Hive是一个使用SQL对分布式存储上的大数据进行读写和管理的一个数据仓库软件或者框架。本质上讲,就是将SQL转化成MapReduce程序。它具有以下几个特征:
1使用HQL作为查询接口
2使用HDFS 进行存储
3使用MapReduce进行计算
4适合处理离线数据处理
业务架构和系统架构?
提供了一种用比MapReduce更少代码的更简单的查询模式
HQL和 SQL有着类似的语法
提供了很多功能,方便进行数据分析
支持运行在不同的分布式计算框架
支持在HDFS 上进行特别的查询
hbase逻辑结构,对于很多数据或者大数据类型可扩展
允许应用程序拉取Hive数据进行无缝的报告
对于元数据管理,授权和查询优化有比较好的架构
首先:Hive进行查询肯定是没有MapReduce那么快,至少Hive需要将SQL转换成MapReduce程序
其次:Hive 在读取数据文件,不用太关心文件格式,分隔符之类。
最后:开发和维护成本而言,Hive相对较少
功能架构和逻辑架构。所以一般只要不是涉及到对性能有较高的要求,hive是比较合适的,否则MapReduce可能会更优势。因为MapReduce灵活性肯定比hive好一些。
三 为什么说Hive是Hadoop数据仓库
Hive他是一个通过SQL很方便就能访问数据的一个工具,所以他能做一些诸如萃取数据,转化数据和加载数据(ETL),报表和数据分析的工作。所以我们可以简单地认为他是一个数据仓库
四 Hive的数据结构
程序架构、TINYINTSMALLINT INT BIGINT FLOAT DOUBLE DECIMAL BINARY BOOLEAN STRING CHAR VARCHARDATE TIMESTAMP
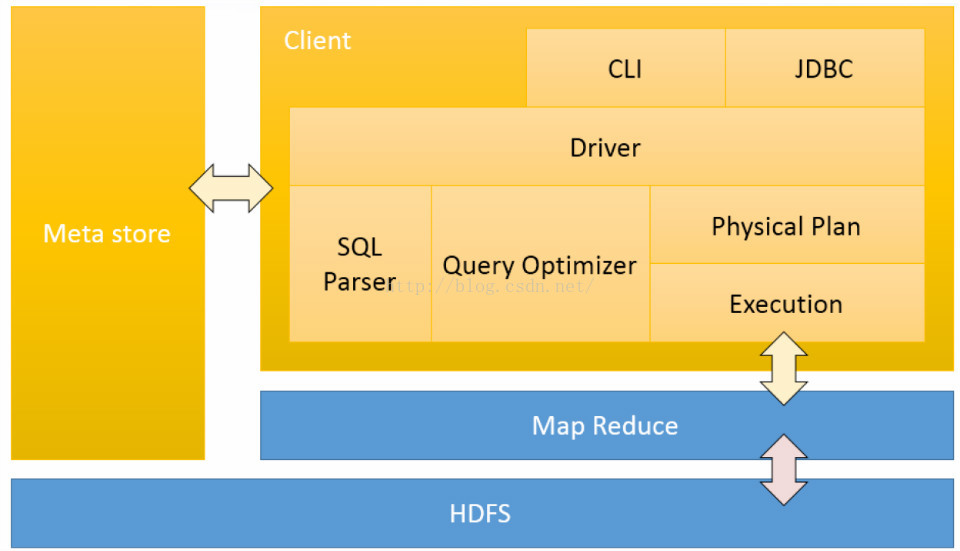
五 Hive的架构
这是Hive架构图.
Hive和Hadoop关系、它主要包含:
Client:客户端包括Hive的Shell,以及JDBC/ODBC和Web UI
MetaStore:存储元数据的地方。包括表名,表所属数据库,表的所有者,列/分区字段,表类型,表所在目录等。
Hadoop:因为hive是基于hadoop的,所以HDFS 用于存储数据,MapReducer用于计算。
Driver:驱动器,接收查询请求。
SQLParser: SQL解析器,将SQL字符串转化成AST(抽象语法树)
maven详解、Compiler:编译器,将AST编译生成执行计划。
QueryOptimizer: 查询优化器对执行计划进行优化
ExecutionEngine: 执行引擎将执行计划转换成物理计划,这些物理计划就是MapReduce,Tez或者Spark.
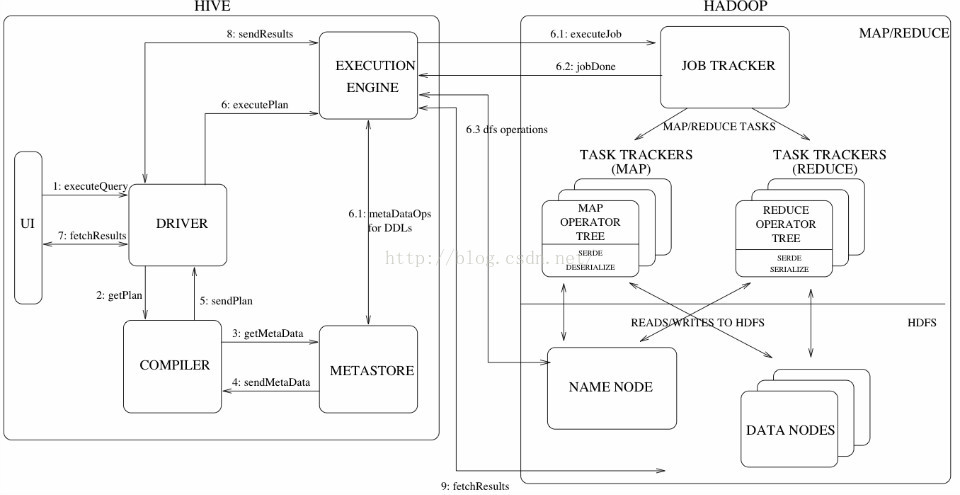
流程图:
Hive优化。
1 执行查询,Driver接受请求
2 Driver从Compier获取执行计划
3 Compiler 向metastore获取元数据
4 MetaStore向Compiler发送元数据
5 Compiler生成执行计划,然后返给Driver
底层架构?6 Execution Engine开始执行Compiler的执行计划
怎么执行的呢?
---- Job Tracker执行job
---- 调用MapReduce任务
---- job完成
---- dfs操作,读或者写HDFS 数据
构架与架构是什么意思、 当然执行任务也可以交给Tez或者Spark去做
7 客户端向Driver获取结果
8 Driver向执行引擎取结果
9 执行引擎从HDFS取结果
然后结果返回。
版权声明:本站所有资料均为网友推荐收集整理而来,仅供学习和研究交流使用。

工作时间:8:00-18:00
客服电话
电子邮件
admin@qq.com
扫码二维码
获取最新动态






![[转]iOS开发使用半透明模糊效果方法整理](http://cc.cocimg.com/api/uploads/20141223/1419302410116248.png)