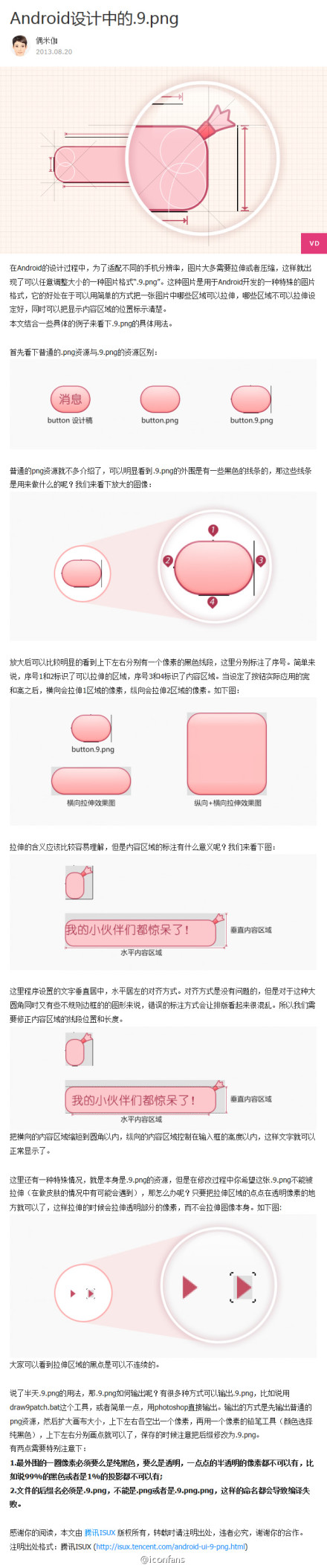
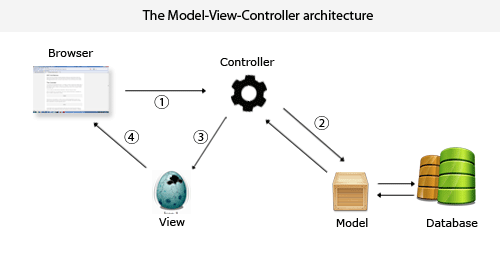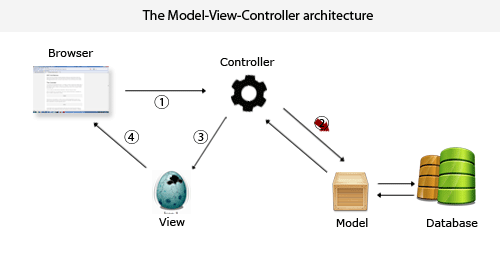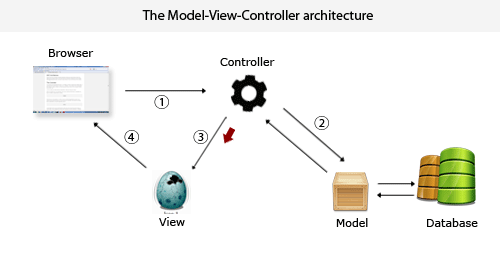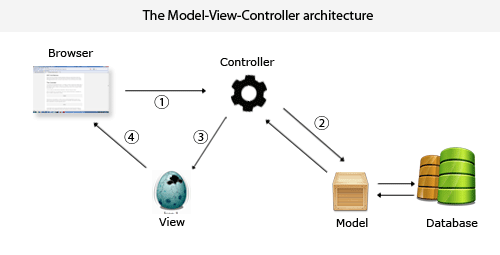
分布式数据集创建之textFile
scala> val distFile = sc.textFile(“data.txt”)
distFile: spark.RDD[String] = spark.HadoopRDD@1d4cee08
分布式数据集操作之转换和动作
- 转换(transformations):依据现有的数据集创建一个新的数据集
- 动作(actions):在数据集上执行计算后,返回一个值给驱动程序
数据集操作之map和reduce
distFile.map(_.size).reduce(_ + _ )
方法也接受可选的第二參数,来控制文件的分片数目。默认来说,Spark为每一块文件创建一个分片(HDFS默认的块大小为64MB),可是你能够通过传入一个更大的值来指定很多其它的分片。注意,你不能指定一个比块个数更少的片值(和hadoop中,Map数不能小于Block数一样)
- Map是一个转换,将数据集的每个元素,都经过一个函数进行计算后,返回一个新的分布式数据集作为结果。
- Reduce是一个动作,将数据集的全部元素,用某个函数进行聚合,然后将终于结果返回驱动程序,而并行的reduceByKey还是返回一个分布式数据集
spark搭建、
转换是惰性的
重要转换操作之caching(缓存)
眼下支持的转换(transformation)
| java spark开发,Transformation | Meaning |
| map(func)
| 返回一个新的分布式数据集,由每一个原元素经过func函数转换后组成 |
| filter(func)
| 返回一个新的数据集,由经过func函数后返回值为true的原元素组成 |
| flatMap(func) | 类似于map,可是每个输入元素,会被映射为0到多个输出元素(因此,func函数的返回值是一个Seq,而不是单一元素) |
| sample(withReplacement, frac, seed)
| 依据给定的随机种子seed,随机抽样出数量为frac的数据 |
| union(otherDataset)
| 返回一个新的数据集,由原数据集和參数联合而成 |
| groupByKey([numTasks])
| 在一个由(K,V)对组成的数据集上调用,返回一个(K,Seq[V])对的数据集。注意:默认情况下,使用8个并行任务进行分组,你能够传入numTask可选參数,依据数据量设置不同数目的Task (groupByKey和filter结合,能够实现类似Hadoop中的Reduce功能) |
| reduceByKey(func, [numTasks]) | 在一个(K,V)对的数据集上使用,返回一个(K,V)对的数据集,key同样的值,都被使用指定的reduce函数聚合到一起。和groupbykey类似,任务的个数是能够通过第二个可选參数来配置的。 |
| join(otherDataset, [numTasks]) | 在类型为(K,V)和(K,W)类型的数据集上调用,返回一个(K,(V,W))对,每一个key中的全部元素都在一起的数据集 |
| groupWith(otherDataset, [numTasks]) | 在类型为(K,V)和(K,W)类型的数据集上调用,返回一个数据集,组成元素为(K, Seq[V], Seq[W]) Tuples。这个操作在其他框架,称为CoGroup |
| cartesian(otherDataset) | 笛卡尔积。但在数据集T和U上调用时,返回一个(T,U)对的数据集,全部元素交互进行笛卡尔积。 |
