首页
语法
变量
函数
技术动态
基础知识库
首页
/
beautifulsoup干嘛的
html文件怎么保存链接,如何使用beautifulsoup将链接的html保存在文件中,并对html文件中的所有链接执行相同的操作...
我明白了。 使用美丽的汤递归URL解析的代码:import requestsimport urllib2怎么将网页以html保存到文件夹中。from bs4 import BeautifulSouplink_set = set()give_url = raw_input("Enter url:\t")def magic(give_url, link_set, count):html文件怎么
时间:2023-09-16 | 阅读:25
Python爬虫_BeauifulSoup
文章目录简介BeautifulSoup的使用对象种类遍历文档树搜索文档树CSS选择器 简介 BeautifulSoup是一个可以从HTML或XML文件中提取数据的Python库,他能够通过你喜欢的转换器实现惯用的文档导航、查找、修改文档的方式。 安装BeautifulSoup、lxml pip install beautifulso
时间:2023-09-10 | 阅读:22
python三方库之BeautifuSoup
html文档解析的三方库beautifulsoup4 什么是beautifulsoup? 学习资源:https://www.crummy.com/software/BeautifulSoup/bs4/doc/index.zh.html 1.安装 pip install beautifulsoup4 2.使用 至少要对html有一定的了解。 from bs4 import BeautifulSoup 举例:获取一
时间:2023-09-06 | 阅读:22
python怎么安装beautifulsoup,python – 安装BeautifulSoup
我在我的ubuntu 10.04上运行python 3.1.2我需要安装哪个版本的BeautifulSoup以及如何安装?我已经下载了3.2版并运行sudo python3 setup.py install但不起作用日Thnx编辑:我得到的错误是:>>> import BeautifulSoupTraceback (most recent call l
时间:2023-09-06 | 阅读:21
阅读排行
2746℃
1
如何防止应用程序泄密?
2740℃
2
AlertDialog禁止返回键
2560℃
3
linux中MySQL密码的恢复方...
2396℃
4
node.js当中net模块的简单...
2248℃
5
我的高质量软件发布心得
2179℃
6
从源码角度看Spark on yar...
2028℃
7
在linux云服务器上运行Jar...
1600℃
8
codevs1521 华丽的吊灯
猜你喜欢
阿里云获工信部CDN业务经营许可 云计算业内资质最全
SQL Server之 (四) ADO增删查改 登录demo 带参数的sql语句 插入自动返回行号
Anaconda 安装 ml_metrics package
二进制安装mysql5.7
在linux云服务器上运行Jar文件
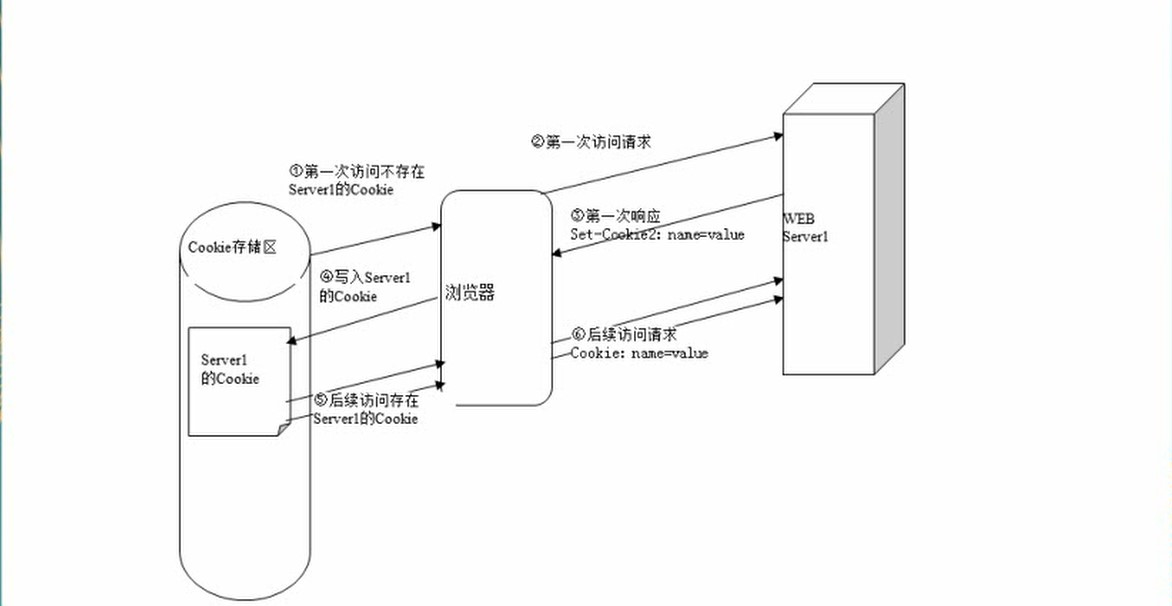
Cookie知识点总结
通过安装扩展让 KDE Plasma 5 桌面看起来感觉就像 Windows 10 桌面
应用场景不止于联接,新华三发布智能门户系统iPortal
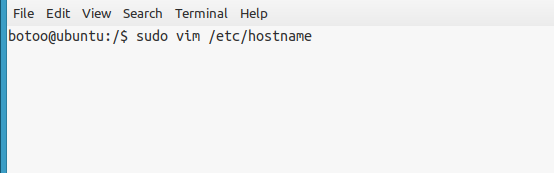
linux===Ubuntu修改设备名称
html简单跨行跨列表格制作
《佛学概论》笔记
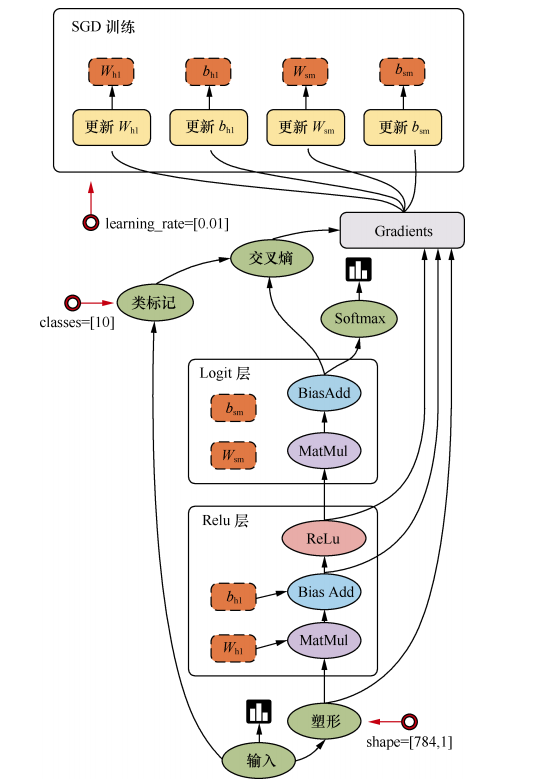
Tensorflow 相关概念
热门标签
python3
Spring boot
python有什么用
python和java
java
Springboot教程
python编程
Leetcode
python爬蟲教程
python菜鳥教程
Springboot注解
Mybatis
Springboot框架
Springboot
UNIXLINUX
SpringBootApplication
python为什么叫爬虫
qpython
我要关灯
我要开灯
客户电话
工作时间:8:00-18:00
客服电话
电子邮件
admin@qq.com
官方微信
扫码二维码
获取最新动态
返回顶部