Java技術棧
www.javastack.cn
關注優質文章
為什么 MySQL 使用 B+ 樹是面試中經常會出現的問題,很多人對于這個問題可能都有一些自己的理解,但是多數的回答都不夠完整和準確。大多數人都只會簡單說一下 B+ 樹和 B 樹的區別,但是都沒有真正回答 MySQL 為什么選擇使用 B+ 樹這個問題,我們在這篇文章中就會深入分析 MySQL 選擇 B+ 樹背后的一些原因。 我們在使用 SQL 語句創建表時就可以為當前表指定使用的存儲引擎,你能在 MySQL 的文檔 Alternative Storage Engines 中找到它支持的全部存儲引擎,例如:
我們在使用 SQL 語句創建表時就可以為當前表指定使用的存儲引擎,你能在 MySQL 的文檔 Alternative Storage Engines 中找到它支持的全部存儲引擎,例如:MyISAM、CSV、MEMORY等,然而默認情況下,使用如下所示的 SQL 語句來創建表就會得到 InnoDB 存儲引擎支撐的表:CREATE?TABLE?t1 (
????a INT,
????b CHAR?(20
), PRIMARY KEY?(a)) ENGINE=InnoDB;數據庫b樹和b+樹,想要詳細了解 MySQL 默認存儲引擎的讀者,可以通過之前的文章 『淺入淺出』MySQL 和 InnoDB 了解包括 InnoDB 存儲方式、索引和鎖等內容,我們在這里主要不會介紹 InnoDB 相關的過多內容。
我們今天最終將要分析的問題其實還是,為什么 MySQL 默認的存儲引擎 InnoDB 會使用 MySQL 來存儲數據,相信對 MySQL 稍微有些了解的人都知道。
無論是表中的數據(主鍵索引)還是輔助索引最終都會使用 B+ 樹來存儲數據,其中前者在表中會以 的方式存儲,而后者會以 的方式進行存儲,這其實也比較好理解:
在主鍵索引中,id 是主鍵,我們能夠通過 id 找到該行的全部列;
在輔助索引中,索引中的幾個列構成了鍵,我們能夠通過索引中的列找到 id,如果有需要的話,可以再通過 id 找到當前數據行的全部內容;
B包含于a,對于 InnoDB 來說,所有的數據都是以鍵值對的方式存儲的,主鍵索引和輔助索引在存儲數據時會將 id 和 index 作為鍵,將所有列和 id 作為鍵對應的值。
在具體分析 InnoDB 使用 B+ 樹背后的原因之前,我們需要為 B+ 樹找幾個『假想敵』,因為如果我們只有一個選擇,那么選擇 B+ 樹也并不值得討論,找到的兩個假想敵就是 B 樹和哈希,相信這也是很多人會在面試中真實遇到的問題,我們就以這兩種數據結構為例,分析比較 B+ 樹的優點。
到了這里我們已經明確了今天待討論的問題,也就是為什么 MySQL 的 InnoDB 存儲引擎會選擇 B+ 樹作為底層的數據結構,而不選擇 B 樹或者哈希?在這一節中,我們將通過以下的兩個方面介紹 InnoDB 這樣選擇的原因。
InnoDB 需要支持的場景和功能需要在特定查詢上擁有較強的性能;
B樹1001B樹?CPU 將磁盤上的數據加載到內存中需要花費大量的時間,這使得 B+ 樹成為了非常好的選擇;
數據的持久化以及持久化數據的查詢其實是一個常見的需求,而數據的持久化就需要我們與磁盤、內存和 CPU 打交道;MySQL 作為 OLTP 的數據庫不僅需要具備事務的處理能力,而且要保證數據的持久化并且能夠有一定的實時數據查詢能力,這些需求共同決定了 B+ 樹的選擇,接下來我們會詳細分析上述兩個原因背后的邏輯。
