目錄
1. Linux內存管理概述
1.1 內存的層次結構
1.2 虛擬內存概述
1.2.1 虛擬內存基本思想
1.2.2 進程虛擬地址空間
1.3 內核空間到物理空間的映射
1.3.1 內核空間的線性映射
1.3.2 內核鏡像的物理存儲
1.4 虛擬內存實現機制
2. 進程用戶空間管理
2.1 進程用戶空間布局
2.2 進程用戶空間的內核描述
2.2.1 概述
2.2.2 mm_struct結構
2.2.3 vm_area_struct結構
2.2.4 實例:內核態打印虛存區信息
3. 創建進程用戶空間
3.1 調用fork創建用戶空間
3.1.1 概述
3.1.2 copy_mm函數分析
3.2 調用exec進行虛存映射
3.2.1 虛存映射的含義
3.2.2 虛存映射時機
3.2.3 新建vma的方法
3.2.4 虛存映射種類
3.3 與用戶空間相關的主要系統調用
4. 請頁機制概述
4.1 請頁機制的目的
4.2 頁故障原因
4.3 缺頁異常處理
4.3.1 總體方案
4.3.2 處理流程
4.4 請頁函數概述
5. 物理內存分配與回收
5.1 物理內存管理機制
5.2 物理內存的組織
5.2.1 UMA和NUMA
5.2.2 Linux物理內存組織
5.2.3 內存管理區(zone)
5.2.4 頁描述符
5.4 伙伴(Buddy)算法
5.4.1 伙伴算法概述
5.4.2 伙伴算法的分配原理
5.4.3 伙伴算法核心函數分析
5.4.4 物理頁面的分配與回收
5.5 Slab分配機制
5.5.1 Slab機制概述
5.5.2 Slab的組成
5.5.3 Slab專用緩沖區
5.5.4 Slab通用緩沖區
5.6 內核空間非連續內存區的分配
5.6.1 非連續內存區
5.6.2 非連續內存區數據結構
5.6.3 vmalloc函數分析
5.6.4 vmalloc與kmalloc辨析
5.6.5 內存分配實例
6. 交換機制概述
6.1 交換的基本原理
6.2 交換的主要問題
6.2.1 哪種頁面要換出
6.2.2 如何在交換區存放頁面
6.2.3 如何選擇被交換出的頁面
7. 內存管理實例
7.1 實現功能
7.2 背景知識
7.2.1 mmap系統調用流程
7.2.2 缺頁異常處理函數
7.3 實現思路
7.4 實現分析
7.4.1 模塊初始化函數
7.4.2 mmap函數
7.4.3 fault函數
7.4.4 測試用例
7.5 連續內存映射示例
7.5.1 模塊初始化函數
7.5.2 mmap函數

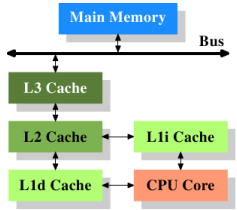
說明1:盡管內存與外存速度快很多,但是還是無法與CPU的速度匹配,因此CPU內部就需要更快的存儲設備,也就是高速緩存(cache)
對cache處理的目標就是提高命中率,避免過多低速的訪問內存操作
說明2:通過lscpu命令可以查看CPU的體系結構,其中包含Cache的層次結構

以當前實驗環境的虛擬機為例,L1 cache區分為dcache和icache,L2 & L3 cache則是命令與數據混用,構成如下圖所示的cache層次
在計算機中運行的程序,其代碼、數據、堆和棧的總量可以超過實際內存的大小,操作系統只將當前使用的程序塊保存在內存中,其余的程序塊則保留在磁盤上。必要時,操作系統負責在磁盤和內存之間交換程序塊

程序一旦被運行就稱為一個進程,內核就會為每個運行的進程提供大小相同的虛擬地址空間,這使得多個進程可以同時運行又不會相互干擾
任意一個時刻,在一個CPU上只有一個進程在運行。當進程發生切換時,虛擬地址空間也會隨之切換(通過將進程頁表的pgd物理地址寫入cr3控制寄存器)
程序經編譯鏈接后形成的地址空間是虛擬地址空間,最終需要轉換為物理地址并加載到物理內存中才能運行,這個映射關系需要通過頁表完成
如果給出的頁表不同,CPU將某一虛擬地址空間中的地址轉換成的物理地址就會不同。所以我們為每個進程都建立頁表,將每個進程的虛擬地址空間根據自己的需要映射到物理地址空間

① 雖然內核空間占據每個進程虛擬地址空間中的最高1GB,但是進程內核空間映射到物理內存卻是從最低的地址開始
X86中為0x00000000,在其他體系結構中,最低物理地址不一定是0x00000000(e.g. ARM)
② 之所以這么規定是為了在內核空間與物理地址之間建立起簡單的線性映射關系,其中3GB(0xc0000000)就是物理地址與虛擬地址之間的位移量,在內核中使用PAGE_OFFSET宏標識
③ 從圖示中可見,1GB的內核空間并未全部進行線性映射,其中從0x00000000到ZONE_NORMAL末端進行了線性映射
在這個區域內,可以通過__pa & __va進行虛擬地址和物理地址的相互"計算"
在X86體系結構中,系統啟動時將Linux內核鏡像裝入物理地址的0x00100000處,具體如下圖所示,

內核鏡像只占用從0x00100000到start_mem的區域,從start_mem到end_mem這段區域稱作動態內存,是用戶程序和數據使用的內存區
Linux虛擬內存的實現需要多種機制的支持,他們之間的關系如下圖所示,

a. 首先內核通過地址映射機制把進程從磁盤映射到虛擬地址空間(注意,這里只是映射到虛擬地址空間,并不分配物理內存)
b. 當進程執行時,如果發現要訪問的頁沒有在物理內存時,就發出頁請求(如圖①)
c. 如果有空閑的內存可供分配,就請求分配內存(如圖②);并把正在使用的頁記錄在頁緩存中(如圖③)
d. 如果沒有足夠的內存可供分配,就調用交換機制,騰出一部分內存(如圖④⑤)
e. 在地址映射機制中要通過TLB來加速物理頁的尋找(如圖⑧)
g. 把物理頁內容交換到交換文件后,也要通過修改頁表來映射文件地址(如圖⑦)

① 每個程序編譯鏈接后形成的ELF文件中包含代碼段(Text)和數據段(Date和BSS),其中代碼段在下,數據段在上
② 鏈接器和函數庫也有自己的代碼段(Text)和數據段(Data和BSS)
③ 運行程序生成進程時,每個進程還有獨占的堆(Heap)和棧(Stack)空間,注意二者的生長方向
④ 進程要映射的文件(e.g. 動態庫、普通文件)被映射到內存映射區(Memory Mapping Region)
實現測試用例如下,最終調用pause系統調用是為了讓進程處于TASK_INTERRUPTIBLE狀態,便于通過其他終端觀察該進程的狀態
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>int a = 1; // data段
int b; // bss段int main(void)
{char *buff = NULL; // 棧buff = (char *)malloc(1024); // 堆printf("address of a is %p\n", &a);printf("address of b is %p\n", &b);printf("address of buff is %p\n", &buff);printf("address of malloc memory is %p\n", buff);printf("pid is: %d\n", getpid());pause();return 0;
}
使用cat /proc/進程號/map命令查看一下該進程的用戶空間布局,

