一、概述:
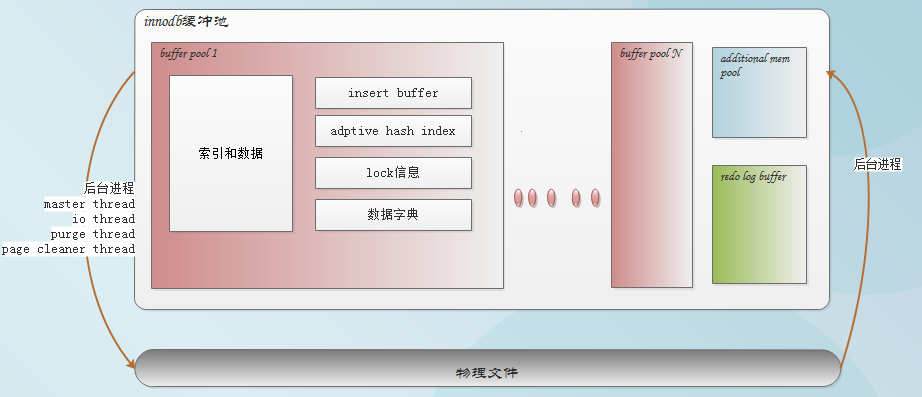
innodb的整個體系架構就是由多個內存塊組成的緩沖池及多個后臺線程構成。緩沖池緩存磁盤數據(解決cpu速度和磁盤速度的嚴重不匹配問題),后臺進程保證緩存池和磁盤數據的一致性(讀取、刷新),并保證數據異常宕機時能恢復到正常狀態。
緩沖池主要分為三個部分:redo?log buffer、innodb_buffer_pool、innodb_additional_mem_pool。
- innodb_buffer_pool由包含數據、索引、insert buffer ,adaptive hash index,lock 信息及數據字典。
- redo log buffer用來緩存重做日志。
- additional memory pool:用來緩存LRU鏈表、等待、鎖等數據結構。
innodb原理、 后臺進程分為:master thread,IO thread,purge thread,page cleaner thread。
- master thread負責刷新緩存數據到磁盤并協調調度其它后臺進程。
- IO thread 分為 insert buffer、log、read、write進程。分別用來處理insert buffer、重做日志、讀寫請求的IO回調。
- purge thread用來回收undo 頁
- page cleaner thread用來刷新臟頁。
master thread根據服務器的壓力分為了每一秒及每十秒的操作。每一秒的操作包括:刷新重做日志、根據過去一秒的磁盤吞吐量來判斷是否需要merge insert buffer、根據臟頁在緩沖池中占比是否超過最大臟頁占比及是否開啟自適應刷新來刷新臟頁。每十秒的操作包括:根據過去10秒的磁盤吞吐量來刷新臟頁,刷新重做日志,回收undo 頁,再根據臟頁占比是否超過70%刷新定量臟頁。
innodb整體的體系結構如下圖所示:
innodb引擎的三大特性、?
?二、innodb內部協調管理
一條SQL進入MySQL服務器,會依次經過連接池模塊(進行鑒權,生成線程),查詢緩存模塊(是否被緩存過),SQL接口模塊(簡單的語法校驗),查詢解析模塊,優化器模塊(生成語法樹),然后再進入innodb存儲引擎。進入innodb后,首先會判斷該SQL涉及到的頁是否存在于緩存中,如果不存在則從磁盤讀取相應索引及數據頁加載至緩存。如果是select語句,讀取數據(使用一致性非鎖定讀),并將查詢結果返回至服務器層。如果是DML語句,讀取到相關頁,先試圖給這個SQL涉及到的記錄加鎖。加鎖成功后,先寫undo 頁,邏輯地記錄這些記錄修改前的狀態。然后再修改相關記錄,這些操作會同步物理地記錄至redo log buffer。如果涉及及非唯一輔助索引的更新,還需要使用insert buffer。事務提交時,會啟用內部分布式事務,先將SQL語句記錄到binlog中,再根據系統設置刷新redo log buffer至redo log,保證binlog與redo log的一致性。提交后,事務會釋放對這些記錄所加的鎖,并將這些修改的記錄所在的頁放入innodb的flush list中,等待被page cleaner thread刷新到磁盤。這個事務產生的undo page如果沒有被其它事務引用(insert的undo page不會被其它事務引用),就會被放入history list中,等待被purge線程回收。
