LinkedHashMap,根據插入值的順序讀取
key和value都可以為null,和hashmap相同
Map<String, String> linkedMap = new LinkedHashMap<String, String>();linkedMap.put("a", "1");linkedMap.put("d", "4");linkedMap.put("b", "2");linkedMap.put("c", "3");linkedMap.put("a", "10");linkedMap.remove("b");linkedMap.put("e", null);linkedMap.put(null, "f");System.out.println("LinkedHashMap:" + linkedMap);//LinkedHashMap:{a=10, d=4, c=3, e=null, null=f}
java遍歷map集合、LinkedHashMap,繼承了HashMap。
public class LinkedHashMap<K,V>extends HashMap<K,V>implements Map<K,V>
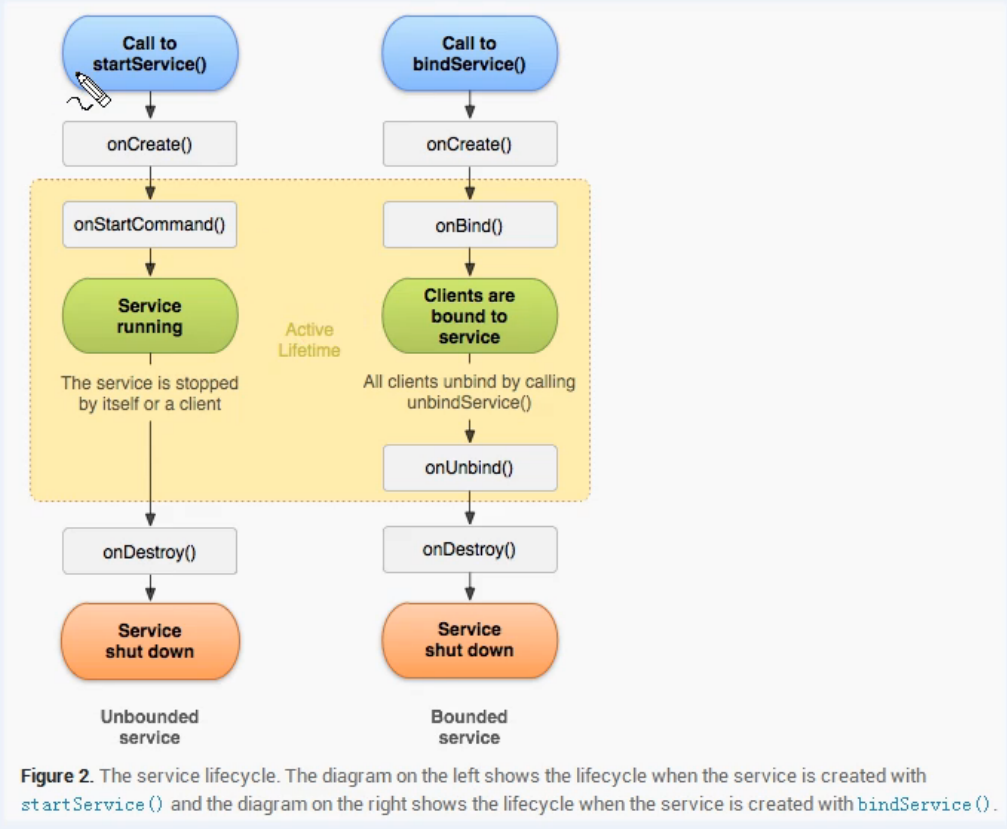
HashMap為了避免碰撞,因此用拉鏈法解決沖突,HashMap中的連接只是同一個桶中的元素連接,而LinkedHashMap是將所有桶中的節點串聯成一個雙向鏈表。
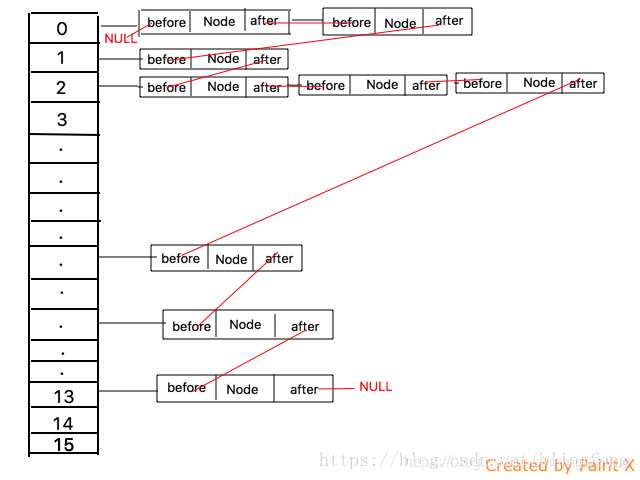
它繼承了HashMap的Node,Node基礎上添加了before和after兩個指針,構成了雙向鏈表
static class Entry<K,V> extends HashMap.Node<K,V> {Entry<K,V> before, after;Entry(int hash, K key, V value, Node<K,V> next) {super(hash, key, value, next);}}
LinkedHashMap使用的是LRU算法(Least Recently Used,最近最少使用) ,當你插入元素時它會將節點插入雙向鏈表的鏈尾,如果key重復,則也會將節點移動至鏈尾,當用get()方法獲取value時也會將節點移動至鏈尾。
構造方法,默認同hashmap一樣,創建容量16,加載因子是0.75的數組,默認是插入順序
//accessOrder默認為false,即按照插入順序來連接,true則為按照訪問順序來連接public LinkedHashMap() {super();accessOrder = false;}
LinkedHashMap使用HashMap的put方法,即使用hashmap的putVal()方法
if ((p = tab[i = (n - 1) & hash]) == null)//調用newNode()方法tab[i] = newNode(hash, key, value, null);else {
其創建節點的方法是newNode()方法,而LinkedHashMap重寫了這個方法:
Node<K,V> newNode(int hash, K key, V value, Node<K,V> e) {LinkedHashMap.Entry<K,V> p =new LinkedHashMap.Entry<K,V>(hash, key, value, e);//將節點插入鏈尾linkNodeLast(p);return p;}private void linkNodeLast(LinkedHashMap.Entry<K,V> p) {LinkedHashMap.Entry<K,V> last = tail;tail = p;// 如果鏈尾為空,則雙向鏈表為空,則p即為頭結點也為尾節點if (last == null)head = p;else {//否則的話修改指針,讓之前鏈尾的after指針指向p,p的before指向之前鏈尾p.before = last;last.after = p;}}
插入新值時將其插入雙向鏈表鏈尾,根據插入值得順序,構成一個順序鏈表
那么接下來put()更新值則節點移動至鏈尾怎么實現的呢?
if (e != null) { // existing mapping for keyV oldValue = e.value;if (!onlyIfAbsent || oldValue == null)e.value = value;//在節點被訪問后移動鏈尾afterNodeAccess(e);return oldValue;}}
如果是默認的插入順序,此方法無效。如果是訪問順序,