可見程序中各變量地址所在的區域和預期是符合的,其中.data段和.bss段都在數據段部分
① 地址:虛擬內存區的起始和終止地址(注意這里引入了虛擬內存區的概念)
② 權限:虛擬內存區的訪問權限,r=read / w=write / x=execute / s=shared / p=private(copy on write)
③ 偏移(offset):虛擬內存區在被映射文件中的偏移量(注意這里引入了虛擬內存區與文件的映射關系)
⑥ 文件名:被映射文件的文件名,如果該虛擬存儲區和磁盤文件無關則為空
① Linux把進程的用戶空間劃分為若干個區間進行管理,這些區間稱為虛擬內存區(簡稱vma)
② 進程的用戶地址空間主要由mm_struct和vm_area_struct結構來描述,其中,
vm_area_struct:描述用戶空間中的各個虛擬內存區
③ mm_struct和vm_area_struct的關系如下圖所示

可見mm_struct結構包含在task_struct結構中,用于描述一個進程的整個用戶空間;而mm_struct中包含一系列vm_area_struct結構,用于描述每個虛擬內存區
mm_struct定義在include/linux/sched.h中,主要字段含義如下,

一個進程的用戶空間可能包含多個虛擬存儲區,當vma較少時,使用單鏈表管理(按虛擬地址升序排列),由mmap字段索引;當vma較多時,使用紅黑樹管理,由mm_rb字段索引

mm_struct中存儲了一系列地址值,可以從整體上描述進程用戶空間的范圍
① mm_user是一個thread level的計數值,表示正在引用該地址空間的thread數目
例如在調用do_fork時如果帶有CLONE_VM標志,則不會生成新的mm_struct,而只是將父進程mm_struct的mm_users字段加1,這種情況一般是調用vfork創建進程或調用clone創建子線程

順便劇透一下,共享mm_struct和拷貝mm_struct是兩回事兒,讓各位先看一眼吧,下圖中就是調用fork流程時的拷貝父進程mm_struct的操作

當有其他線程在查看該mm_struct的內容時,比如cat /proc/進程號/maps,也會增加mm_users計數,以確保在此過程中mm_struct不被釋放
② mm_count的使用涉及內核線程和用戶線程的區別。在Linux中,用戶線程和內核線程都是task_struct的實例,區別是內核線程沒有用戶空間,所以內核線程的mm字段為NULL
在schedule函數中進行上下文切換時,會根據mm字段判斷即將調度的是用戶線程還是內核線程。內核線程不用訪問用戶空間,所以可以借用將被換出的用戶線程的用戶空間
其實mm_count字段的設置還是為了避免在mm_struct在使用過程中被釋放,只有當mm_struct的mm_count字段為0時才會釋放mm_struct結構,該過程在mmdrop函數中完成

而上圖列表中描述在調用clone生成線程時會增加mm_count計數是錯誤的,如上文分析,此時增加的是mm_users計數

當mm_users字段為0時,會釋放所有所有虛擬存儲區,并將該mm_struct從mmlist鏈表中刪除
mm_struct定義在include/linux/mm.h中,主要字段含義如下,

因為每個虛擬存儲區可能來源不同,例如可執行鏡像、共享庫、動態分配的內存區等,對于不同的區間可能有不同的權限和不同的操作
vm_ops字段用來抽象對不同虛擬存儲區的處理方法,其中的nopage函數是用于處理缺頁異常的函數


可見棧、堆和BSS段的映射是匿名的,關于匿名映射,后文還有說明

cat /proc/進程號/maps打印的就是mm_struct中各個vm_area_struct的信息,我們在內核態也打印虛存區信息進行比對
#include <linux/module.h>
#include <linux/kernel.h>
#include <linux/init.h>
#include <linux/sched.h>static int pid;
module_param(pid, int, 0644);static int __init hello_init(void)
{ struct task_struct *p = NULL;struct vm_area_struct *temp = NULL;// 根據PID查找task_struct//p = find_task_by_vpid(pid);p = pid_task(find_vpid(pid), PIDTYPE_PID);temp = p->mm->mmap;printk("mm_struct info:\n");printk("start_code = %lx\n", p->mm->start_code);printk("end_code = %lx\n", p->mm->end_code);printk("start_data = %lx\n", p->mm->start_data);printk("end_data = %lx\n", p->mm->end_data);printk("start_brk = %lx\n", p->mm->start_brk);printk("brk = %lx\n", p->mm->brk);printk("mmap_base = %lx\n", p->mm->mmap_base);printk("start_stack = %lx\n", p->mm->start_stack);printk("The virtual memory area(VMA) are:\n");// 遍歷vm_area_struct,打印起止地址while (temp) {printk("start:%p\tend:%p\n", (unsigned int *)temp->vm_start,(unsigned int *)temp->vm_end);temp = temp->vm_next;}return 0;
}static void __exit hello_exit(void)
{}module_init(hello_init);
module_exit(hello_exit);MODULE_LICENSE("GPL");

對照之前cat /proc/進程號/maps的結果,可見task_struct的地址信息在vm_area_struct的范圍之內,同時增補如下說明,
① start_code & end_code在進程代碼段vm_area_struct范圍內,但不足4KB(虛擬內存區的分配均以頁為單位)
② start_data & end_data跨越了進程數據段的2個vm_area_struct,其中一部分為只讀,一部分為可讀寫
③ start_brk & brk之間的范圍是堆(Heap),大小為132KB
④ 進程中使用到的2個動態庫(libc.so & ld.so)均映射到Memory Mapping Region,而task_struct中的mmap_base指向MMR區域的最高地址處
在低于2.6.24版本中,使用find_task_by_pid函數查找task_struct
在2.6.24 ~ 2.6.31版本中,使用find_task_by_vpid函數查找task_struct
在后續的版本中不再包含上述2個函數,我們使用pid_task宏查找task_struct
malloc函數內部實際調用了brk和mmap兩個系統調用,當所要分配的內存空間較少時,使用brk實現;當所要分配的內存空間較大時,使用mmap方式實現,而我們現在知道mmap函數在內核態會建立新的虛擬存儲區
下面我們就通過實驗來驗證下上面的說法,以及在內核態實際產生的效果
① 用戶空間不再調用malloc函數分配內存,查看進程空間虛擬緩沖區布局



