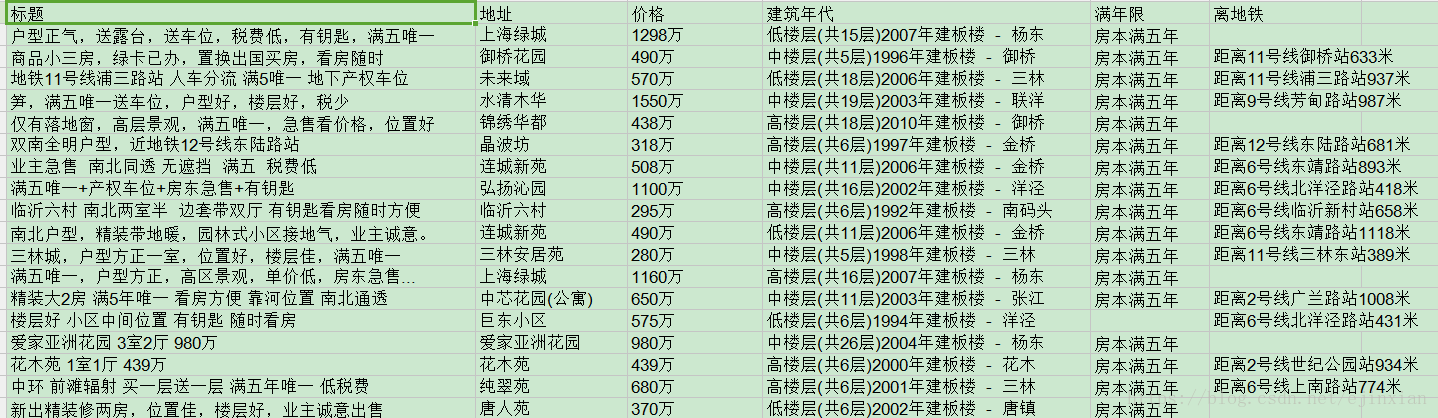
?
爬蟲爬取數據?爬取鏈接:https://sh.lianjia.com/zufang/
代碼如下:
import requests
# 用于解析html數據的框架
from bs4 import BeautifulSoup
# 用于操作excel的框架
from xlwt import *
import json# 創建一個工作
book = Workbook(encoding='utf-8');
# 向表格中增加一個sheet表,sheet1為表格名稱 允許單元格覆蓋
sheet = book.add_sheet('sheet1', cell_overwrite_ok=True)
# 設置樣式
style = XFStyle();
pattern = Pattern();
pattern.pattern = Pattern.SOLID_PATTERN;
pattern.pattern_fore_colour="0x00";
style.pattern = pattern;
# 設置列標題
sheet.write(0, 0, "標題")
sheet.write(0, 1, "地址")
sheet.write(0, 2, "價格")
sheet.write(0, 3, "建筑年代")
sheet.write(0, 4, "滿年限")
sheet.write(0, 5, "離地鐵")# 設置列寬度
sheet.col(0).width = 0x0d00 + 200*50
sheet.col(1).width = 0x0d00 + 20*50
sheet.col(2).width = 0x0d00 + 10*50
sheet.col(3).width = 0x0d00 + 120*50
sheet.col(4).width = 0x0d00 + 1*50
sheet.col(5).width = 0x0d00 + 50*50# 指定爬蟲所需的上海各個區域名稱
citys = ['pudong', 'minhang', 'baoshan', 'xuhui', 'putuo', 'yangpu', 'changning', 'songjiang','jiading', 'huangpu', 'jinan', 'zhabei', 'hongkou', 'qingpu', 'fengxian', 'jinshan', 'chongming','shanghaizhoubian']def getHtml(city):url = 'http://sh.lianjia.com/ershoufang/%s/' % cityheaders = {'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36'}request = requests.get(url=url, headers=headers)# 獲取源碼內容比request.text好,對編碼方式優化好respons = request.content# 使用bs4模塊,對響應的鏈接源代碼進行html解析,后面是python內嵌的解釋器,也可以安裝使用lxml解析器soup = BeautifulSoup(respons, 'html.parser')# 獲取類名為c-pagination的div標簽,是一個列表pageDiv = soup.select('div .page-box')[0]pageData =dict(pageDiv.contents[0].attrs)['page-data'];pageDataObj =json.loads(pageData);totalPage =pageDataObj['totalPage']curPage =pageDataObj['curPage'];print(pageData);# 如果標簽a標簽數大于1,說明多頁,取出最后的一個頁碼,也就是總頁數for i in range(totalPage):pageIndex=i+1;print(city+"=========================================第 " + str(pageIndex) + " 頁")print("\n")saveData(city, url, pageIndex);# 調用方法解析每頁數據,并且保存到表格中
def saveData(city, url, pageIndex):headers = {'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36'}urlStr ='%spg%s' % (url, pageIndex);print(urlStr);html = requests.get(urlStr, headers=headers).content;soup = BeautifulSoup(html, 'lxml')liList = soup.findAll("li", {"class": "clear LOGCLICKDATA"})print(len(liList));index=0;for info in liList:title =info.find("div",class_="title").find("a").text;address =info.find("div",class_="address").find("a").textflood = info.find("div", class_="flood").textsubway = info.find("div", class_="tag").findAll("span", {"class", "subway"});subway_col="";if len(subway) > 0:subway_col = subway[0].text;taxfree = info.find("div", class_="tag").findAll("span", {"class", "taxfree"});taxfree_col="";if len(taxfree) > 0:taxfree_col = taxfree[0].text;priceInfo =info.find("div",class_="priceInfo").find("div",class_="totalPrice").text;print(flood);global rowsheet.write(row, 0, title)sheet.write(row, 1, address)sheet.write(row, 2, priceInfo)sheet.write(row, 3, flood)sheet.write(row, 4,taxfree_col)sheet.write(row, 5,subway_col)row+=1;index=row;# 判斷當前運行的腳本是否是該腳本,如果是則執行
