下面來簡單介紹一下各個主要文件的作用:
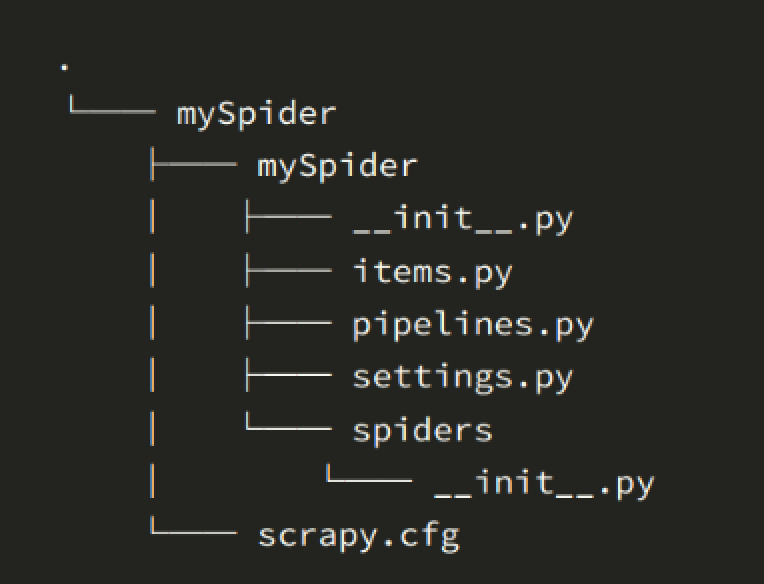
scrapy.cfg :項目的配置文件 mySpider/ :項目的Python模塊,將會從這里引用代碼 bootstrap案例?mySpider/items.py :項目的目標文件 mySpi" alt="bootstrap案例,scrapy框架系列 (2) 一個簡單案例">
scrapy.cfg :項目的配置文件
mySpider/ :項目的Python模塊,將會從這里引用代碼
bootstrap案例?mySpider/items.py :項目的目標文件
mySpi" alt="bootstrap案例,scrapy框架系列 (2) 一個簡單案例">
工作时间:8:00-18:00
客服电话
电子邮件
admin@qq.com
扫码二维码
获取最新动态