在上一篇,我们了解了apache druid的搭建,以及如何快速导入外部数据源到apache druid中进行数据分析和使用
本篇,我们结合一个实际的简单的应用场景,来说说apache druid如何在实际项目中进行使用
如下所示,是一个很常见的数据分析的业务,通常来说,很多实时或准实时的数据(这里理解为外部数据源)需要通过kafka进行中转,即发送到kafka中,
kafka 版本、apache druid提供了导入外部数据源的功能,可以接收来自kafka指定topic的数据,然后支持数据分析,将kafka的数据导入到apache druid之后,再通过程序(后台应用)进行数据读取,根据实际的业务需求读取从kafka中摄取的数据进行逻辑处理
最后,应用程序将数据处理之后,进行写库,或者作为大屏展示的数据进行输出
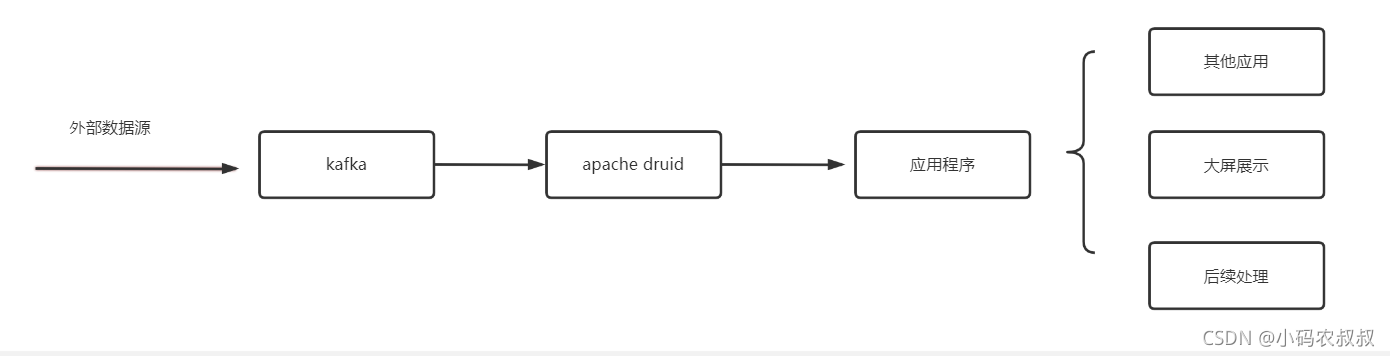
以此为基础,可以将这个过程应用到很多与之相关的场景中,比如源数据是来自大数据引擎的处理结果,或者是python程序爬虫得到的结果…
下面我们来对这个过程从操作到代码实现做一个完整的演示
kafka实战,做一下kafaka的数据测试,验证topic可以正常的收发消息


1、apache druid 控制台连接kafka
loada data 选择kafka
填写kafka的连接信息即可
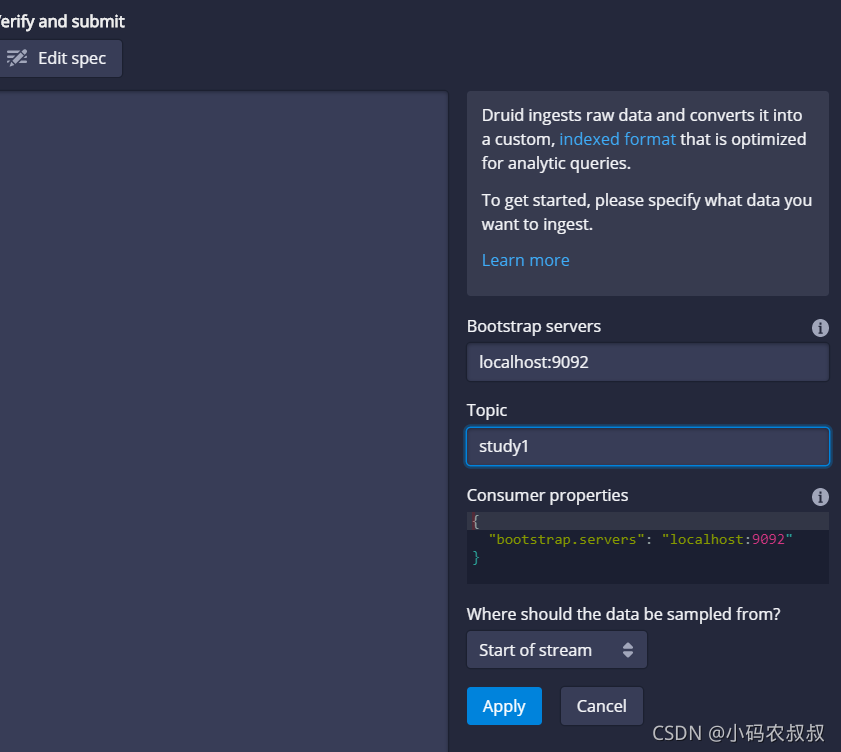
然后一路next等待解析,解析完毕,通过顶部的query查看左侧是否出现下面的这个自定义的库名
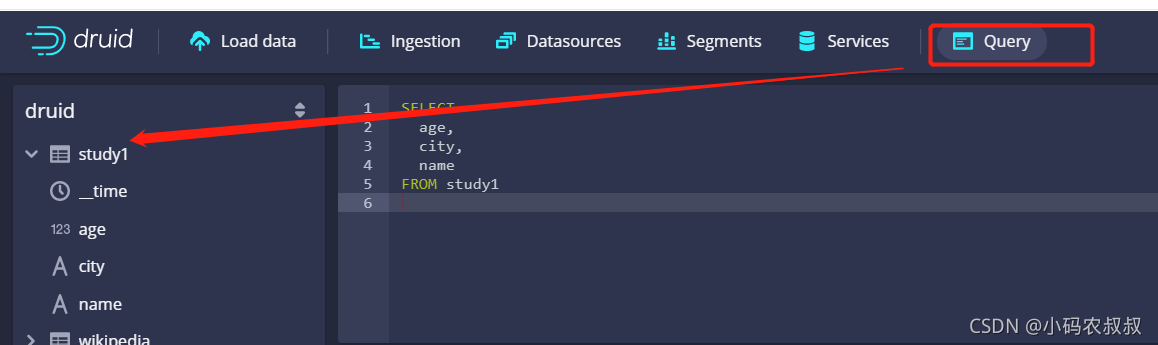
上面的意思是,将kafka中某个topic中的数据解析到apache druid的库中,然后就可以通过apache druid对导入的数据进行管理和分析了
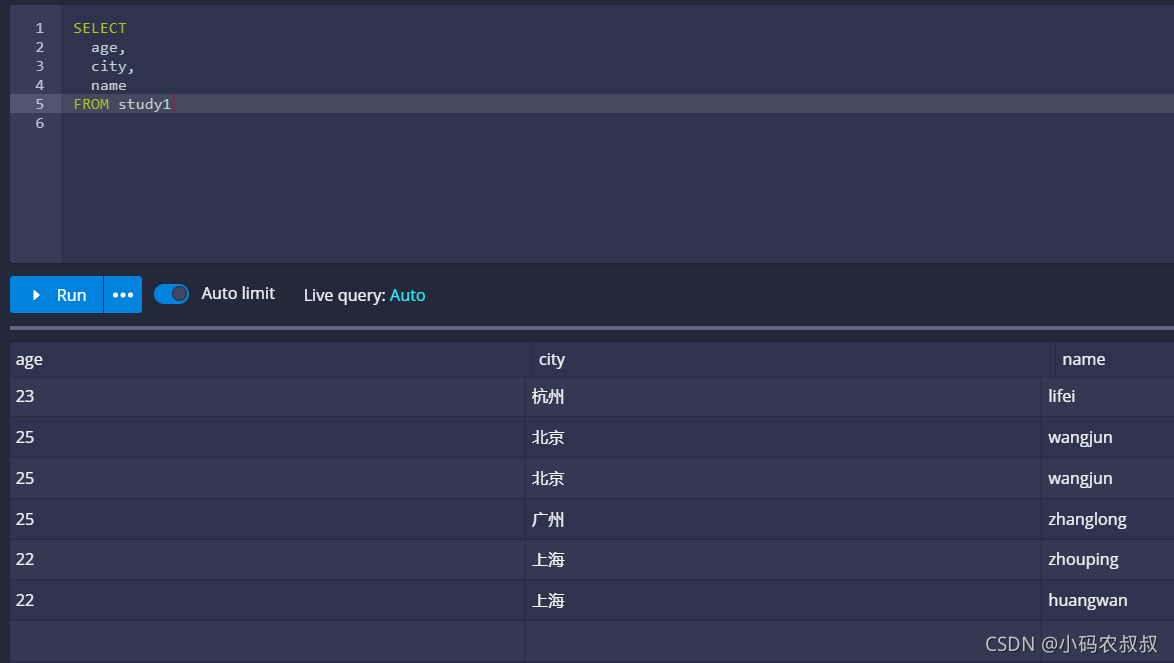
我们不妨使用sql查询一下,可以看到刚刚我们做测试的数据都展示出来了
kafka部署?2、编写程序,定时向kafka推送消息
import com.fasterxml.jackson.core.JsonProcessingException;
import com.fasterxml.jackson.databind.ObjectMapper;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerRecord;import java.util.HashMap;
import java.util.Map;
import java.util.Properties;
import java.util.concurrent.Executors;
import java.util.concurrent.ScheduledExecutorService;
import java.util.concurrent.TimeUnit;