# 如果有文件xxx繼承該文件或導入該文件,那么運行xxx腳本的時候,這段代碼將不會執行
if __name__ == '__main__':# getHtml('jinshan')row=1for i in citys:getHtml(i)# 最后執行完了保存表格,參數為要保存的路徑和文件名,如果不寫路徑則默然當前路徑book.save('lianjia-shanghai.xls')python爬蟲教程?如下圖:
思路是:
post 代碼之前,先簡單講一下這里用到的幾個爬蟲 Python 包:
代碼如下:
import requests
import time
import re
from lxml import etree # 獲取某市區域的所有鏈接
def get_areas(url): print('start grabing areas') headers = { 'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.108 Safari/537.36'} resposne = requests.get(url, headers=headers) content = etree.HTML(resposne.text) areas = content.xpath("//dd[@data-index = '0']//div[@class='option-list']/a/text()") areas_link = content.xpath("//dd[@data-index = '0']//div[@class='option-list']/a/@href") for i in range(1,len(areas)): area = areas[i] area_link = areas_link[i] link = 'https://bj.lianjia.com' + area_link print("開始抓取頁面") get_pages(area, link) #通過獲取某一區域的頁數,來拼接某一頁的鏈接
def get_pages(area,area_link): headers = { 'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.108 Safari/537.36'} resposne = requests.get(area_link, headers=headers) pages = int(re.findall("page-data=\'{\"totalPage\":(\d+),\"curPage\"", resposne.text)[0]) print("這個區域有" + str(pages) + "頁") for page in range(1,pages+1): url = 'https://bj.lianjia.com/zufang/dongcheng/pg' + str(page) print("開始抓取" + str(page) +"的信息") get_house_info(area,url) #獲取某一區域某一頁的詳細房租信息
def get_house_info(area, url): headers = { 'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.108 Safari/537.36'} time.sleep(2) try: resposne = requests.get(url, headers=headers) content = etree.HTML(resposne.text) info=[] for i in range(30): title = content.xpath("//div[@class='where']/a/span/text()")[i] room_type = content.xpath("//div[@class='where']/span[1]/span/text()")[i] square = re.findall("(\d+)",content.xpath("//div[@class='where']/span[2]/text()")[i])[0] position = content.xpath("//div[@class='where']/span[3]/text()")[i].replace(" ", "") try: detail_place = re.findall("([\u4E00-\u9FA5]+)租房", content.xpath("//div[@class='other']/div/a/text()")[i])[0] except Exception as e: detail_place = "" floor =re.findall("([\u4E00-\u9FA5]+)\(", content.xpath("//div[@class='other']/div/text()[1]")[i])[0] total_floor = re.findall("(\d+)",content.xpath("//div[@class='other']/div/text()[1]")[i])[0] try: house_year = re.findall("(\d+)",content.xpath("//div[@class='other']/div/text()[2]")[i])[0] except Exception as e: house_year = "" price = content.xpath("//div[@class='col-3']/div/span/text()")[i] with open('鏈家北京租房.txt','a',encoding='utf-8') as f: f.write(area + ',' + title + ',' + room_type + ',' + square + ',' +position+
','+ detail_place+','+floor+','+total_floor+','+price+','+house_year+'\n') print('writing work has done!continue the next page') except Exception as e: print( 'ooops! connecting error, retrying.....') time.sleep(20) return get_house_info(area, url) def main(): print('start!') url = 'https://bj.lianjia.com/zufang' get_areas(url) if __name__ == '__main__': main() ?