可見此時進程用戶空間中是沒有heap的;mm_struct中的start_brk & brk也是指向相同的位置,說明這段空間為0
可見之前的malloc(1024)內部是通過sbrk & brk系統調用實現的
進程可以通過增加堆的大小來分配內存,所謂堆是一段長度可變的連續虛擬內存,始于進程的未初始化數據段末尾(即BSS段),隨著內存的分配和釋放而增減。通常將堆的當前內存邊界稱為program break
| 所需頭文件 | #include <unistd.h> |
| 函數原型 | void *sbrk(intptr_t increment); |
| 函數參數 | increment:將program break在原有地址上增加從參數increment傳入的大小 sbrk(0)將返回當前program break的位置,對其不做改變 |
| 函數返回值 | 成功返回之前program break的位置;錯誤返回-1 |
| 所需頭文件 | #include <unistd.h> |
| 函數原型 | int brk(void *addr); |
| 函數參數 | addr:將program break設置為參數addr所制定的位置,內核內部會進行頁對齊 |
| 函數返回值 | 成功返回0;錯誤返回-1 |




a. malloc中調用sbrk & brk的方式比示例代碼復雜很多,但示例代碼更能體現這2個函數的功能本質(雖然實際編程中幾乎不會直接使用)
b. sbrk(0)返回的是heap區域的低端地址,位置在進程的bss段之上,但并非緊挨著
c. 使用brk分配1KB內存,虛擬內存區是按頁對齊分配了4KB(0x9515000 ~ 0x9516000)
d. mm_struct中的start_brk & brk覆蓋范圍為1KB,與brk的調用是一致的(注意,在調用malloc時,mm_struct & 虛擬內存區的heap范圍是一致的)




使用malloc默認分配的heap的大小均為132KB,這應該不是一個巧合,我們使用malloc分配133KB進行驗證



可見此時新建了虛擬內存區,并進行了匿名映射,而不是使用heap來滿足內存分配的需求




可見累計超過132KB時,也使用mmap實現,但是!!!!!如果按如下方式分配,則是部分用heap,部分用mmap




同時需要注意,malloc函數返回的地址在內核分配地址的基礎上增加了8B偏移
補充:根據后續課程,malloc函數內部以128KB為調用mmap和brk的閾值

上文說明了mm_struct結構和vm_area_struct結構如何描述進程用戶空間,那么這種映射關系是什么時候建立的呢 ?
Linux內存管理的設計與實現。
① fork系統調用在創建新進程時,也為該進程創建完整的用戶空間
② 新進程的用戶空間是通過拷貝或共享父進程的用戶空間來實現的
③ 上述過程通過調用copy_mm函數實現,在該函數中可以明顯區分出是拷貝還是共享
do_fork
--> copy_process--> copy_mm可見無論是新建用戶進程(fork & vfork)、用戶線程(clone)還是內核線程(kernel_thread),都會調用到copy_mm
// copy_mm函數被copy_process函數調用
// clone_flags:創建進程時的拷貝參數
// tsk:指向新進程的task_struct
static int copy_mm(unsigned long clone_flags, struct task_struct * tsk)
{struct mm_struct * mm, *oldmm;int retval;// 初始化task_struct的相關計數// 這里主要是swap和context switch信息tsk->min_flt = tsk->maj_flt = 0;tsk->nvcsw = tsk->nivcsw = 0;// 新進程的用戶空間初始化為空tsk->mm = NULL;tsk->active_mm = NULL;/** Are we cloning a kernel thread?** We need to steal a active VM for that..*/// 內核線程沒有用戶空間,直接返回0// 在調度內核線程時會借用上一個用戶進程的用戶空間// 內核線程的父進程一定是內核線程,所以都沒有用戶空間oldmm = current->mm;if (!oldmm)return 0;// 如果拷貝標志中包含CLONE_VM,則與父進程共享用戶空間// 此時不會分配mm_struct,只是增加父進程mm_struct的mm_users計數// 這種情況一般是調用clone創建用戶線程或調用kernel_thread創建內核線程// 但是根據之前的分析,如果是創建內核線程,在上一個判斷中就直接返回了if (clone_flags & CLONE_VM) {atomic_inc(&oldmm->mm_users);mm = oldmm;/** There are cases where the PTL is held to ensure no* new threads start up in user mode using an mm, which* allows optimizing out ipis; the tlb_gather_mmu code* is an example.*/spin_unlock_wait(&oldmm->page_table_lock);goto good_mm;}retval = -ENOMEM;// 從slab分配mm_structmm = allocate_mm();if (!mm)goto fail_nomem;/* Copy the current MM stuff.. */// 這里就是拷貝父進程memcpy(mm, oldmm, sizeof(*mm));// mm_init函數// 1. 初始化各種計數器// 2. 初始化鎖// 3. 分配并初始化頁表,內核頁表直接拷貝,用戶頁表清零if (!mm_init(mm))goto fail_nomem;// 設置mm_struct中與進程上下文切換相關字段if (init_new_context(tsk,mm))goto fail_nocontext;// 拷貝父進程的虛擬內存區// 寫時拷貝就是在這個函數中實現retval = dup_mmap(mm, oldmm);if (retval)goto free_pt;mm->hiwater_rss = mm->rss;mm->hiwater_vm = mm->total_vm;good_mm:tsk->mm = mm;tsk->active_mm = mm;return 0;free_pt:mmput(mm);
fail_nomem:return retval;fail_nocontext:/** If init_new_context() failed, we cannot use mmput() to free the mm* because it calls destroy_context()*/mm_free_pgd(mm);free_mm(mm);return retval;
}dup_mmap
--> copy_page_range--> copy_pud_range--> copy_pmd_range--> copy_pte_range--> copy_one_pte在copy_one_pte函數中,如果拷貝的頁可寫,則將父(src_pte)子(pte)進程中的這個pte表項均設置為只讀

這樣當父子進程中任何一個進程要進行寫入時,就會觸發異常,在異常中可識別出需要寫時拷貝,則該物理頁面被復制一份

從上面的分析可知,進程用戶空間的創建主要依賴于父進程,而在創建進程的過程中,所做的工作僅僅是mm_struct結構的建立、vm_area_struct結構的建立以及頁目錄和頁表的建立,并沒有真正地復制一個物理頁面

虛存映射就是把文件從磁盤映射到進程的用戶空間,將對文件的訪問轉化為對虛存區的訪問
① 當調用exec系統調用開始執行一個進程時,進程的可執行鏡像(包括代碼段、數據段和堆等)必須裝入到進程的用戶地址空間;如果該進程用到了任何一個共享庫,則共享庫也必須裝入到進程的用戶空間
② 由此可見,Linux并不將鏡像裝入物理內存,可執行文件只是被映射到進程的用戶空間中
③ 將可執行鏡像和共享庫加載到用戶空間,就是將這些文件和用戶空間的vma建立關聯(當然,還存在和文件無關的匿名映射,比如heap區)

② 在內核空間可以直接調用do_mmap創建一個新的虛存區,do_execve在加載elf文件時就會調用do_mmap創建新的虛存區
當可執行鏡像映射到進程的用戶空間時,將產生一組vm_area_struct結構來描述各虛存區,而每個虛存區代表可執行鏡像的一部分
有多個進程共享這一映射,如果一個進程對共享的虛存區進行了寫操作,其他進程都能感覺到,而且會修改磁盤上對應的文件
文件的共享就可以通過這種方式實現(但是需要用戶自己進程文件操作的同步與互斥)
進程創建這種映射只是為了讀文件而不是寫文件,因此對虛存區的寫操作不會修改磁盤上的文件,因此西游映射的效率比共享映射高
之前驗證中查看的虛存區類型均為私有的,權限中的p就是private的含義