import java.util.concurrent.atomic.AtomicLong;public class KfkaTest {public static void main(String[] args) {AtomicLong atomicLong = new AtomicLong(1);Runnable runnable = new Runnable() {public void run() {//定时向kafka推送消息long l = atomicLong.incrementAndGet();pushMessage(l);}};ScheduledExecutorService service = Executors.newSingleThreadScheduledExecutor();// 第二个参数为首次执行的延时时间,第三个参数为定时执行的间隔时间service.scheduleAtFixedRate(runnable, 10, 1, TimeUnit.SECONDS);}public static void pushMessage(long num) {Properties properties = new Properties();properties.put("bootstrap.servers", "IP:9092");properties.put("acks", "all");properties.put("retries", "3");properties.put("batch.size", "16384");properties.put("linger.ms", 1);properties.put("buffer.memory", 33554432);//key和value的序列化properties.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");properties.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");//构造生产者对象KafkaProducer<String, String> producer = new KafkaProducer<>(properties);ObjectMapper objectMapper = new ObjectMapper();Map<String, Object> map = new HashMap<>();map.put("name", "gaoliang:" + num);map.put("age", 19);map.put("city", "深圳");String val = null;try {val = objectMapper.writeValueAsString(map);System.out.println(val);} catch (JsonProcessingException e) {e.printStackTrace();}producer.send(new ProducerRecord<>("study1", "congge ", val));//关闭连接资源producer.close();}}
