首页
语法
变量
函数
技术动态
基础知识库
首页
/
用python爬取網站數據
python爬蟲爬取網頁表格數據,python 錄制網易云登陸_Python爬蟲教程,爬取網易云的音樂
在開始之前,做一點小小的說明哈:我只是一個python爬蟲愛好者,如果本文有侵權,請聯系我刪除!本文需要有簡單的python爬蟲基礎,主要用到兩個爬蟲模塊(都是常規的)requests模塊selenium模塊建議使用谷歌瀏覽器,方便進行抓包和數
时间:2023-12-10 | 阅读:38
python爬取網頁詳細教程,python爬蟲知識點總結(三)urllib庫詳解
一、什么是Urllib? 官方學習文檔:https://docs.python.org/3/library/urllib.html python爬取網頁詳細教程,廖雪峰的網站:https://www.liaoxuefeng.com/wiki/0014316089557264a6b348958f449949df42a6d3a2e542c000/001432002680493d1babda364904ca0a6e28
时间:2023-12-06 | 阅读:40
如何用python抓取網頁上的數據,python爬取flash數據_爬取flash數據
關于html爬取數據的文章已經有很多了,我今天主要和大家交流的是如何爬取flash網頁的數據。這方面資料相對比較少,主要是html5興起后現在flash站很少了,不過用于技術研究還是可以嘗試一下,這篇文章就主要介紹我爬取數據的整個過程。以房產透明網為
时间:2023-12-06 | 阅读:30
學python對考研有用嗎,python爬考研_用Python爬取了考研吧1000條帖子,原來他們都在討論這些!
寫在前面 考研在即,想多了解考研er的想法,就是去找學長學姐或者去網上搜索,貼吧就是一個好地方。而借助強大的工具可以快速從網絡魚龍混雜的信息中得到有價值的信息。雖然網上有很多爬取百度貼吧的教程和例子,但是貼吧規則更新快,目的不一
时间:2023-11-30 | 阅读:28
爬蟲爬取數據,python 爬取了租房數據
? 爬蟲爬取數據?爬取鏈接:https://sh.lianjia.com/zufang/ 代碼如下: import requests # 用于解析html數據的框架 from bs4 import BeautifulSoup # 用于操作excel的框架 from xlwt import * import json# 創建一個工作 book = Workbook(encoding='utf-8&
时间:2023-11-23 | 阅读:30
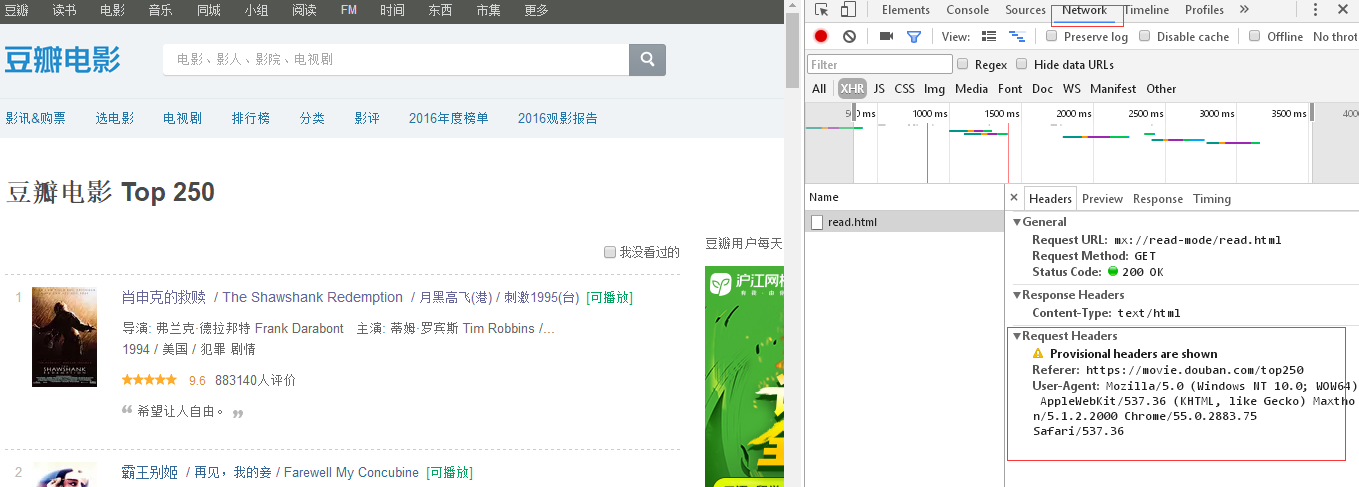
python爬蟲有什么用,python爬蟲--爬取豆瓣top250電影名
關于模擬瀏覽器登錄的header,可以在相應網站按F12調取出編輯器,點擊netwook,如下: 以便于不會被網站反爬蟲拒絕。 ? 1 import requests 2 from bs4 import BeautifulSoup 5 def get_movies(): 6 headers = { 7 'user-agent': 'M
时间:2023-11-19 | 阅读:26
爬蟲python的爬取步驟,python爬取天氣預報并發送短信_Python3爬蟲教程之利用Python實現發送天氣預報郵件...