與文件無關的映射,比如上文介紹的分配較大內存的malloc調用,就是用匿名映射的方式實現的
教材中推斷cat /proc/進程號/maps中的匿名映射對應BSS段(后續根據代碼驗證)

| 所需頭文件 | #include <sys/mman.h> |
| 函數原型 | void *mmap(void *addr, size_t len, int prot, int flag, int fd, off_t off); |
| 函數參數 | addr:映射到用戶空間的起始地址,通常將其設置為0,表示由系統選擇該映射區的起始地址,該函數成功時返回的就是該映射區的起始地址 ? len:映射的字節數 ? prot:映射區的保護模式,可選項如下, PROT_READ:映射區可讀 PROT_WRITE:映射區可寫 PROT_EXEC:映射區可執行 PROT_NONE:映射區不可訪問 ? flag:映射區的屬性,可選項如下, MAP_SHARED:指定映射區可共享,存儲操作修改映射文件 MAP_PRIVATE:對映射區的存儲操作導致創建該映射文件的一個私有副本,不會修改映射的文件 MAP_LOCKED:鎖定這個虛存區,不能交換 MAP_ANONYMOUS:匿名區,與文件無關 其中MAP_SHARED & MAP_PRIVATE必須指定且只指定一個 ? fd:要被映射的文件描述符 ? off:要映射字節在文件中的起始偏移量 ? 說明:如果是匿名映射,fd & off參數被忽略,但是有些實現要求fd為-1 |
| 函數返回值 | 成功返回映射區的起始地址;若出錯,返回MAP_FAILED |
使用mmap映射文件的操作比較常見,此處重點關注下匿名映射的實現。從上文中可知,匿名映射是和共享映射 & 私有映射并列的一種映射類型。但是根據mmap函數的說明,匿名映射更像是附加在共享映射 & 私有映射上的一種屬性,即與文件無關,下面對此進行驗證
#include <stdio.h>
#include <sys/mman.h>int main(void)
{int fd = -1;int pid = -1;int *map = NULL;map = (int *)mmap(0, 4, PROT_READ|PROT_WRITE,MAP_SHARED|MAP_ANONYMOUS, 0, 0); // 共享且匿名if (map == MAP_FAILED) {printf("mmap error\n");return -1;}*map = 100;pid = fork();if (pid == 0) {// 子進程修改*map = 200;} else if (pid > 0) {// 父進程讀取wait(0);printf("value = %d\n", *map);} else {printf("fork error\n");return -1;}return 0;
}示例中以共享且匿名的方式建立映射區,根據結果,子進程的修改父進程可感知
![]()
如果將映射方式修改為私有且匿名,則子進程的修改父進程無法感知,這也就體現了匿名映射是一種附加屬性
map = (int *)mmap(0, 4, PROT_READ|PROT_WRITE,MAP_PRIVATE|MAP_ANONYMOUS, 0, 0); // 私有且匿名UNIX/LINUX。![]()
① do_mmap建立了文件到虛存區的映射,但是并沒有建立虛存頁面到物理頁面的映射,這種映射是通過請頁機制動態建立的
② Linux采用請頁機制來節約物理內存,在運行程序時,Linux僅將當前要使用的用戶空間中的少量頁面裝入內存,需要時再通過請頁機制將特定頁面調入內存
說明:請頁機制是有系統開銷的,但是由于以下原因,可以認為缺頁異常是一種稀有事件,
① 進程開始運行時并不訪問其地址空間中的全部地址,事實上,有一部分地址也許進程永遠不會使用(e.g. 進程只使用libc庫中很小一部分函數)
② 局部性原理保證了在程序執行的每個階段,真正使用的進程頁只有一小部分,因此暫時不用的頁沒必要調入內存
當要訪問的頁不在內存時,處理器將向Linux報告一個頁故障及對應的頁故障原因,頁故障的產生有如下三種原因,

虛擬地址無效(例如要訪問的虛擬地址在PAGE_OFFSET[3GB]之外),則該地址無效,Linux將向進程發送一個信號并終止進程的運行
虛擬地址有效,但其所對應的頁當前不在物理內存中,即發生缺頁異常。此時操作系統必須從磁盤或交換文件(此頁被換出)中將其裝入物理內存
要訪問的虛擬地址被寫保護,即保護錯誤,此時操作系統需要判斷出如下2種情況,
a. 如果是某個用戶進程正在寫當前進程的地址空間,則發送一個信號并終止進程的運行
b. 如果錯誤發生在一個舊的共享頁上,則要對這一共享頁進行復制,也就是寫時拷貝

① 當一個進程運行時,如果CPU訪問了一個有效的虛擬地址,但是這個地址對應的頁沒有在內存中,則CPU產生一個缺頁異常,同時將這個虛擬地址存入CR2寄存器
② Linux的缺頁異常處理首先要對產生缺頁的原因進行區分:是由編程錯誤引起的異常,還是由訪問進程用戶空間的頁尚未分配物理頁面所引起的異常

① 缺頁異常由do_page_fault函數處理,該函數首先從CR2寄存器讀取引起缺頁的虛擬地址,如果沒有找到,則說明訪問了非法虛擬地址,Linux會發送信號終止進程
否則,檢查缺頁類型,如果是非法類型(越界錯誤、段權限錯誤等)同樣會發送信號終止進程
② 缺頁異常肯定是發生在內核態,如果發生在用戶態則必定是錯誤,于是把相關信息保存在進程的PCB中
③ 對有效的虛擬地址,如果是缺頁異常,Linux必須區分頁所在的位置,即判斷頁是在交換文件中,還是在可執行鏡像中。Linux可以通過頁表項進行判斷,如果頁表項非空,但對應的頁不在內存,則說明該頁處于交換文件中,操作系統要從交換文件裝入頁
請頁函數的核心作用就是得到一個物理頁的頁描述符(struct page),用于和引起缺頁的線性地址建立映射關系

根據vm_ops的nopage字段是否為空,分為如下2種情況,
① nopage字段不為空,說明該虛存區映射了一個磁盤文件,nopage字段指向從磁盤進行讀入的函數(這種情況涉及磁盤文件的底層操作)
② nopage字段為空,說明該虛存區沒有映射磁盤文件,也就是說他是一個匿名映射。因此do_no_page調用do_anonymous_page函數獲得一個新的頁面

在獲取到頁面(new_page)之后,內核就會據此填充進程頁表,注意其中pte_offset_map和pte_unmap的配對使用
基于物理內存在內核空間中的映射原理,物理內存的管理機制主要有以下4種,
負責大塊連續物理內存的分配和釋放,以頁框為基本單位,該機制可避免外部碎片
內核經常請求和釋放單個頁框,該緩存包含預先分配的頁框,用于滿足本地CPU發出的單一頁框請求
負責小塊連續物理內存的分配,并且他也作為高速緩存,主要針對內核中經常分配并釋放的對象
vmalloc機制使得內核可以通過連續的線性地址來訪問非連續的物理頁框,這樣可以最大限度的使用高端物理內存