3、通过程序读取apache druid 的数据
关于这一点,方式就很灵活了,是将读取到的数据做何种处理呢?那就要看业务的具体需求了,比如可以直接通过接口将读取到的最新数据返回给页面做展示呢?还是将数据进行逻辑处理之后入库呢?还是交给其他的服务进一步使用呢?通常来说,进行读取之后,写库和展示的应用场景比较多
下面来演示下,如何在程序中读取apache druid的数据,想必这个是大家关心的
apache kafka实战。直接在pom文件中添加如下依赖
<dependency><groupId>org.apache.calcite.avatica</groupId><artifactId>avatica-core</artifactId><version>1.15.0</version></dependency>
apache druid官方提供了jdbc的方式对数据进行查询的连接方式,下面直接上代码了
import org.apache.calcite.avatica.AvaticaConnection;
import org.apache.calcite.avatica.AvaticaStatement;import java.sql.DriverManager;
import java.sql.ResultSet;
import java.sql.SQLException;
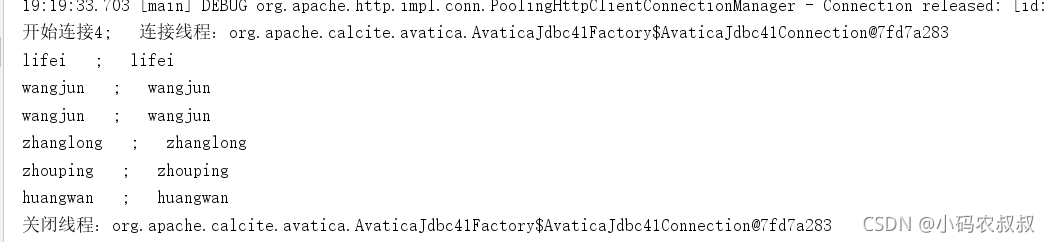
import java.util.Properties;public class DruidTest {private static final String DRUID_URL = "jdbc:avatica:remote:url=http://IP:8888/druid/v2/sql/avatica/";private static ThreadLocal<AvaticaConnection> threadLocal = new ThreadLocal<>();/*** 打开连接* @param* @return* @throws SQLException*/public static AvaticaConnection connection() throws SQLException {Properties properties = new Properties();AvaticaConnection connection = (AvaticaConnection) DriverManager.getConnection(DRUID_URL, properties);threadLocal.set(connection);return