文章目錄
K-近鄰算法介紹
K近鄰數據樣本分析
K-近鄰快速入門
K-近鄰算法介紹
K最近鄰(k-Nearest Neighbor,KNN)分類算法,是一個理論上比較成熟的方法,也是最簡單的機器學習算法之一。該方法的思路是:如果一個樣本在特征空間中的k個最相似(即特征空間中最鄰近)的樣本中的大多數屬于某一個類別,則該樣本也屬于這個類別
三維空間兩點a(x1,y1,z1)與b(x2,y2,z2)間的歐氏距離, 歐式舉例的本質就是如果兩個樣本之間的特征值越相鄰,則值越小(距離越短)
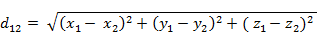
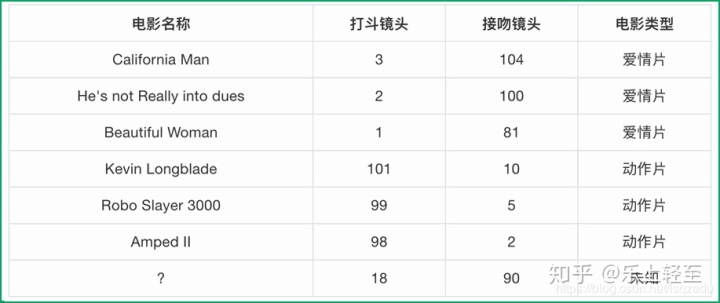
K近鄰數據樣本分析
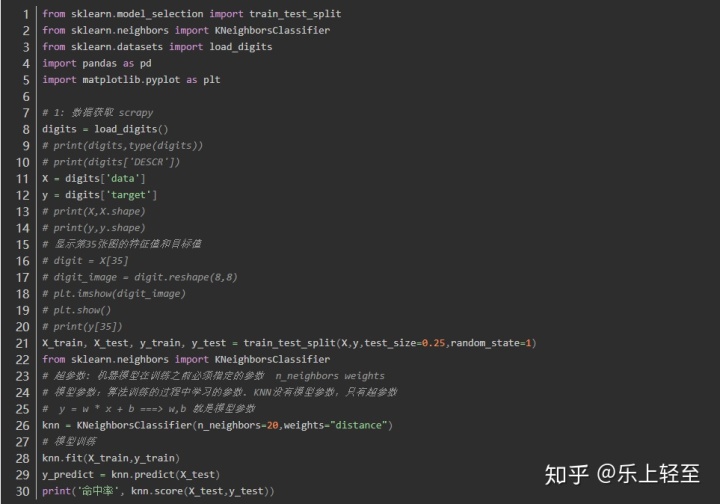
K-近鄰快速入門
通過此案例,理解訓練集與測試集的使用,了解K-近鄰API常用功能,并且掌握K超參數的意義

