首页
语法
变量
函数
技术动态
基础知识库
首页
/
spark的job调度流程
spark job生成的时间驱动
JobGenerator中有一个timer成员,根据配置中的时间间隔不断产生GenerateJobs事件来触发job的产生,以成为job产生的起点。Timer通过clock来作为构建时间的依据。oracle定时执行sql、 val clock = {val clockClass = ssc.sc.conf.get("spark.streaming
时间:2023-09-15 | 阅读:13
spark job运行参数优化
一、问题 使用spark join两张表(5000w*500w)总是出错,报的异常显示是在shuffle阶段。 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 14/11/2712:05:49ERROR storage.DiskBlockObjectWriter: Uncaught exceptionwhilereverting partial writes to f
时间:2023-09-05 | 阅读:61
阅读排行
2730℃
1
如何防止应用程序泄密?
2728℃
2
AlertDialog禁止返回键
2547℃
3
linux中MySQL密码的恢复方...
2387℃
4
node.js当中net模块的简单...
2236℃
5
我的高质量软件发布心得
2168℃
6
从源码角度看Spark on yar...
2022℃
7
在linux云服务器上运行Jar...
1587℃
8
codevs1521 华丽的吊灯
猜你喜欢
枚举项的数量限制在64个以内
干货篇:创业对待数据挖掘要注意这5点
分布式系统一致性协议--Paxos算法
centos7不中断执行命令
jQuery Mobile中jQuery.mobile.changePage方法使用详解
九、Citrix服务器虚拟化Xenserver虚拟机模版
《产品设计与开发(原书第5版)》——3.8 步骤5:选出最佳机会方案
[20170508]listagg拼接显示字段.txt
生产环境究竟是使用mysqldump还是xtrabackup来备份与恢复数据库?
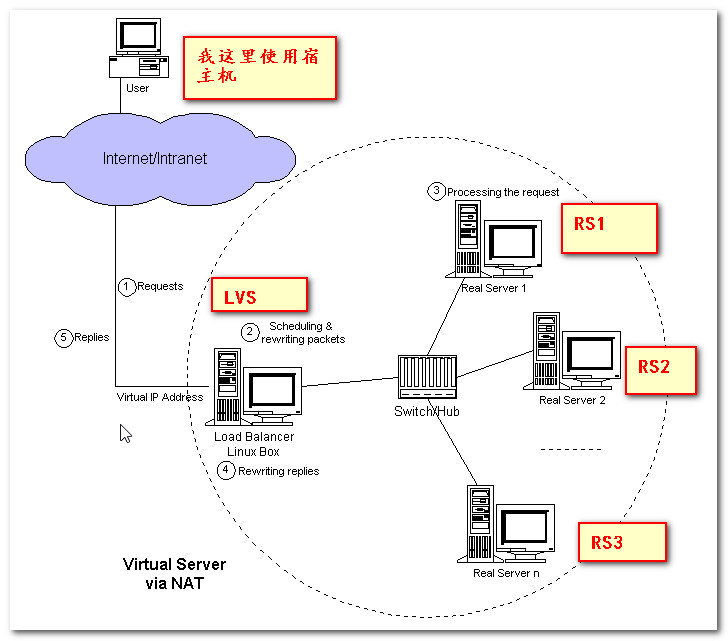
LINUX负载均衡LVS-NAT搭建
layer.open组件获取弹出层页面变量、函数
appium入门文档
热门标签
python3
Spring boot
python有什么用
python和java
java
Springboot教程
python编程
Leetcode
python爬蟲教程
python菜鳥教程
Springboot注解
Mybatis
Springboot框架
Springboot
UNIXLINUX
SpringBootApplication
python为什么叫爬虫
qpython
我要关灯
我要开灯
客户电话
工作时间:8:00-18:00
客服电话
电子邮件
admin@qq.com
官方微信
扫码二维码
获取最新动态
返回顶部









![[20170508]listagg拼接显示字段.txt](/upload/rand_pic/2-429.jpg)