需要注意的是:
a.臟頁的刷新采用的是checkpoint機制
b.DML語句不同undo頁的格式也會不同。insert類型的undo log只記錄了主鍵及對應的主鍵值,而update、delete則記錄了主鍵及所有變更的字段值
c.一條設計不好的SQL,可能會導致大量的離散讀、加載很多冗余的數據頁至緩存中
innodb引擎的4大特性,以下為innodb內部各部分的協調管理簡圖:
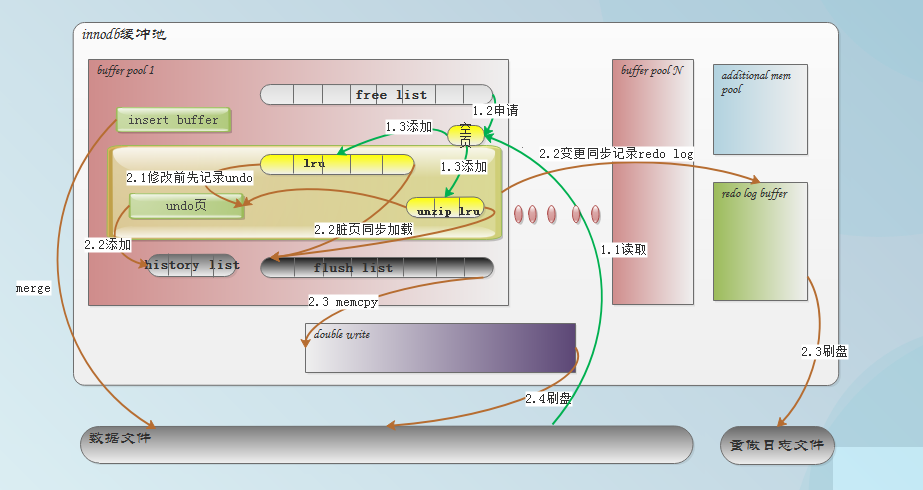
?
?
innodb底層數據結構。?
三、innodb內部關鍵技術
checkpoint:
如果我們有足夠大的內存且可以接受漫長的數據庫恢復時間的話,那我們沒有必要引入checkpoint機制。checkpoint通過標志redo log不可用,刷新緩存中的臟頁,解決內存容量瓶頸,縮短恢復時間。innodb會在四種情況下會觸發checkpoint:master thead的定時刷新、LRU列表中沒有足夠的空閑頁時(臟頁太多時)、redo log不可用時(async/sync flush checkpoint)及數據庫關閉時。checkpoint有兩種工作模式sharp checkpoint和 fuzzy checkpoint。一般情況下都是使用fuzzy checkpoint(刷新部分臟頁),只有數據庫關閉且設置了innodb_fast_shutdown=1時,才會使用sharp checkpoint(刷新所有臟頁回磁盤)。innodb系統日志會根據redo log的生命周期保存四個LSN號。分別是:當前系統LSN最大值、當前已經寫入日志文件的最大LSN號、已經刷新到磁盤的數據頁的最大LSN、已經寫入檢查點的LSN,后面的LSN值總是小于等于前面的LSN值。當數據庫宕機時,可以通過只恢復檢查點的LSN至已經寫入到日志文件的最大LSN之間的數據來恢復數據庫。需要注意的是當臟頁容量觸碰到低水位線時,調用async flush checkpoint異步刷新臟頁至磁盤,當臟頁容量觸碰到高水位線時會調用sync flush checkpoint 瘋狂刷新臟頁,磁盤會很忙,存在IO風暴。低水位線=75%total_redo_log_file_size 高水位線=90%total_redo_log_file_size
insert buffer:
專門為維護非唯一輔助索引的更新設計的。因為innodb的記錄是按主鍵的順序存放的,所以主鍵的插入是順序的,而聚集索引對應的輔助索引的更新則是離散的,為了避免大量離散讀寫,先檢查要更新的索引頁是否已經緩存在了內存中,如果沒有,先將輔助索引的更新都放入緩沖(inset buffer區),等待合適機會(master thread的定時操作,索引塊需要被讀取時,insert buffer bitmap檢測到對應的索引頁不夠用時)進行insert buffer和索引頁的合并。因為輔助索引緩存到insert buffer中時并不會讀取磁盤上的索引頁,以至于無法校驗索引的唯一性,所以不適用唯一輔助索引。innodb中所有的非唯一輔助索引的insert buffer均由同一棵二叉樹維護。二叉樹的非葉子節點由space(表空間id)+marker(兼容老版本的insert buffer)+offset(在表空間中的位置)構成,葉子節點由space+marker+offset+metadata(進入順序+類型+標志)+輔助索引構成,進行merge合并時,按順序進行回放。