connection;}/*** 关闭连接* @throws SQLException*/public static void closeConnection() throws SQLException{System.out.println("关闭线程:"+threadLocal.get());AvaticaConnection conn = threadLocal.get();if(conn != null){conn.close();threadLocal.remove();}}/*** 根据sql查询结果* @param* @param sql* @return* @throws SQLException*/public static ResultSet executeQuery (String sql) throws SQLException{AvaticaStatement statement = connection().createStatement();ResultSet resultSet = statement.executeQuery(sql);return resultSet;}public static void main(String[] args) {try {String sql = "SELECT * FROM \"study1\" limit 10";for (int i = 0; i < 5; i++) {ResultSet resultSet = executeQuery(sql);System.out.println("开始连接"+i + "; 连接线程:"+threadLocal.get());while(resultSet.next()){String name = resultSet.getString("name");System.out.println(name + " ; "+ name);}closeConnection();}} catch (SQLException throwables) {throwables.printStackTrace();}}}
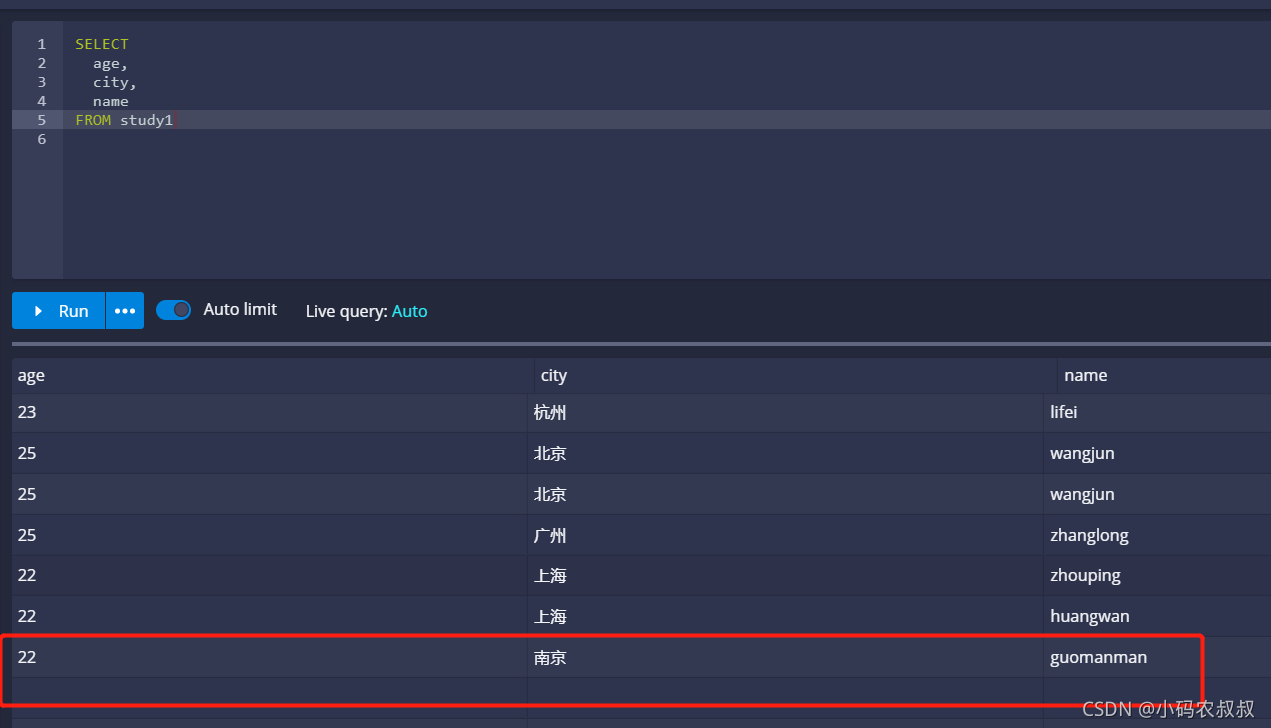
这时候不妨往kafka的study1的topic中再推一条消息

界面上查询,可以看到,数据已经过来了
再次运行程序,也能成功读取到

kafka 教程,以上,通过程序结合控制台讲述了如何利用java程序连接kafka和apache druid的一种简单的业务场景,本篇的处理较为简单,未涉及到具体的功能层面的整合,主要是为使用apache druid进行进一步的深入使用做一个铺垫,希望对看到的同学有用!
版权声明:本站所有资料均为网友推荐收集整理而来,仅供学习和研究交流使用。

工作时间:8:00-18:00
客服电话
电子邮件
admin@qq.com
扫码二维码
获取最新动态