① NUMA計算機(non-uniform memory access)
一種多處理器計算機,每個CPU擁有各自的本地內存。這樣的劃分使每個CPU都能以較快的速度訪問本地內存,各個CPU之間通過總線連接起來,這樣也可以訪問其他CPU的本地內存,只是速度較慢
② UMA計算機(uniform memory access)
redis內存管理、
為了兼容NUMA模型,Linux內核引入了內存節點的概念,每個節點關聯一個CPU。各個節點又被劃分為幾個內存區,每個內存區中又包含若干個頁框
因此物理內存在邏輯上被劃分為三級結構,分別使用pg_data_t(節點)、zone(區)和page(頁框)這三種數據結構加以描述
NUMA計算機中每個CPU的物理內存稱為一個內存節點,內核通過pg_data_t數據結構來描述,系統內的所有節點形成一個雙鏈表
UMA模型下的物理內存只對應一個節點,也就是說整個物理內存形成一個節點

各個節點劃分為若干個區,通過下面幾個宏來標記物理內存不同的區,
說明:64位操作系統不再有高端內存的概念,可以支持大于4GB的內存尋址,ZONE_NORMAL空間擴展到64GB或128GB

內核使用struct page結構表示系統中的每個物理頁,也稱作頁描述符

| 字段 | 說明 |
| flags | 頁的狀態(e.g. 頁是否是臟的,是否被鎖定在內存中),這些標志定義在<linux/page_flags.h>文件中 |
| _count | 頁的引用計數,當計數值變為0時,說明當前內核并沒有引用這一頁,于是在新的分配中就可以使用該頁(使用page_count宏檢查該字段的值) |
| mapping | 用于管理文件(struct inode)映射到內存的頁面 |
| private | 頁的私有數據 |
| virtual | 頁的虛擬地址 |
| lru | 將page鏈入LRU鏈表,用于頁面回收 |

比如后面要用到的SetPageReserved宏,就是設置頁的PG_reserved標志
#define SetPageReserved(page) set_bit(PG_reserved, &(page)->flags)說明2:內核使用struct page結構來管理系統中所有的頁,因為內核需要知道一個頁是否空閑;如果頁已經被分配,內核還需要知道誰擁有這個頁
struct page *mem_map;① 從mem_map數組中頻繁地請求和釋放不同大小的連續頁面,必然導致外碎片問題,因此Linux引入了伙伴算法
② 伙伴算法將所有的空閑頁面分為(MAX_ORDER + 1)個塊鏈表,每個鏈表中的一個塊含有2的冪次個頁面,我們把這種塊簡稱為"頁塊"或"塊"

例如第0個鏈表中的塊的大小都是2^0(1個頁面),第9個鏈表塊中塊的大小都是2^9(512個頁面),MAX_ORDER的默認值為11(即最大的頁塊為2048個頁面)
③ Linux中使用struct free_area結構管理伙伴系統
struct zone {// 其他成員struct free_area free_area[MAX_ORDER];
};struct free_area {struct list_head free_list; // 大小為2^k頁的空閑塊對應的頁描述符unsigned long nr_free; // 大小為2^k的空閑塊的個數
};當nr_free為0且fre_list為空時,說明沒有大小為2^k頁的空閑頁塊
如果要分配階為n的頁塊,則先從第n個頁框鏈表中查找是否存在空閑頁塊,如果有則分配;否則在第(n + 1)個頁框鏈表中繼續查找,直到找到為止
示例:如果申請大小為8的頁塊(分配階為3),但卻在頁塊大小為32的鏈表中找到空閑塊,則先將這32個頁面等分,前一半作為分配使用,另一半作為新元素插入下級大小為16的鏈表中;繼續將前一般大小為16的頁塊等分,一半分配,另一半插入大小為8的鏈表中
以上過程的逆過程就是頁塊的釋放過程,伙伴算法把滿足伙伴條件的頁塊合并為一個塊,如果合并后的塊還可以跟相鄰的塊進行合并,則繼續合并
/*
* zone:指定分配的內存區
* order:指定要分配頁塊的階數
*/
static struct page *__rmqueue(struct zone *zone, unsigned int order)
{struct free_area * area;unsigned int current_order;struct page *page;// 從指定階數遍歷到最大階數for (current_order = order; current_order < MAX_ORDER;++current_order) {area = zone->free_area + current_order;// 如果當前階數無空閑頁塊則繼續查找更高一階if (list_empty(&area->free_list))continue;page = list_entry(area->free_list.next, struct page, lru);// 將待分配頁塊移出鏈表,該頁塊可能超過請求的大小list_del(&page->lru);rmv_page_order(page);// 減少該階頁塊個數area->nr_free--;// 減少內存區空閑頁個數// 注意:減少空閑頁使用的是指定要分配的階數order,而非當前階數// 因為頁塊中多余的頁還會交還伙伴系統zone->free_pages -= 1UL << order;// 如果所得到的頁塊大于所請求的頁塊,則按照伙伴算法的分配原理將// 大的頁塊分裂成小的頁塊分配return expand(zone, page, order, current_order, area);}return NULL;
}static inline void rmv_page_order(struct page *page)
{__ClearPagePrivate(page);page->private = 0;
}rmv_page_order函數清除頁塊首個頁面的private字段,該字段原先記錄了該頁塊的階數(后文可見)
// 使用struct page的private字段記錄頁塊階數
static inline void set_page_order(struct page *page, int order) {page->private = order;__SetPagePrivate(page);
}/*
* zone:指定分配的內存區
* page:查找到的可供分配的頁塊首個頁面指針
* low:要分配頁塊的階數
* high:可供分配的頁塊的階數(>=low)
* area:對應high階數的鏈表數組成員地址
*/
static inline struct page *
expand(struct zone *zone, struct page *page,int low, int high, struct free_area *area)
{unsigned long size = 1 << high; // 可供分配的頁塊頁面數while (high > low) {area--;high--;size >>= 1; // 將可供分配的頁框一分為二BUG_ON(bad_range(zone, &page[size]));// 將折半的頁塊插入list_add(&page[size].lru, &area->free_list);area->nr_free++;// 設置分裂后頁塊的階數set_page_order(&page[size], high);}return page;
}當struct page結構中的lru字段不用于組織LRU鏈表時,可用于其他用途,比如此處用于組織頁塊
說明4:分區頁框管理器分為兩大部分:前端的管理區分配器和伙伴系統
管理區分配器負責搜索一個能滿足請求頁塊大小的管理區,在每個管理區中,具體的頁框分配工作由伙伴系統負責。為了達到更好的系統性能,單個頁框的申請工作直接通過per-CPU頁框高速緩存完成


內核中有6個稍有差別的函數和宏來請求頁框,但最終都是調用alloc_pages來獲取連續的物理頁框
上圖中4個綠色的get_page類函數返回的都是物理頁面對應的虛擬地址,以__get_free_pages函數為例,

alloc_pages函數返回的是頁描述符,然后通過page_address函數獲取物理頁面對應的虛擬地址,如果分配的物理頁面在內核的線性映射區域,則直接計算出對應的虛擬地址
static inline void *lowmem_page_address(struct page *page)
{return __va(page_to_pfn(page) << PAGE_SHIFT);
}如果不需要得到物理頁面對應的虛擬地址,而只是需要物理頁面的描述符,則可以調用alloc_pages函數
使用free_page & free_pages函數釋放,其中free_page函數調用free_pages函數,實現釋放1個頁面
使用__free_page & __free_pages函數釋放,其中__free_page函數調用__free_pages函數,實現釋放1個頁面
① 上文介紹的伙伴算法負責大塊連續物理內存的分配和釋放,以頁框為單位,從而解決了外部碎片問題
② 如果要分配小塊內存,則需要解決內部碎片的問題。Slab機制的提出,最初就是為了解決物理內存的內部碎片問題
③ Slab將內核中常用的數據結構看作對象,并為每一種對象建立高速緩存,內核對象的分配和釋放均在這塊高速緩存中進行,進而減少了對伙伴算法的調用次數
④ 減少對伙伴算法的調用次數,又可以避免弄臟硬件高速緩存,進而減少對內存的平均訪問次數,提高了內存訪問效率