| sortByKey([ascendingOrder]) | 在类型为( K, V )的数据集上调用,返回以K为键进行排序的(K,V)对数据集。升序或者降序由boolean型的ascendingOrder參数决定 (类似于Hadoop的Map-Reduce中间阶段的Sort,按Key进行排序) |
眼下支持的动作(actions)
| Action | Meaning |
| reduce(func) | 通过函数func聚集数据集中的全部元素。Func函数接受2个參数,返回一个值。这个函数必须是关联性的,确保能够被正确的并发运行 |
| collect() | 在Driver的程序中,以数组的形式,返回数据集的全部元素。这一般会在使用filter或者其他操作后,返回一个足够小的数据子集再使用,直接将整个RDD集Collect返回,非常可能会让Driver程序OOM |
| count() | 返回数据集的元素个数 |
| take(n) | 返回一个数组,由数据集的前n个元素组成。注意,这个操作眼下并不是在多个节点上,并行运行,而是Driver程序所在机器,单机计算全部的元素 (Gateway的内存压力会增大,须要慎重使用) |
| first() | 返回数据集的第一个元素(类似于take(1)) |
| saveAsTextFile(path) | 将数据集的元素,以textfile的形式,保存到本地文件系统,hdfs或者不论什么其他hadoop支持的文件系统。Spark将会调用每一个元素的toString方法,并将它转换为文件里的一行文本 |
| saveAsSequenceFile(path) | 将数据集的元素,以sequencefile的格式,保存到指定的文件夹下,本地系统,hdfs或者不论什么其他hadoop支持的文件系统。RDD的元素必须由key-value对组成,并都实现了Hadoop的Writable接口,或隐式能够转换为Writable(Spark包含了基本类型的转换,比如Int,Double,String等等) |
| foreach(func) | 在数据集的每个元素上,执行函数func。这通经常使用于更新一个累加器变量,或者和外部存储系统做交互 |
两种共享变量之广播变量和累加器
广播变量
broadcastVar: spark.Broadcast[Array[Int]] = spark.Broadcast(b5c40191-a864-4c7d-b9bf-d87e1a4e787c)
scala> broadcastVar.value
res0: Array[Int] = Array(1, 2, 3)
累加器
一个计数器,能够通过调用SparkContext.accumulator(V)方法来创建。执行在集群上的任务,能够使用+=来加值。然而,它们不能读取计数器的值。当Driver程序须要读取值的时候,它能够使用.value方法。
例如以下的解释器,展示了怎样利用累加器,将一个数组里面的全部元素相加
scala> val accum = sc.accumulator(0)
accum: spark.Accumulator[Int] = 0
scala> sc.parallelize(Array(1, 2, 3, 4)).foreach(x => accum += x)
…
10/09/29 18:41:08 INFO SparkContext: Tasks finished in 0.317106 s
scala> accum.value
res2: Int = 10
spark的例子程序
另外,Spark包含了一些例子,在examples/src/main/scala上,有些既有Spark版本号,又有本地非并行版本号,同意你看到假设要让程序以集群化的方式跑起来的话,须要做什么改变。你能够执行它们,通过将类名传递给spark中的run脚本 — 比如./run spark.examples.SparkPi. 每个例子程序,都会打印使用帮助,当执行时没不论什么參数时。
參考资料
1.spark随谈——开发指南(译)http://www.linuxidc.com/Linux/2013-08/88595p2.htm
/*
注:
本文全部内容来自參考资料1。
转载请注明来源:http://blog.csdn.net/ksearch/article/details/24145757
*/