Key-Value存储作为NoSQL存储的一种常见方式,提供了比SQL数据库更好的可扩展性和读写性能。
比方当前开源最热门的Memcached和Redis;淘宝的Tair、腾讯的Cmem、
Amazon的Dynamo等等,不管是做缓存还是持久存储,均使用内存作为主要存储介质,故内存管理策略就显得尤为重要了,是影响性能的重要因素。 这里从源码层面对Memcached、Redis和UDC(腾讯曾经用的一套KV持久化存储系统)的内存管理策略进行分析。3者的内存管理策略各不同样,其它KV系统也和这3种方法大同小异了。最后对这3种策略进行了实际的性能測试分析,有出入的请使劲拍砖!
--------------------------------------------------------------------------
1 MemCached:Slab Allocation机制
3个基本的概念:
1 Chunk块:固定大小的数据块,数据存储的基本单位。1个Chunk块存1个数据,剩余空间不做其它用途
2 Slab页:固定大小的内存块(页),申请内存的基本单位,默觉得1MB,每一个SlabClass会把申请的Slab切分成同样大小Chunk来存数据 3 SlabClass:由Chunk的大小确定,是大小同样的全部Chunk块集合

如上图所看到的,Memcahed启动时。会依据传入的-n(最小数据尺寸,默认48B),-f(增长因子,默觉得1.25)启动选项初始化SlabClass。默认情况下,首个SlabClass的Chunk大小为80B(32B元数据头+48B最小数据尺寸),然后以1.25为比值生成等比数列,直到1MB(1个Slab页大小)为止。
生成的SlabClass例如以下所看到的(perslab值为每一个
Slab页能切割出的Chunk个数):$ memcached -vv
slab class 1: chunk size 80 perslab 13107
slab class 2: chunk size 104 perslab 10082
slab class 3: chunk size 136 perslab 7710
.....
slab class 41: chunk size 717184 perslab 1
slab class 42: chunk size 1048576 perslab 1
当用户发来请求时。Memcahed会根据key+value的值(能存放在1个Chunk内)来推断属于哪个SlabClass。
确定这个
SlabClass有无空暇的Chunk块,没有的话则先给这个SlabClass申请一个Slab页,将该Slab页按本SlabClass的Chunk块大小进行分割,然后分配1个来存放用户数据。(这里还有LRU算法淘汰旧数据的逻辑。就不放在这里分析)。
这样的策略的特点:
- 实现较复杂
- 參数的选择(最小数据尺寸,增长因子)直接影响性能及内存利用率
- 每一个数据存放于1个Chunk块。读写简单
相关源码:主要由slab.h/c(SlabClass和Slab相关)、item.h/c(Chunk块相关)这几个文件实现
* SlabClass数据结构:

* 初始化SlabClass(通过增长因子计算各个SlabClass的Chunk块大小等)

* 为SlabClass[i]申请一块新Slab内存页

---------------------------------------------------------------------------
2 Redis:简单mallc/free封装
相比Memcached。Redis做了一些优化。包含支持数据持久化(AOF和RDB两种持久化方式),支持主从复制读写分离,支持更丰富的数据结构(string、hash、set、list等)。
然而在内存管理方面,相比于Memcached的Slab Allocation机制。Redis的实现就显得简单粗暴得多了。就仅仅是mallc/free的简单封装(屏蔽底层差异,加入相关元数据等)。
这样的策略的特点:
- 简单易实现,不易出错
- 内存的利用率高
- 大量系统调用开销大
- 导致内存碎片。加重操作系统内存管理器负担
相关源码:由zmalloc.h/c这两个文件实现,相对简单
* 申请内存

* 释放内存

---------------------------------------------------------------------------
3 UDC:切分Shm成固定长度的块,组织空暇块链和用户数据块链
UDC是腾讯曾经用的一套基于Shm的、全Cache的键值存储系统。和MemCached或Redis使用进程堆内存不一样,UDC使用共享内存来存储数据,一方面进程Core的时候数据还在,一方面利于其它进程做数据落地、同步等操作。

