實時數倉建設目的
實時數倉是一個很容易讓人產生混淆的概念。實時數倉本身似乎和把 PPT 黑色的背景變得更白一樣,從傳統的經驗來講,我們認為數倉有一個很重要的功能,即能夠記錄歷史。通常,數倉都是希望從業務上線的第一天開始有數據,然后一直記錄到現在。
但實時處理技術,又是強調當前處理狀態的一門技術,所以我們認為這兩個相對對立的方案重疊在一起的時候,它注定不是用來解決一個比較廣泛問題的一種方案。于是,我們把實時數倉建設的目的定位為解決由于傳統數據倉庫數據時效性低解決不了的問題。
flink可視化開發平臺、由于這個特點,我們給定了兩個原則:
當然為了讓我們整個系統看起來像是一個數倉,我們還是給自己提了一些要求的。這個要求其實跟我們建立離線數倉的要求是一樣的,首先實時的數倉是需要面向主題的,然后具有集成性,并且保證相對穩定。
離線數倉和實時數倉的區別在于離線數據倉庫是一個保存歷史累積的數據,而我們在建設實時數倉的時候,我們只保留上一次批處理到當前的數據。這個說法非常的拗口,但是實際上操作起來還是蠻輕松的。
通常來講解決方案是保留大概三天的數據,因為保留三天的數據的話,可以穩定地保證兩天完整的數據,這樣就能保證,在批處理流程還沒有處理完昨天的數據的這段間隙,依然能夠提供一個完整的數據服務。

dw實時視圖和設計不一樣、OLAP 分析本身就非常適合用數倉去解決的一類問題,我們通過實時數倉的擴展,把數倉的時效性能力進行提升。甚至可能在分析層面上都不用再做太多改造,就可以使原有的 OLAP 分析工具具有分析實時數據的能力。
這種場景比較容易接受,比如天貓雙11的實時大屏滾動展示核心數據的變化。實際上對于美團來講,不光有促銷上的業務,還有一些主要的門店業務。對于門店的老板而言,他們可能在日常的每一天中也會很關心自己當天各個業務線上的銷售額。
實時特征指通過匯總指標的運算來對商戶或者用戶標記上一些特征。比如多次購買商品的用戶后臺會判定為優質用戶。另外,商戶銷售額高,后臺會認為該商戶商的熱度更高。然后,在做實時精準運營動作時可能會優先考慮類似的門店或者商戶。
美團點評也會對一些核心業務指標進行監控,比如說當線上出現一些問題的時候,可能會導致某些業務指標下降,我們可以通過監控盡早發現這些問題,進而來減少損失。
dreamweaver的各種視圖。如何建設實時數倉
我們通過離線數倉開發和實時數倉開發的對應關系表,幫助大家快速清晰的理解實時數倉的一些概念。