void afterNodeAccess(Node<K,V> e) { // move node to lastLinkedHashMap.Entry<K,V> last;if (accessOrder && (last = tail) != e) {LinkedHashMap.Entry<K,V> p =(LinkedHashMap.Entry<K,V>)e, b = p.before, a = p.after;// 因為要移動到鏈尾,所以先至尾指針為空p.after = null;//如果前面沒有元素,則p之前為頭結點,直接讓a成為頭結點if (b == null)head = a;else// 否則b的尾指針指向ab.after = a;if (a != null)//如果a不為空,則a的頭指針指向ba.before = b;else//否則 p之前就為尾指針,則另b成為尾指針last = b;if (last == null)//如果雙向鏈表中只有p一個節點,則令p即為頭結點,也為尾節點head = p;else {//否則 將p插入鏈尾p.before = last;last.after = p;}tail = p;++modCount;}}此外HashMap的putVal()方法,還調用了afterNodeInsertion()方法,
++modCount;if (++size > threshold)resize();afterNodeInsertion(evict);return null;
LinkedHashMap重寫了afterNodeInsertion方法,不過removeEldestEntry()默認是返回false的,需要子類繼承重寫removeEldestEntry()方法。
void afterNodeInsertion(boolean evict) { // possibly remove eldestLinkedHashMap.Entry<K,V> first;if (evict && (first = head) != null && removeEldestEntry(first)) {K key = first.key;removeNode(hash(key), key, null, false, true);}}protected boolean removeEldestEntry(Map.Entry<K,V> eldest) {return false;}
調用的HashMap的remove()方法
public V remove(Object key) {Node<K,V> e;return (e = removeNode(hash(key), key, null, false, true)) == null ?null : e.value;}
removeNode方法中
//回調從雙向鏈表中移除nodeafterNodeRemoval(node);return node;}}return null;}
LinkedHashMap重寫了afterNodeRemoval方法
void afterNodeRemoval(Node<K,V> e) { // unlinkLinkedHashMap.Entry<K,V> p =(LinkedHashMap.Entry<K,V>)e, b = p.before, a = p.after;p.before = p.after = null;if (b == null)head = a;elseb.after = a;if (a == null)tail = b;elsea.before = b;}LinkedHashMap重寫了get()方法,實現了LRU
public V get(Object key) {Node<K,V> e;if ((e = getNode(hash(key), key)) == null)return null;// accessOder為true時,被訪問的節點被置于雙向鏈表尾部if (accessOrder)afterNodeAccess(e);return e.value;}
LinkedHashIterator() {next = head;expectedModCount = modCount;current = null;}public final boolean hasNext() {return next != null;}final LinkedHashMap.Entry<K,V> nextNode() {LinkedHashMap.Entry<K,V> e = next;if (modCount != expectedModCount)throw new ConcurrentModificationException();if (e == null)throw new NoSuchElementException();current = e;next = e.after;return e;}
從頭結點開始,向后開始遍歷
版权声明:本站所有资料均为网友推荐收集整理而来,仅供学习和研究交流使用。

工作时间:8:00-18:00
客服电话
电子邮件
admin@qq.com
扫码二维码
获取最新动态





![谈谈JS里的{ }大括号和[ ]中括号的用法](https://www.oschina.net/img/hot3.png)