mysql5.1之后,insert buffer支持change_buffer,還可以緩沖非唯一輔助索引的update\delete操作。insert buffer的二叉樹結構是存放在共享表空間中的,所以通過獨立表空間恢復表時,執行check table操作會失敗,因為輔助索引的數據可能還在insert buffer中,需要通過repair table 重建表上全部的輔助索引。為了保證每次 merge insert buffer成功,表空間中每隔256個連續區就有一個insert buffer bitmap頁用來記錄索引頁的可用空間。insert buffer bitmap頁總是處于這個連續區間的第二頁,每個索引頁在insert buffer bitmap中占4 bit。可以通過show engine innodb stauts\G;查看insert buffer and adaptive hash index 查看insert buffer的合并數量、空閑頁數量、本身的大小、合并次數及索引操作次數。通過索引操作次數與合并次數的的比例可以判斷出insert buffer所帶來的性能提升。
double write:
因為臟頁刷新到磁盤的寫入單元小于單個頁的大小,如果在寫入過程中數據庫突然宕機,可能會使數據頁的寫入不完成,造成數據頁的損壞。而redo log中記錄的是對頁的物理操作,如果數據頁損壞了,通過redo log也無法進行恢復。所以為了保證數據頁的寫入安全,引入了double write。double write的實現分兩個部分,一個是緩沖池中2M的內存塊大小,一個是共享表空間中連續的128個頁,大小是2M。臟頁從flush list刷新時,并不是直接刷新到磁盤而是先調用函數(memcpy),將臟頁拷貝到double write buffer中,然后再分兩次,每次1M將double write buffer 刷新到磁盤double write 區,之后再調用fsync操作,同步到磁盤。如果應用在業務高峰期,innodb_dblwr_pages_written:innodb_dblwr_writes遠小于64:1,則說明,系統寫入壓力不大。雖然,double write buffer刷新到磁盤的時候是順序寫,但還是是有性能損耗的。如果系統本身支持頁的安全性保障(部分寫失效防范機制),如ZFS,那么就可以禁用掉該特性(skip_innodb_doublewrite)。
adaptive hash index:
innodb會對表上的索引頁的查詢進行監控,如果發現建立hash索引能夠帶來性能提升,就自動創建hash索引。hash索引的創建是有條件的,首先是必定能夠帶來性能提升。其次數據庫以特定模式的連續訪問超過了100次,通過該模式被訪問的頁的訪問次數超過了1/16的記錄行數。自適應hash根據B+樹中的索引構造而來,只需為這個表的熱點頁構造hash索引而不是為整張表都構建。同樣可以通過show engine innodb status\G中的 insert buffer and adaptive hash index(hash searches/s non-hash searches)查看hash index的使用情況。?