如上图所看到的,UDC启动时会申请一块大Shm(LinkTable),然后将这块Shm切割成固定长度的Chunk块(默认200B)。通过下标组织成一条空暇块链。当收到加入数据的请求时,从空暇块链中不断取出空暇块存放用户数据,直到存放完毕形成一条用户数据块链。链头下标存放于索引层中(基于Shm的多阶Hash)。当收到删除数据的请求时。直接将相应的用户数据块链清零,插入空暇块链中就可以。
这样的策略的特点:
- 实现较复杂
- 代码不健壮有写乱Shm块链的风险
- Shm数据块大小的选择直接影响性能及内存利用率
- 用户数据块链组织成用户数据需多一次拷贝影响性能
相关源码:主要由hash_cache.h/c这2个文件实现
* 初始化LinkTable

* Set()操作,加入用户数据

* Get()操作,获取用户数据

---------------------------------------------------------------------------
性能測试:
实验前提:
* 机器:Intel(R) Xeon(R) CPU X3440 @2.53GHz (单线程。这里仅仅用到1核),8G内存
* key为uint32_t,值为 [1, 50w] 的随机数
* value为string,串长度为 [50, 500] 之间的随机字节数
1 不同块大小选择对UDC性能的影响:
实验方案:
* 对不同的块大小,进行1000w次读+写操作(即每次1个Set加1个Get)。计算总耗时和内存利用率
* 开足够大的Shm(400MB)保证能存下全部数据 实验数据:
* 块大小与总耗时(单位:s)的关系:

* 块大小与内存利用率的关系:

实验结论:
* 内存块越大,系统性能越好,但内存利用率越低。
须要在这2着间取个平衡点
* 一般取值为"平均(key+value)长度/2",且非常easy理解,用户数据长度基本一致即波动范围小时,内存碎片会减低,内存利用率会添加
2 UDC、Memcache、Redis内存管理策略性能对照
实验方案:
* UDC策略使用默认块大小为200B,Memcached策略使用默认增长因子1.25
* 分别进行10w、50w.... 5千万、1亿次压測操作,每次进行1个Set加1个Get。计算总耗时和内存利用率
实验数据:
* 3种内存管理策略在不同压測次数下的总耗时(单位:s)情况
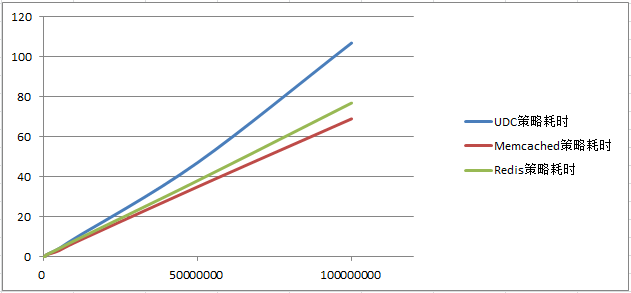
* 本实验3种内存管理策略的内存利用率(与压測次数无关)
- UDC策略:72.83%
- Memcached策略:88.19%
- Redis策略:98.77%
实验结论:
* Memcached的Slab Allocation机制在性能上的表现是最好的。且内存利用率也接近90%
* 当然。Memcached和Redis是基于进程堆的,主要用于缓存。UDC是基于Shm,用来做持久化存储。需考虑很多其它数据分布/同步/容灾等方面,3着不是必需用来直接比較,这里仅仅是单从内存管理策略上进行分析。
版权声明:本文博客原创文章,博客,未经同意,不得转载。

![[Matlab]求解线性方程组](/upload/rand_pic/2-402.jpg)





![[uva816]AbbottsRevenge Abbott的复仇(经典迷宫BFS)](/upload/rand_pic/2-173.jpg)