前言此次的目標是爬取指定城市的天氣預報信息,然后再用Python發送郵件到指定的郵箱。下面話不多說了,來一起看看詳細的實現過程吧一、爬取天氣預報爬蟲python的爬取步驟、1、首先是爬取天氣預報的信息,用的網站是中國天氣網,網址是http://www.wea
时间:2023-11-18 | 阅读:27
python系列課程,免費python課程排行榜-用python爬取2017年中國最好大學排名
爬取2017年中國最好大學排名 在學習中國大學慕課網的python網絡爬蟲與信息提取時,有這么一道題,要求我們爬取2016年的中國最好大學排名鏈接在這,按照題目要求很快便可以爬取到我需要的排名順序。代碼如下 import requests from bs4 import BeautifulSoup
时间:2023-11-18 | 阅读:27
python字典api,python有道-Python爬取有道詞典
from urllib import request,parse import hashlib import random import time python字典api。import json #定義md5加密函數 def getMD5(value): aa = hashlib.md5() aa.update(bytes(value,encoding="utf-8")) python爬蟲教程,sign = aa.hexdigest()
时间:2023-11-18 | 阅读:27
python json,python requests網頁爬取初探
python開發過程中,有時候需要網頁的數據,這時用到網頁爬蟲模塊,減少重復性工作,python提供了requests 模塊,urllib2模塊,beautifulsoup bs4模塊。 軟件開發中能夠用腳本代替的工作盡量用腳本代替,我們專注于業務本身就好。
时间:2023-11-12 | 阅读:28
1
2
3
4
»
阅读排行
2750℃
1
如何防止应用程序泄密?
2745℃
2
AlertDialog禁止返回键
2564℃
3
linux中MySQL密码的恢复方...
2501℃
4
node.js当中net模块的简单...
2252℃
5
我的高质量软件发布心得
2183℃
6
从源码角度看Spark on yar...
2033℃
7
在linux云服务器上运行Jar...
1608℃
8
codevs1521 华丽的吊灯
猜你喜欢
配置如下
IDEA远程调试Tomcat
下一步:
打开资源管理器属性窗口,点击左侧的高级系统设置。
win10配置gcc编译环境
input上报流程分析【转】
Git 相关使用命令
ubuntu修改默认系统启动项
关于JS中for循环时,作用域问题和this指针指向的总结
asp.net core 教程(六)-中间件
28-hadoop-hbase入门小程序
java里的多线程同步机制
Codeforces D - High Load
(转)使用异步Python 3.6和Redis编写快速应用程序
python 统计单词个数---从文件读取版本---不去重
热门标签
python3
Spring boot
python有什么用
python和java
java
Springboot教程
python编程
Leetcode
python爬蟲教程
python菜鳥教程
Springboot注解
Mybatis
Springboot框架
Springboot
UNIXLINUX
SpringBootApplication
python为什么叫爬虫
qpython
我要关灯
我要开灯
客户电话
工作时间:8:00-18:00
客服电话
电子邮件
admin@qq.com
官方微信
扫码二维码
获取最新动态
返回顶部