② 每個slab由若干個物理頁框組成(頁框通過伙伴算法分配)
③ 每個slab包含若干個同種類型的對象,這些對象或已被分配,或空閑
說明:盡管Slab高速緩存在英文中使用了Cache這個詞,但實際上是內存中的區域,而不是指硬件高速緩存
但是通過在一個slab中組織多個對象,可以提高硬件高速緩存的命中率
個人:簡單來說,Slab從伙伴算法那里批發物理頁框,然后零售給對象
專用緩沖區主要用于頻繁使用的數據結構,如task_struct、mm_struct、vm_area_struct、file、dentry和inode等
kmem_cache_t *
kmem_cache_create (const char *name, size_t size, size_t offset,unsigned long flags, void (*ctor)(void*, kmem_cache_t *, unsigned long),void (*dtor)(void*, kmem_cache_t *, unsigned long))| 參數 | 含義 |
| name | 緩沖區名稱,在/proc/slabinfo中用作標識 |
| size | 對象大小 |
| offset | 在緩沖區內第一個對象的偏移,用來確定在業內進行對齊的位置,缺省為0,表示標準對齊 |
| flags | 對緩沖區設置的標志, SLAB_HWCACHE_ALIGN:第一個緩沖區中的緩沖行邊界對齊(16或32字節) SLAB_NO_REAP:不允許系統回收內存 SLAB_CACHE_DMA:使用DMA內存 |
| ctor | 分配對象時的構造函數,一般為NULL |
| dtor | 釋放對象時的析構函數,一般為NULL |
說明:撤銷緩沖區使用kmem_cache_destroy函數實現
kmem_cache_create函數創建的緩沖區中并不包含任何slab,因此也沒有空閑對象,只有以下兩個條件均為真時,才給緩沖區分配slab
void *kmem_cache_alloc (kmem_cache_t *cachep, int flags);
void kmem_cache_free (kmem_cache_t *cachep, void *objp);如果緩沖區中所有的slab中都沒有空閑的對象,那么slab必須調用__get_free_pages獲取新的頁面,flags是傳遞給該函數的參數,一般應該是GFP_KERNEL或GFP_ATOMIC
![]()

說明:如果要頻繁創建很多相同類型的對象,就應該考慮使用Slab專用緩沖區,不要自己去實現空閑鏈表
② 通用緩沖區最小為32B,然后依次為64B、128B直至128KB(一般kmalloc分配的內存上限)
③ 通用緩沖區一般用于使用不頻繁的數據結構(對于頻繁使用的數據結構,使用專用Slab是可以從硬件高速緩存中獲益的)
說明1:無論是Slab專用緩沖區還是通用緩沖區,都是用于小塊物理內存分配的,他們本質上都受制于伙伴系統最大頁塊的限制(e.g. MAX_ORDER為11時,最大的頁塊為8MB)
如果需要分配大塊連續的物理內存,需要使用Linux中的其他內存分配機制(e.g. memreserve)
說明2:通過Slab通用緩沖區分配內存是會造成內碎片的,但是由于通用緩沖區針對不頻繁使用的數據結構,所以對性能影響不大
Slab通用緩沖區的分配和釋放使用大家熟悉的kmalloc和kfree函數實現,此處不再贅述
void *kmalloc(size_t size, int flags);
void kfree(const void *ptr);說明:kfree用于釋放由kmalloc函數分配的內存塊,如果要釋放的內存不是由kmalloc分配的,或者double free,都會導致嚴重后果

① 非連續內存處于VMALLOC_START到VMALLOC_END之間,也是處于內核空間
② 非連續內存區前后與非內存區之間插入的區間為安全區,用于"捕獲"對非連續內存的非法訪問
③ 內核使用vmalloc接口分配虛擬內存中連續但物理內存不一定連續的內存
Linux內核使用struct vm_struct結構來描述非連續內存區,

| 字段 | 說明 |
| addr | 非連續內存區的起始地址(虛擬地址) |
| size | 非連續內存區的大小 + 4KB(安全區的大小) |
| flags | 非連續內存區標志位 |
| pages | 非連續內存區頁指針數組首地址(詳見vmalloc函數分析) |
| nr_pages | 非連續內存區頁數 |
| phys_addr | 代碼中實際未使用 |
| next | 非連續內存區組成一個單鏈表(按虛擬地址升序排列) |
說明:從struct vm_struct結構的flags字段可知,vmalloc & ioremap機制都是基于非連續內存區實現的,只不過ioremap映射的物理地址是連續的
vmalloc
--> __vmalloc--> get_vm_area // 獲取vm_struct結構--> alloc_page // 逐頁獲取物理頁面--> map_vm_area // 修改內核頁表,映射非連續內存區進程內存分布,
PAGE_KERNEL:建立頁表項時的權限,PAGE_KERNEL對應的頁表項權限如下,
#define _PAGE_KERNEL \(_PAGE_PRESENT | _PAGE_RW | _PAGE_DIRTY | _PAGE_ACCESSED | _PAGE_NX)
__vmalloc函數中最重要的就是上面4個步驟,get_vm_area & map_vm_area下面單獨介紹,此處說明中間2個步驟,
首先分配用于存儲頁描述符指針的數據pages,如果數組大小小于PAGE_SIZE則使用kmalloc分配;如果大于PAGE_SIZE則遞歸調用__vmalloc,此時會形成非連續內存區逐級存放的效果
以32位處理器4KB頁為例,最多容納4KB / 4B = 1KB個頁描述符指針,也就是對應4MB內存,所以這種遞歸調用的層次是非常有限的
假設遞歸調用的第2級正好需要1個頁來存儲頁描述符指針,即頁描述符指針數組為4MB,則對應的內存為4MB / 4 * 4KB = 4GB,然后誰沒鳥事用vmalloc分配4GB的內存
內存管理策略,
__get_vm_area函數中使用kmalloc分配struct vm_struct結構,并將其加入vmlist單鏈表

在map_vm_area函數中,會從pgd --> pud --> pmd --> pt逐級分配頁目錄和頁表,并逐頁進行映射
② kmalloc分配的內存處于3GB ~ high_memory之間,這段內核空間與物理內存形成線性映射
③ vmalloc分配的內存在VMALLOC_START ~ VMALLOC_END之間,這段非連續內存區映射到物理內存也可能是非連續的
④ vmalloc分配的物理地址無需連續,而kmalloc確保頁在物理上是連續的
說明1:盡管僅僅在某些情況下才需要物理連續的內存塊,但是很多內核代碼都調用kmalloc而不是vmalloc獲取內存。這主要是出于性能的考慮,因為vmalloc函數為了把物理上不連續的頁面映射到連續的虛擬地址,需要專門建立頁表,并逐頁進行映射