很多人對 OLTP 這個詞可能不是特別了解,我們幫助各位讀者快速理解一下,與 OLTP 相比的還有 OLAP,它們分別是 Online Transaction Processing 和 Online Analytical Processing,從這兩個名字中我們就可以看出,前者指的就是傳統的關系型數據庫,主要用于處理基本的、日常的事務處理,而后者主要在數據倉庫中使用,用于支持一些復雜的分析和決策。
作為支撐 OLTP 數據庫的存儲引擎,我們經常會使用 InnoDB 完成以下的一些工作:
B類、通過 INSERT、UPDATE 和 DELETE 語句對表中的數據進行增加、修改和刪除;
通過 UPDATE 和 DELETE 語句對符合條件的數據進行批量的刪除;
通過 SELECT 語句和主鍵查詢某條記錄的全部列;
通過 SELECT 語句在表中查詢符合某些條件的記錄并根據某些字段排序;
通過 SELECT 語句查詢表中數據的行數;
hash索引和b樹索引的區別、通過唯一索引保證表中某個字段或者某幾個字段的唯一性;
如果我們使用 B+ 樹作為底層的數據結構,那么所有只會訪問或者修改一條數據的 SQL 的時間復雜度都是 O(log n),也就是樹的高度,但是使用哈希卻有可能達到 O(1) 的時間復雜度,看起來是不是特別的美好。但是當我們使用如下所示的 SQL 時,哈希的表現就不會這么好了:
SELECT?* FROM?posts WHERE?author = 'draven'?ORDER?BY?created_at DESC
SELECT?* FROM?posts WHERE?comments_count > 10
UPDATE?posts SET?github = 'github.com/draveness'?WHERE?author = 'draven'
DELETE?FROM?posts WHERE?author = 'draven'如果我們使用哈希作為底層的數據結構,遇到上述的場景時,使用哈希構成的主鍵索引或者輔助索引可能就沒有辦法快速處理了,它對于處理范圍查詢或者排序性能會非常差,只能進行全表掃描并依次判斷是否滿足條件。
全表掃描對于數據庫來說是一個非常糟糕的結果,這其實也就意味著我們使用的數據結構對于這些查詢沒有其他任何效果,最終的性能可能都不如從日志中順序進行匹配。
b樹的建立過程、使用 B+ 樹其實能夠保證數據按照鍵的順序進行存儲,也就是相鄰的所有數據其實都是按照自然順序排列的,使用哈希卻無法達到這樣的效果,因為哈希函數的目的就是讓數據盡可能被分散到不同的桶中進行存儲,所以在遇到可能存在相同鍵 author = 'draven 或者排序以及范圍查詢 comments_count > 10 時,由哈希作為底層數據結構的表可能就會面對數據庫查詢的噩夢 —— 全表掃描。
B 樹和 B+ 樹在數據結構上其實有一些類似,它們都可以按照某些順序對索引中的內容進行遍歷,對于排序和范圍查詢等操作,B 樹和 B+ 樹相比于哈希會帶來更好的性能,當然如果索引建立不夠好或者 SQL 查詢非常復雜,依然會導致全表掃描。
與 B 樹和 B+ 樹相比,哈希作為底層的數據結構的表能夠以 O(1) 的速度處理單個數據行的增刪改查,但是面對范圍查詢或者排序時就會導致全表掃描的結果,而 B 樹和 B+ 樹雖然在單數據行的增刪查改上需要 O(log n) 的時間,但是它會將索引列相近的數據按順序存儲,所以能夠避免全表掃描。
既然使用哈希無法應對我們常見的 SQL 中排序和范圍查詢等操作,而 B 樹和 B 樹和 B+ 樹都可以相對高效地執行這些查詢,那么為什么我們不選擇 B 樹呢?這個原因其實非常簡單 —— 計算機在讀寫文件時會以頁為單位將數據加載到內存中。頁的大小可能會根據操作系統的不同而發生變化,不過在大多數的操作系統中,頁的大小都是 4KB,你可以通過如下的命令獲取操作系統上的頁大小:
$?getconf PAGE_SIZE
4096當我們需要在數據庫中查詢數據時,CPU 會發現當前數據位于磁盤而不是內存中,這時就會觸發 I/O 操作將數據加載到內存中進行訪問,數據的加載都是以頁的維度進行加載的,然而將數據從磁盤讀取到內存中所需要的成本是非常大的,普通磁盤(非 SSD)加載數據需要經過隊列、尋道、旋轉以及傳輸的這些過程,大概要花費作者使用 macOS 系統的頁大小就是
4KB,當然在不同的計算機上得到不同的結果是完全有可能的。
10ms左右的時間。 我們在估算 MySQL 的查詢時就可以使用
我們在估算 MySQL 的查詢時就可以使用 10ms這個數量級對隨機 I/O 占用的時間進行估算,這里想要說的是隨機 I/O 對于 MySQL 的查詢性能影響會非常大,而順序讀取磁盤中的數據時速度可以達到 40MB/s,這兩者的性能差距有幾個數量級,由此我們也應該盡量減少隨機 I/O 的次數,這樣才能提高性能。B 樹與 B+ 樹的最大區別就是,B 樹可以在非葉結點中存儲數據,但是 B+ 樹的所有數據其實都存儲在葉子節點中,當一個表底層的數據結構是 B 樹時,假設我們需要訪問所有『大于 4,并且小于 9 的數據』: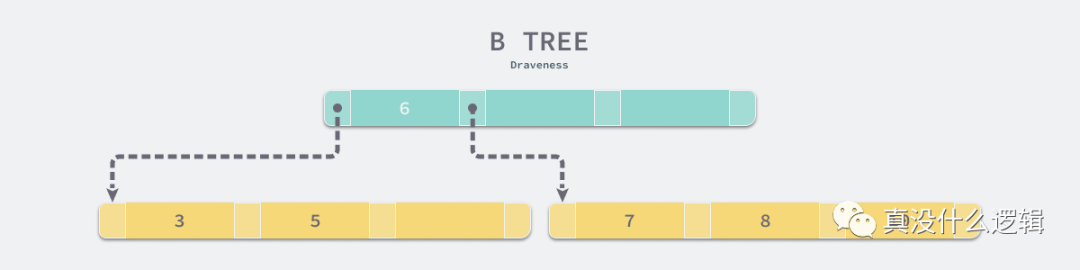 如果不考慮任何優化,在上面的簡單 B 樹中我們需要進行 4 次磁盤的隨機 I/O 才能找到所有滿足條件的數據行:
如果不考慮任何優化,在上面的簡單 B 樹中我們需要進行 4 次磁盤的隨機 I/O 才能找到所有滿足條件的數據行: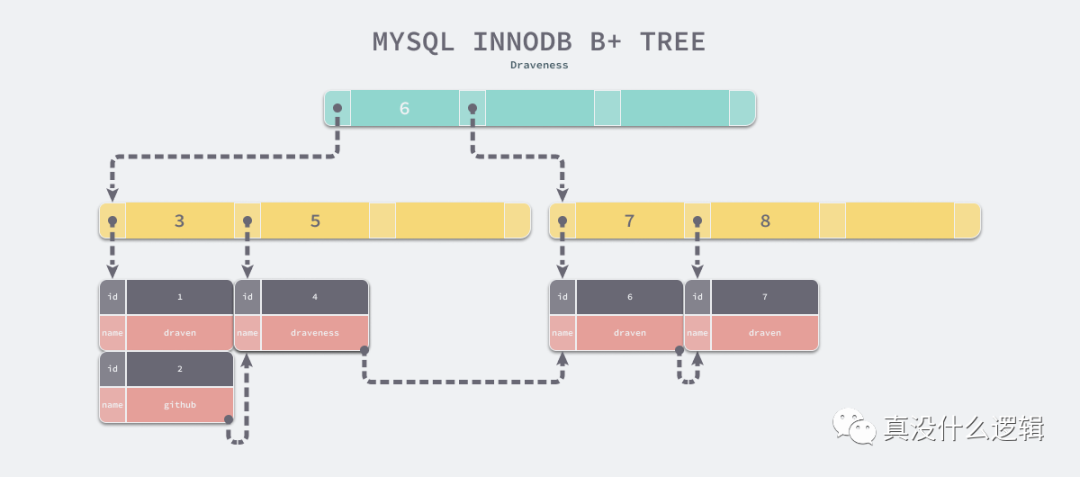 有些讀者可能會認為使用 B+ 樹這種數據結構會增加樹的高度從而增加整體的耗時,然而高度為 3 的 B+ 樹就能夠存儲千萬級別的數據,實踐中 B+ 樹的高度最多也就 4 或者 5,所以這并不是影響性能的根本問題。
有些讀者可能會認為使用 B+ 樹這種數據結構會增加樹的高度從而增加整體的耗時,然而高度為 3 的 B+ 樹就能夠存儲千萬級別的數據,實踐中 B+ 樹的高度最多也就 4 或者 5,所以這并不是影響性能的根本問題。O(1) 的單數據行操作性能,但是對于范圍查詢和排序卻無法很好地支持,最終導致全表掃描;hash和b+樹的區別,B+ tree · Wikipedia
What is the difference between Mysql InnoDB B+ tree index and hash index? Why does MongoDB use B-tree?
B+Trees and why I love them, part I
What are the main differences between INNODB and MYISAM
B+ Tree File Organization
hash索引和b+樹索引,Database Index: A Re-visit to B+ Tree
Fundamentals of database systems

點擊「」獲取面試題大全~
版权声明:本站所有资料均为网友推荐收集整理而来,仅供学习和研究交流使用。

工作时间:8:00-18:00
客服电话
电子邮件
admin@qq.com
扫码二维码
获取最新动态








![[转]Oracle修改监听口令](/upload/rand_pic/2-1377.jpg)