python里面的yield怎么用?
yield from是什么意思?
The best way to learn is with examples, and Scrapy is no exception.
常用命令
scrapy startporject
scrapy crawl hello
scrapy shell http://www.qq.com
打开页面
提取数据
保存参数
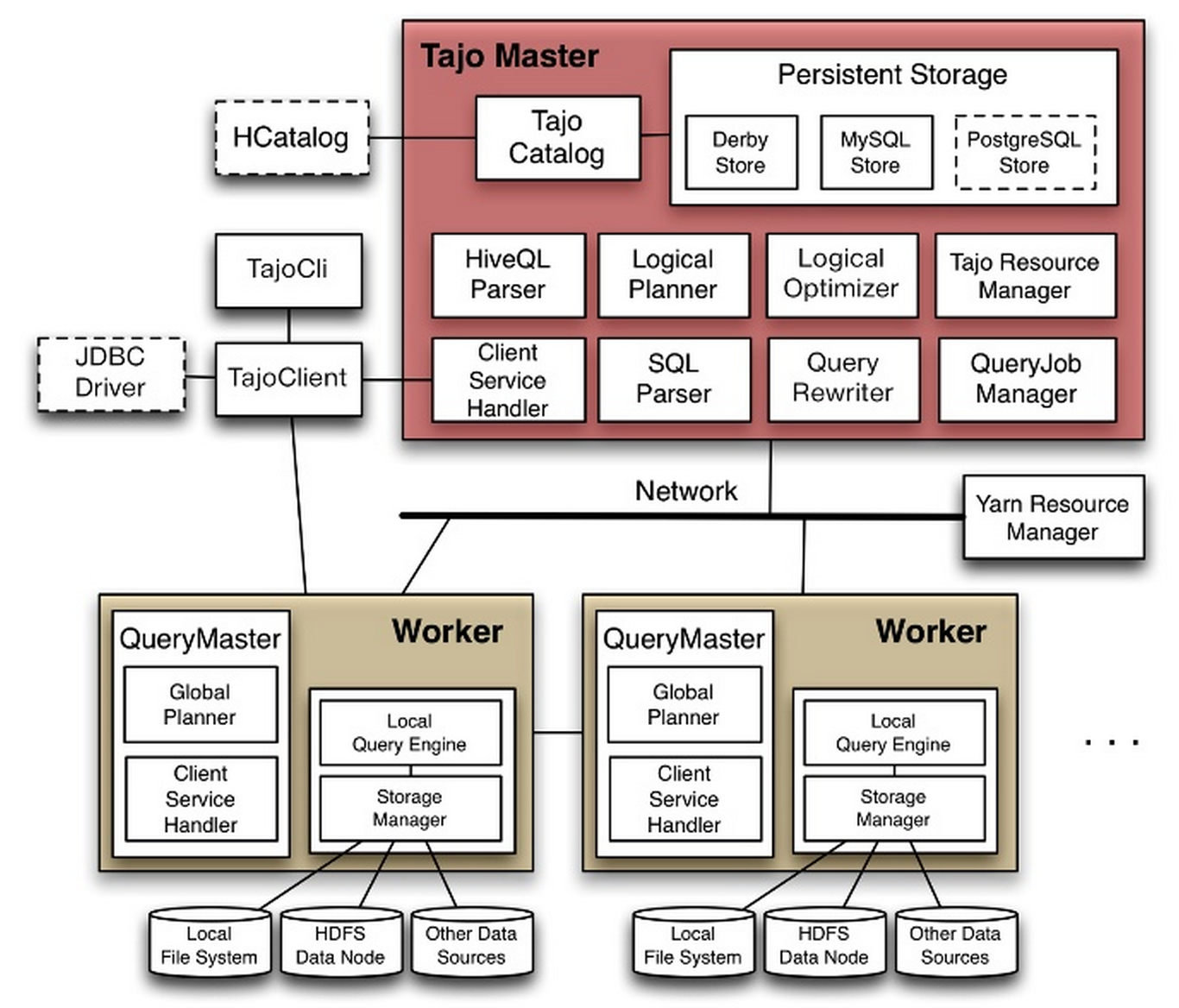
就如同web开发有框架flask spring等等,爬虫也是有框架的,scrapy就是一个爬虫框架,或者说是爬虫引擎。
pip3 install scrapy
以爬取这个网站为例子 quotes.toscrape.com
scrapy startproject tutorial
class QuotesSpider(scrapy.Spider):name = "quotes"def start_requests(self):urls = ['http://quotes.toscrape.com/page/1/','http://quotes.toscrape.com/page/2/',]for url in urls:yield scrapy.Request(url=url, callback=self.parse)def parse(self, response):page = response.url.split("/")[-2]filename = 'quotes-%s.html' % pagewith open(filename, 'wb') as f:f.write(response.body)self.log('Saved file %s' % filename)
解释说明
start_requests()
parse()
运行爬虫
scrapy crawl quotes
保存数据
parse yield的结果可以持久化的保存起来
follow links
首先定位到页面的links,注意这里的links可能是相对的,要进行转换
你可以在parse里面yield scrapy.Request,
response.follow 是Request的快捷写法
使用参数
使用场景,例如外部调用爬虫任务传递一个参数过来
scrapy shell 'http://quotes.toscrape.com/page/1/'view(response) 可以在浏览器里面打开

scrapy可以部署成一个服务吗?
版权声明:本站所有资料均为网友推荐收集整理而来,仅供学习和研究交流使用。

工作时间:8:00-18:00
客服电话
电子邮件
admin@qq.com
扫码二维码
获取最新动态