Hadoop是一個由Apache基金會所開發的分布式系統基礎架構。
用戶可以在不了解分布式底層細節的情況下,開發分布式程序。充分利用集群的威力進行高速運算和存儲。
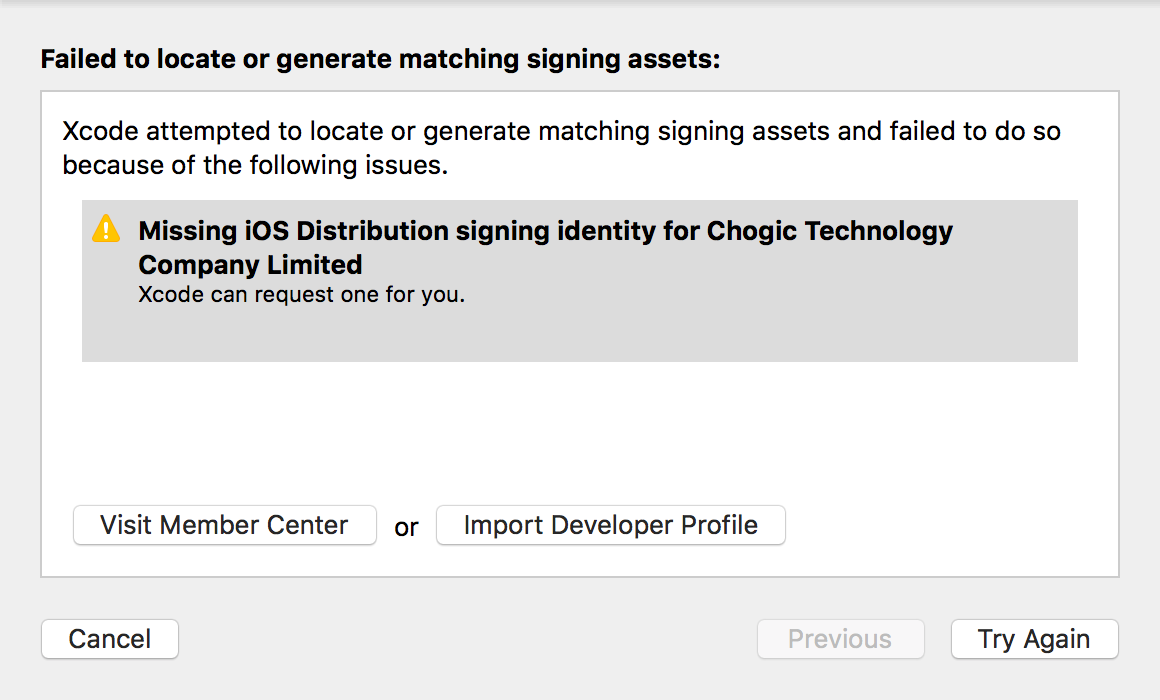
[1] Hadoop實現了一個分布式文件系統(Hadoop Distributed File System),簡稱HDFS。HDFS有高容錯性的特點,并且設計用來部署在低廉的(low-cost)硬件上;而且它提供高吞吐量(high throughput)來訪問應用程序的數據,適合那些有著超大數據集(large data set)的應用程序。HDFS放寬了(relax)POSIX的要求,可以以流的形式訪問(streaming access)文件系統中的數據。mapreduce和hadoop的關系。
MapReduce是一種編程模型,用于大規模數據集(大于1TB)的并行運算。概念"Map(映射)"和"Reduce(歸約)",是它們的主要思想,都是從函數式編程語言里借來的,還有從矢量編程語言里借來的特性。它極大地方便了編程人員在不會分布式并行編程的情況下,將自己的程序運行在分布式系統上。 當前的軟件實現是指定一個Map(映射)函數,用來把一組鍵值對映射成一組新的鍵值對,指定并發的Reduce(歸約)函數,用來保證所有映射的鍵值對中的每一個共享相同的鍵組。hadoop使用?