由于每個樓盤戶型差別較大,區域位置比較分散,每個樓盤具體情況還需具體分析
代碼:
#北京路段_房屋均價分布圖 detail_place = df.groupby(['detail_place']) house_com = detail_place['price'].agg(['mean','count']) house_com.reset_index(inplace=True) detail_place_main = house_com.sort_values('count',ascending=False)[0:20] attr = detail_place_main['detail_place'] v1 = detail_place_main['count'] v2 = detail_place_main['mean'] line = Line("北京主要路段房租均價") line.add("路段",attr,v2,is_stack=True,xaxis_rotate=30,yaxix_min=4.2, mark_point=['min','max'],xaxis_interval=0,line_color='lightblue', line_width=4,mark_point_textcolor='black',mark_point_color='lightblue', is_splitline_show=False) bar = Bar("北京主要路段房屋數量") bar.add("路段",attr,v1,is_stack=True,xaxis_rotate=30,yaxix_min=4.2, xaxis_interval=0,is_splitline_show=False) overlap = Overlap() overlap.add(bar) overlap.add(line,yaxis_index=1,is_add_yaxis=True) overlap.render('北京路段_房屋均價分布圖.html') 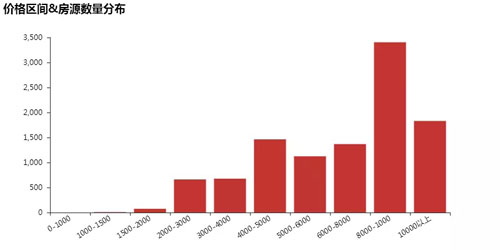
面積&租金分布呈階梯性
#房源價格區間分布圖
price_info = df[['area', 'price']] #對價格分區
bins = [0,1000,1500,2000,2500,3000,4000,5000,6000,8000,10000]
level = ['0-1000','1000-1500', '1500-2000', '2000-3000', '3000-4000', '4000-5000', '5000-6000', '6000-8000', '8000-1000','10000以上']
price_stage = pd.cut(price_info['price'], bins = bins,labels = level).value_counts().sort_index() attr = price_stage.index
v1 = price_stage.values bar = Bar("價格區間&房源數量分布")
bar.add("",attr,v1,is_stack=True,xaxis_rotate=30,yaxix_min=4.2, xaxis_interval=0,is_splitline_show=False) overlap = Overlap()
overlap.add(bar)
overlap.render('價格區間&房源數量分布.html') 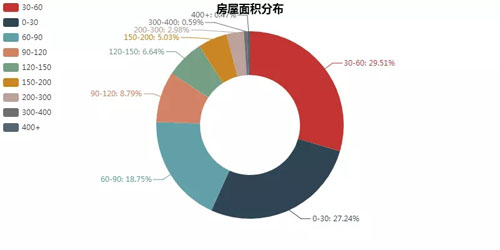
#房屋面積分布
bins =[0,30,60,90,120,150,200,300,400,700]
level = ['0-30', '30-60', '60-90', '90-120', '120-150', '150-200', '200-300','300-400','400+']
df['square_level'] = pd.cut(df['square'],bins = bins,labels = level) df_digit= df[['area', 'room_type', 'square', 'position', 'total_floor', 'floor', 'house_year', 'price', 'square_level']]
s = df_digit['square_level'].value_counts() attr = s.index
v1 = s.values pie = Pie("房屋面積分布",title_pos='center') pie.add( "", attr, v1, radius=[40, 75], label_text_color=None, is_label_show=True, legend_orient="vertical", legend_pos="left",
) overlap = Overlap()
overlap.add(pie)
overlap.render('房屋面積分布.html') #房屋面積&價位分布
bins =[0,30,60,90,120,150,200,300,400,700]
level = ['0-30', '30-60', '60-90', '90-120', '120-150', '150-200', '200-300','300-400','400+']
df['square_level'] = pd.cut(df['square'],bins = bins,labels = level) df_digit= df[['area', 'room_type', 'square', 'position', 'total_floor', 'floor', 'house_year', 'price', 'square_level']] square = df_digit[['square_level','price']]
prices = square.groupby('square_level').mean().reset_index()
amount = square.groupby('square_level').count().reset_index() attr = prices['square_level']
v1 = prices['price'] pie = Bar("房屋面積&價位分布布")
pie.add("", attr, v1, is_label_show=True)
pie.render()
bar = Bar("房屋面積&價位分布")
bar.add("",attr,v1,is_stack=True,xaxis_rotate=30,yaxix_min=4.2, xaxis_interval=0,is_splitline_show=False) overlap = Overlap()
overlap.add(bar)
overlap.render('房屋面積&價位分布.html') 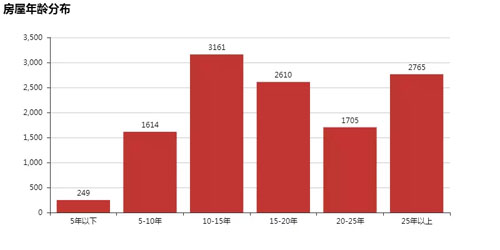
?
?
?
?
?
?
?
?
摘錄:爬取了上萬條租房數據,你還要不要北漂
?
版权声明:本站所有资料均为网友推荐收集整理而来,仅供学习和研究交流使用。

工作时间:8:00-18:00
客服电话
电子邮件
admin@qq.com
扫码二维码
获取最新动态