刷新鄰近頁:
innodb進行臟頁刷新時,會檢查該臟頁所在區內是否還存在其它臟頁,如果存在則一同刷新,通過AIO,進行IO合并,一定程度上減少了IO壓力。但是它也存在一個問題,就是把原本不怎么臟的頁也刷新到了磁盤。可能很快這個不怎么臟的頁又被讀取到緩沖中,又增加了IO的壓力。對于普通的機械盤開啟這個特性可以帶來很大的性能提升,但是如果是讀寫速度非常高的隨機盤,可以關閉這個特性(innodb_flush_neighbors=0)性能反而會更好。(因為對該特性的維護也是需要消耗性能的)
異步IO:
mysql 5.5之前并不支持異步IO,而是通過innodb代碼模擬實現。5.5之后開始提供AIO支持。數據庫可以連續發出IO請求,然后再等待IO請求的處理結果。異步IO帶來的好處就是可以進行IO合并操作,減少磁盤壓力。要想mysql支持異步IO還需要操作系統支持,首先操作系統必須支持異步IO,像windows,linux都是支持的,但是 mac osx卻不支持。同時在編譯和運行時還需要有libaio依賴包。可以通過設置innodb_use_native_aio來控制是否啟用這個特性,一般開啟這個特性可以使數據恢復帶來75%的性能提升。
事務:
innodb中一個邏輯事務包含一組物理事務。不管是物理事務還是邏輯事務,都需要滿足ACID特性(原子性,一致性,隔離性,及持久性)。如果一個邏輯事務需要操作多個頁,那么它對每個頁的操作會以一個物理事務來進行。物理事務對頁進行處理時,先根據頁的space_id,page_no找到對應的頁,再試圖對該頁加鎖。如果申請加的鎖和該頁原本已經加上的鎖沖突,則進入等待狀態。否則直接加鎖,并將該頁加入到memo動態數組中,之后物理事務就可以訪問這個頁了。如果對該頁進行的是變更操作,那么針對這些操作就會在local buffer中產生redo log record記錄。當物理事務提交時,會在redo log record后追加一串結束標志日志來保證物理事務的完整性。物理事務提交后,redo log record會被提交到redo log buffer的塊中,一個塊的大小是512字節,一個redo log record可能會出現在多個塊中,這取決于redo log record的長度(每個塊開始的兩個字節記錄的是第一個mtr在該段中開始的位置,如果是0,則表明還是上一個block的同一個mtr)。同時被分配到一個LSN號,LSN號確定了它在redo log中的位置,這個LSN號也將會被寫入到物理事務操作的頁的頁頭中。物理事務提交后,會檢查memo數組中的這些頁是否被修改,若修改了則將其加入到innodb的flush list中。flush list中只能存放一個關于這個頁的記錄。如果頁沒有被修改,則直接釋放加在它上面的鎖。當邏輯事務提交時,會將redo log buffer以塊為單位順序刷新到redo log中。多個邏輯事務并發時,可能會出現多個邏輯事務的物理事務交叉記錄在redo log buffer中。也會出現未提交的邏輯事務的部分物理事務日志持久化在redo log中。但這并不會造成日志重做的時候,重做未提交的邏輯事務。原因是,雖然重做的時候是以物理事務為單位進行重做,但它會判斷該物理事務所在的邏輯事務包含的所有物理事務是否完整,如果不完整,那么該邏輯事務所涉及的所有物理事務都不會重做。物理事務的工作過程,可以很好的解釋一個邏輯事務在執行的過程中是在不斷地寫redo日志,而且不斷地往flush list中加塞臟頁的。
innodb還支持內外部分布式事務。分布式事務的實現是:應用通過一個事務管理器實現對多個相同或不同的數據庫實例的事務管理。分布式事務與本地事務的區別是多了一個prepare的階段,待收到所有節點的同意信息后再commit或rollback。內部分布式事務最常見的是binlog和innodb存儲引擎之間。事務提交時會先寫binlog再寫redo log,因為有內部分布式事務,在寫完binlog宕機的情況下,mysql再重啟會先檢查準備的uxid事務是否已經提交,若沒有則存儲引擎層再做一次提交。
MVCC:
多版本并發控制,mysql僅在RC,RR隔離級別下支持MVCC。主要是結合undo log來實現的一個數據的多個版本,保證讀不會堵塞寫,寫也不會堵塞讀來提高并發。mvcc下,select操作默認是一致性非鎖定讀,除非顯式給select加in share或for update鎖,才會使用一致性鎖定讀。
多隔離級別:
innodb支持四種隔離級別RU\RC\RR\serializable。RU不使用MVCC,讀取的時候也不加鎖。RC利用MVCC都是讀取記錄最新的版本,RR利用MVCC總是讀取記錄最舊的版本,并通過next-key locking來避免幻讀,serializable不使用MVCC,讀取記錄的時候加共享鎖,堵塞了其它事務對該記錄的更新,實現可串行化。隔離級別越高,維護成本越高,并發越低。RC隔離級別下要求二進制日志格式必須是row格式的,因為RC隔離級別下,不會加gap鎖,不能禁止一個事務在執行的過程中另一個事務對它的間隙進行操作的情況。這種情況下,對于事務開始的和提交的順序是先更改后提交,后更改先提交的情況,statement格式的binlog只會是按照事務提交的順序進行記錄。這可能會導致復制環境的slave數據和master數據不一致。通過設置innodb_locks_unsafe_for_binlog=1也可以使用statement格式,但是主從數據的一致性沒法保證。
?
轉自:https://www.cnblogs.com/janehoo/p/7717041.html