根據上文分析,vmalloc函數已經分配了物理頁面并進行了映射,為何還會觸發缺頁異常呢 ? 細看vmalloc的實現,可見此時僅修改了init_mm標識的內核頁表,并未同步到進程頁表,所以進程若進入內核態訪問vmalloc分配的內存,依然會觸發缺頁異常,此時主要的行為就是更新進程頁表
unsigned long pagemem = 0UL;
unsigned char *kmallocmem = NULL;
unsigned char *vmallocmem = NULL;static int __init hello_init(void)
{ pagemem = __get_free_page(GFP_KERNEL);if (!pagemem) {printk("__get_free_page error\n");goto err1;}printk("pagemem = 0x%lx\n", pagemem);kmallocmem = kmalloc(100, GFP_KERNEL);if (!kmallocmem) {printk("kmalloc error\n");goto err2;}printk("kmallocmem = 0x%p\n", kmallocmem);vmallocmem = vmalloc(1000000);if (!vmallocmem) {printk("vmalloc error\n");goto err3;}printk("vmallocmem = 0x%p\n", vmallocmem);return 0;
err3:kfree(kmallocmem);
err2:free_page(pagemem);
err1:return -1;
}static void __exit hello_exit(void)
{vfree(vmallocmem);kfree(kmallocmem);free_page(pagemem);
}可見分配的內存的虛擬地址是符合預期的,__get_fre_page和kmalloc分配的內存在線性映射區,vmalloc分配的內存在非連續內存區

① 當空閑內存數量少于某個閾值時,Linux內核需要釋放部分物理內存頁面,將內存的內容存儲到一個專用的磁盤空間(swap分區),是一種以時間換空間的策略
③ 頁面的交換有很大的時間開銷,是不得已而為之,他會使進程的執行在時間上有較大的不確定性
⑤ 可以通過命令或系統調用開啟或關閉交換機制,關閉方式可參考如下blog
https://blog.csdn.net/lixgjob/article/details/89001844
② 并非內存中所有頁面都可以交換出去,只有與用戶空間建立了映射關系的物理頁面才會被交換出去,而內核空間中內核所占的頁面則常駐內存
代碼段、數據段所占內存可以被換入換出,但堆和棧的頁面一般不被換出,目的是簡化內核的設計
內核中動態分配(kmalloc / vmalloc / __get_free_pages)的頁面在使用完成后會釋放到空閑頁面中,但是有些頁面雖然使用完畢,但是其內容仍有保存價值,因此不立即釋放,而是進入一個LRU隊列,經過一段時間的緩沖讓其老化,如果在此期間又要用到其中的內容,即可直接投入使用
① 文件系統中用來緩沖存儲一些文件目錄結構dentry的空間
free命令中的cache和buffer就是這些文件系統的緩沖
① 交換分區也被劃分為塊,每個塊的大小正好等于一頁,交換區中的一塊稱作一個頁插槽(Page Slot)
② 當進行交換時,內核盡可能把換出的頁放在相鄰的插槽中,從而減少訪問交換區時磁盤的尋道時間
③ 如果系統使用多個交換區,快速交換區(即放在快速磁盤中的交換區)可以獲得比較高的優先級,應當優先使用。當使用優先級相同的多個交換區時,應平衡負載
① 當發現沒有空閑頁面可分配時進行交換,這是一種被動交換策略
② 這種策略雖然簡單,但是系統需要在分配內存的重要時刻花費相當多的時間進行交換
① 在系統空閑時預先換出一些內存頁面,維持一定數量的空閑頁面,這是一種主動交換策略
① 當系統選出要交換的頁面時,將相應頁面寫入磁盤交換區,并修改相應頁表項將Preset標志置為0,但是并不立即釋放,而是將該struct page結構留在一個緩沖(Cache)隊列中,使其從活躍(Active)狀態轉為不活躍(Inactive)狀態
② 這些頁面的最后釋放要推遲到必要時才進行,這樣如果一個頁面在釋放后又立即被訪問,就可以從緩沖隊列找到相應頁面,不需要磁盤讀入
② 換出的頁面不一定要寫入磁盤(e.g. 一個頁面從讀入后沒有被寫過,是"干凈的"頁面)

① 通過訪問用戶空間的內存達到讀取內核數據的目的,這樣就可以進行內核空間到用戶空間的大規模信息傳送,從而應用于高速數據采集等性能要求高的場合
② 由于內核內存是受保護的,因此將數據從內核空間拷貝到用戶空間的通常方法是使用系統調用,但是系統調用的缺點是速度慢,這會成為數據高速處理的瓶頸
③ 本實例利用內存映射功能,將內核中的一部分虛擬內存映射到用戶空間,使得訪問用戶空間等同于訪問被映射的內核地址空間,從而不再需要數據拷貝操作
SYSCALL_DEFINE(mmap_pgoff, ...)
--> sys_mmap_pgoff--> SYSCALL_DEFINE6(mmap_pgoff, ...)--> vm_mmap_pgoff--> do_mmap_pgoff--> mmap_region(2.6.11版本沒有這級)--> file->f_op->mmap在調用file->f_op->mmap之前,會找到對應的vm_area_struct結構,如果是首次調用,會從專用Slab緩沖區分配vm_area_struct結構,該結構將作為參數傳遞給file->f_op->mmap函數
mmap并不分配物理內存,他所做的最重要的工作就是為進程虛擬內存區的虛擬地址建立頁表項
在file->f_op->mmap函數中,需要為vm_area_struct結構中的虛擬地址建立相應的頁表項,建立頁表項有2種方法,
在f_op->mmap函數中一次性為vm_area_struct中的線性地址建立頁表項,但是這就要求這些頁表所要映射的物理地址是連續的,但是vmalloc分配的內存物理上可能是不連續的
如上文所述,vm_operations_struct結構中的nopage函數(新版內核為fault函數)用于處理缺頁異常
調用過mmap之后,進程訪問的這段用戶空間虛擬地址已經是合法的,只是尚未裝載物理內存,所以觸發了缺頁異常。我們就是要在這個缺頁異常中分配物理頁面,并建立映射關系(即填充頁表項)
① 使用vmalloc函數在內核態分配一段內存,vmalloc返回的是內核空間的虛擬地址,用戶進程是無法直接訪問的,所以需要再映射到用戶進程空間中,也就是一個vm_area_struct結構中
② 使用mmap系統調用新建struct vm_area_struct結構,設置缺頁異常處理函數,在該函數中動態逐頁地建立映射關系
#define MAP_PAGE_COUNT 10
#define MAPLEN (PAGE_SIZE * MAP_PAGE_COUNT) // 分配10頁內存
#define MAP_DEV_MAJOR 240 // 主設備號
#define MAP_DEV_NAME "mapnopage" // 字符設備名稱static char *vmalloc_area;static int __init mapdrv_init(void)
{int result = -1;unsigned long virt_addr = 0;int i = 0;// 注冊字符設備,這是后續調用mmap系統調用的基礎result = register_chrdev(MAP_DEV_MAJOR, MAP_DEV_NAME, &mapdrv_fops);if (result < 0) {printk("register_chrdev error\n");return result;}// 分配虛擬地址連續物理地址不連續的內存vmalloc_area = vmalloc(MAPLEN);// 鎖定分配的頁面不被換出for (virt_addr = (unsigned long)vmalloc_area;virt_addr < (unsigned long)vmalloc_area + MAPLEN;virt_addr += PAGE_SIZE) {SetPageReserved(vmalloc_to_page((void *)virt_addr));// 在每頁的起始寫入字符串,供用戶態驗證sprintf((char *)virt_addr, "test %d", i++);}printk("vmalloc_area = 0x%p\n", vmalloc_area);return 0;
}調用SetPageReserved函數鎖定頁面時需要struct page結構,vmalloc_to_page函數用于從vmalloc分配的虛擬地址找到對應的頁描述符