文章目錄
K近鄰識別圖片
PCA主成分分析
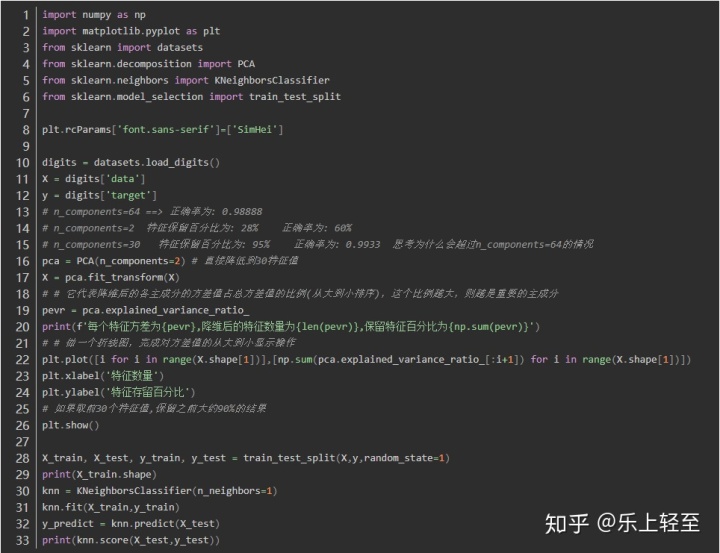
采用PCA降維提示運算效率
K近鄰識別圖片
在本篇文章中我們使用sklearn中自帶的手寫數字數據集(digits),這個數據集中并沒有圖片,而是經過提取得到的手寫數字特征和標記,就免去了我們的提取數據的麻煩,但是在實際的應用中是需要我們對圖片中的數據進行提取的
PCA主成分分析
在很多機器學習算法的復雜度和數據的維度有著密切的關系,甚至與維數呈現指數級關聯。在圖形圖像中機器學習處理成千上萬甚至幾十萬的維度的情況也并不罕見,在這種情況下,機器學習的資源消耗是不可接收的,因此我們必須對數據進行降維處理
主要用于數據的降維 通過降維,可以發現更便于人類理解的特征
其它應用:可視化,去噪音
降維當然意味著信息的丟失,不過鑒于實際數據本身通常存在相關性,我們可以想辦法在降維的同時將信息的損失盡量降低
一些相關性案例
“瀏覽量"和"訪客數” 往往具有較強的相關性
“下單數”和"成交數" 也具有較強的相關性
“學歷”和"學位" 具有較強的相關性
采用PCA降維提示運算效率
文章目錄
為什么使用交叉驗證
交叉驗證原理分析
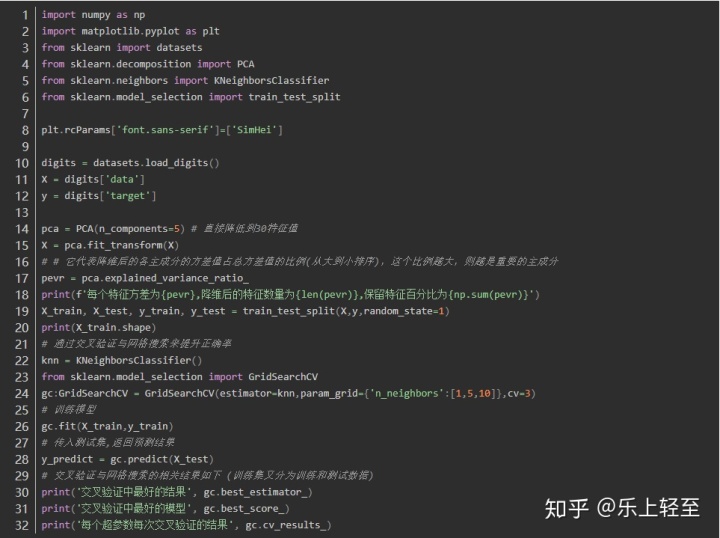
交叉驗證與網格搜索
為什么使用交叉驗證
交叉驗證用于評估模型的性能預測,尤其是訓練好的模型在新數據上的表現
可以在一定程度上減少過擬合 可以從有限的數據中獲取盡可能多的有效信息
評估的正確率相對更穩定
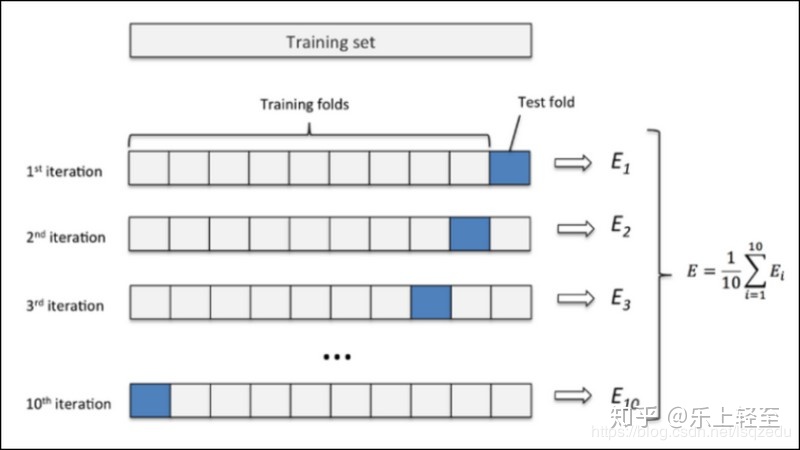
交叉驗證原理分析
交叉驗證,將拿到的訓練數據,分為訓練集和驗證集 (總數據 = (訓練集 (訓練集 + 驗證集) + 測試集),例如:可以將數據分成5份,其中一份作為驗證集。然后經過5次(5組)的測試,每次更換不同的驗證集,得到5組模型的結果。取平均值作為最終結果。又稱為5折交叉驗證
交叉驗證與網格搜索
網格搜索法是指定參數值的一種窮舉搜索方法,通過將估計函數的參數通過交叉驗證的方法進行優化來得到最優的學習算法。


版权声明:本站所有资料均为网友推荐收集整理而来,仅供学习和研究交流使用。

工作时间:8:00-18:00
客服电话
电子邮件
admin@qq.com
扫码二维码
获取最新动态






![BZOJ 4518: [Sdoi2016]征途 [斜率优化DP]](/upload/rand_pic/2-280.jpg)