList直接寫入內存中。然后需要判斷是否達到閾值,如果達到就會將內存數據結構的數據寫入到磁盤,清空內存數據結構。
在溢寫磁盤前,先根據key進行排序,排序過后的數據,會分批寫入到磁盤文件中。默認批次為10000條,數據會以每批一萬條寫入到磁盤文件。寫入磁盤文件通過緩沖區溢寫的方式,每次溢寫都會產生一個磁盤文件,也就是說一個task過程會產生多個臨時文件。
最后在每個task中,將所有的臨時文件合并,這就是merge過程,此過程將所有臨時文件讀取出來,一次寫入到最終文件。意味著一個task的所有數據都在這一個文件中。同時單獨寫一份索引文件,標識下游各個task的數據在文件中的索引,start offset和end offset。
這樣算來如果第一個stage 50個task,每個Executor執行一個task,那么無論下游有幾個task,就需要50個磁盤文件。
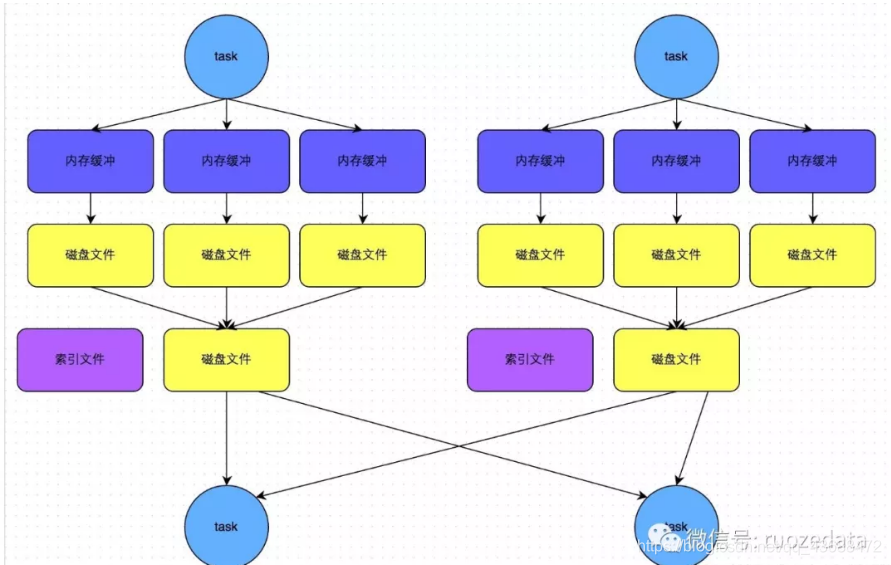
bypass機制運行條件:
1.shuffle map task數量小于spark.shuffle.sort.bypassMergeThreshold參數的值。
2.不是聚合類的shuffle算子(比如reduceByKey)。
在這種機制下,當前stage的task會為每個下游的task都創建臨時磁盤文件。將數據按照key值進行hash,然后根據hash值,將key寫入對應的磁盤文件中(個人覺得這也相當于一次另類的排序,將相同的key放在一起了)。最終,同樣會將所有臨時文件依次合并成一個磁盤文件,建立索引。
該機制與未優化的hashshuffle相比,沒有那么多磁盤文件,下游task的read操作相對性能會更好。
該機制與sortshuffle的普通機制相比,在readtask不多的情況下,首先寫的機制是不同,其次不會進行排序。這樣就可以節約一部分性能開銷。
版权声明:本站所有资料均为网友推荐收集整理而来,仅供学习和研究交流使用。

工作时间:8:00-18:00
客服电话
电子邮件
admin@qq.com
扫码二维码
获取最新动态