參考之前對vmalloc函數實現的分析,vmalloc時是從內核頁表的pgd開始逐層生成并建立頁表,vmalloc_to_page就是對應的逆過程,先找到虛擬地址對應的頁表項pte,就能通過pte_pfn計算出頁號,再通過pfn_to_page就可以得到對應的頁描述符
此處注意pte_offset_map和pte_unmap的配對使用
static void __exit mapdrv_exit(void)
{unsigned long virt_addr = 0;// 解除頁面鎖定for (virt_addr = (unsigned long)vmalloc_area;virt_addr < (unsigned long)vmalloc_area + MAPLEN;virt_addr += PAGE_SIZE) {ClearPageReserved(vmalloc_to_page((void *)virt_addr));}// 釋放內存if (vmalloc_area) {vfree(vmalloc_area);vmalloc_area = NULL;}// 注銷字符設備unregister_chrdev(MAP_DEV_MAJOR, MAP_DEV_NAME);
}static struct vm_operations_struct map_vm_ops = {.open = map_vopen,.close = map_vclose,.fault = map_fault,
};int mapdrv_mmap(struct file *file, struct vm_area_struct *vma)
{unsigned long offset = vma->vm_pgoff << PAGE_SHIFT;unsigned long size = vma->vm_end - vma->vm_start;if (size > MAPLEN) {printk("map size too big\n");return -ENXIO;}vma->vm_flags |= VM_LOCKED;if (!offset) {// 設置vma操作函數,其中核心為缺頁處理函數faultvma->vm_ops = &map_vm_ops;}else {printk("offset out of range\n");return -ENXIO;}return 0;
}說明:vma->vm_pgoff標識的偏移量是以頁為單位的,所以是page offset(pgoff)
static int map_fault(struct vm_area_struct *vma, struct vm_fault *vmf)
{struct page *page = NULL;unsigned long offset = 0;unsigned long virt_start = 0;unsigned long pfn_start = 0;printk("vmf->pgoff = %ld\n", vmf->pgoff);// 發生缺頁的偏移量offset = (unsigned long)(vmf->pgoff << PAGE_SHIFT);// 對應偏移量的vmalloc分配內存地址virt_start = (unsigned long)vmalloc_area + offset;// vmalloc地址對應的頁號,可用于計算物理地址pfn_start = (unsigned long)vmalloc_to_pfn((void *)virt_start);if (!vma || !vmalloc_area) {printk("return VM_FAULT_SIGBUS\n");return VM_FAULT_SIGBUS;}if (offset >= MAPLEN) {printk("return VM_FAULT_SIGBUS\n");return VM_FAULT_SIGBUS;}page = vmalloc_to_page((void *)virt_start);get_page(page); // 增加頁引用計數// 缺頁異常處理函數的核心就是得到一個物理頁的頁描述符// 供用戶態線性地址建立映射關系vmf->page = page;printk("%s: map 0x%lx (0x%016lx) to 0x%lx , size: 0x%lx, page:%ld \n", __func__, virt_start, pfn_start << PAGE_SHIFT,(unsigned long)vmf->virtual_address, PAGE_SIZE, vmf->pgoff);return 0;
}
#define LEN (10*4096)int main(void)
{ int fd = 0;int loop = 0; char *vadr = NULL; if ((fd = open("/dev/mapnopage", O_RDWR)) < 0) {perror("open error");return -1;}vadr = mmap(0, LEN, PROT_READ, MAP_PRIVATE | MAP_LOCKED, fd, 0);for(loop = 0; loop < 10; loop++){printf("[%-10s----%lx]\n", vadr + 4096 * loop,(unsigned long)(vadr + 4096 * loop));}pause(); // 便于查看進程狀態
}# 建立設備節點
sudo mknod /dev/nopage c 240 0# 運行測試程序
sudo ./map_read


如上文所述,vmalloc分配的內存虛擬地址連續但物理地址不連續,所以只能在缺頁異常中逐頁建立映射
下面給出使用kmalloc分配內存,并在mmap函數中一次性建立映射的示例
#define MAP_PAGE_COUNT 10
#define MAPLEN (PAGE_SIZE * MAP_PAGE_COUNT)
#define MAP_DEV_MAJOR 240
#define MAP_DEV_NAME "mapnopage"static char *kmalloc_area;static int __init mapdrv_init(void)
{int result = -1;unsigned long virt_addr = 0;int i = 0;result = register_chrdev(MAP_DEV_MAJOR, MAP_DEV_NAME, &mapdrv_fops);if (result < 0) {printk("register_chrdev error\n");return result;}// 使用kmalloc分配物理連續的內存kmalloc_area = kmalloc(MAPLEN, GFP_KERNEL);for (virt_addr = (unsigned long)kmalloc_area;virt_addr < (unsigned long)kmalloc_area + MAPLEN;virt_addr += PAGE_SIZE) {SetPageReserved(virt_to_page((void *)virt_addr));sprintf((char *)virt_addr, "test %d", i++);}printk("kmalloc_area = 0x%p\n", kmalloc_area);return 0;
}說明:由于使用kmalloc函數分配物理連續的內存,此處直接用virt_to_page宏獲得虛擬地址對應的頁描述符
![]()
int mapdrv_mmap(struct file *file, struct vm_area_struct *vma)
{unsigned long offset = vma->vm_pgoff << PAGE_SHIFT;unsigned long size = vma->vm_end - vma->vm_start;int ret = 0;if (size > MAPLEN) {printk("map size too big\n");return -ENXIO;}vma->vm_flags |= VM_LOCKED;if (!offset) {// 一次性建立映射ret = remap_pfn_range(vma, vma->vm_start,__pa(kmalloc_area) >> PAGE_SHIFT, // 直接使用__pa計算物理地址MAPLEN, vma->vm_page_prot);}else {printk("offset out of range\n");return -ENXIO;}printk("%s: map from 0x%lx (0x%lx) to 0x%lx, size: 0x%lx\n", __func__, (unsigned long)kmalloc_area,(unsigned long)__pa(kmalloc_area), vma->vm_start, MAPLEN);return 0;
}

![]()

版权声明:本站所有资料均为网友推荐收集整理而来,仅供学习和研究交流使用。

工作时间:8:00-18:00
客服电话
电子邮件
admin@qq.com
扫码二维码
获取最新动态