離線開發最常見的方案就是采用 Hive SQL 進行開發,然后加上一些擴展的 udf 。映射到實時數倉里來,我們會使用 Flink SQL ,同樣也是配合 udf 來進行開發。
離線處理的執行層面一般是 MapReduce 或者 Spark Job ,對應到實時數倉就是一個持續不斷運行的 Flink Streaming 的程序。
美團升級webview組件,離線數倉實際上就是在使用 Hive 表。對于實時數倉來講,我們對表的抽象是使用 Stream Table 來進行抽象。
離線數倉,我們多數情況下會使用 HDFS 進行存儲。實時數倉,我們更多的時候會采用像 Kafka 這樣的消息隊列來進行數據的存儲。
在此之前我們做過一次分享,是關于為什么選擇 Flink 來做實時數倉,其中重點介紹了技術組件選型的原因和思路,具體內容參考《美團點評基于 Flink 的實時數倉建設實踐》。本文分享的主要內容是圍繞數據本身來進行的,下面是我們目前的實時數倉的數據架構圖。
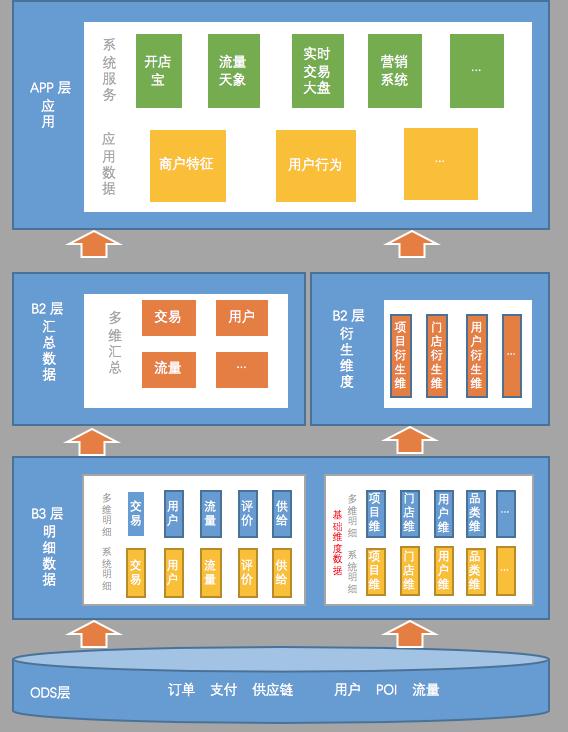
從數據架構圖來看,實時數倉的數據架構會跟離線數倉有很多類似的地方。比如分層結構;比如說 ODS 層,明細層、匯總層,乃至應用層,它們命名的模式可能都是一樣的。盡管如此,實時數倉和離線數倉還是有很多的區別的。
美團外賣津貼每個人不一樣、跟離線數倉主要不一樣的地方,就是實時數倉的層次更少一些。
以我們目前建設離線數倉的經驗來看,數倉的第二層遠遠不止這么簡單,一般都會有一些輕度匯總層這樣的概念,其實第二層會包含很多層。另外一個就是應用層,以往建設數倉的時候,應用層其實是在倉庫內部的。在應用層建設好后,會建同步任務,把數據同步到應用系統的數據庫里。
在實時數倉里面,所謂 APP 層的應用表,實際上就已經在應用系統的數據庫里了。上圖,雖然畫了 APP 層,但它其實并不算是數倉里的表,這些數據本質上已經存過去了。
為什么主題層次要少一些?是因為在實時處理數據的時候,每建一個層次,數據必然會產生一定的延遲。
美團價格不一樣?為什么匯總層也會盡量少建?是因為在匯總統計的時候,往往為了容忍一部分數據的延遲,可能會人為的制造一些延遲來保證數據的準確。
舉例,統計事件中的數據時,可能會等到 10:00:05 或者 10:00:10再統計,確保 10:00 前的數據已經全部接受到位了,再進行統計。所以,匯總層的層次太多的話,就會更大的加重人為造成的數據延遲。
建議盡量減少層次,特別是匯總層一定要減少,最好不要超過兩層。明細層可能多一點層次還好,會有這種系統明細的設計概念。
第二個比較大的不同點就是在于數據源的存儲。
餓了么好還是美團好?在建設離線數倉的時候,可能整個數倉都全部是建立在 Hive 表上,都是跑在 Hadoop 上。但是,在建設實時數倉的時候,同一份表,我們甚至可能會使用不同的方式進行存儲。
比如常見的情況下,可能絕大多數的明細數據或者匯總數據都會存在 Kafka 里面,但是像維度數據,可能會存在像 Tair 或者 HBase 這樣的 kv 存儲的系統中,實際上可能匯總數據也會存進去,具體原因后面詳細分析。除了整體結構,我們也分享一下每一層建設的要點。
數據來源盡可能統一
利用分區保證數據局部有序

首先第一個建設要點就是 ODS 層,其實 ODS 層建設可能跟倉庫不一定有必然的關系,只要使用 Flink 開發程序,就必然都要有實時的數據源。目前主要的實時數據源是消息隊列,如 Kafka。而我們目前接觸到的數據源,主要還是以 binlog、流量日志和系統日志為主。
這里面我主要想講兩點:
首先第一個建設要點就是 ODS層,其實ODS層建設可能跟這個倉庫不一定有必然的關系,只要你使用這個flink開發程序,你必然都要有這種實時的數據源。目前的主要的實時數據源就是消息隊列,如kafka。我們目前接觸到的數據源,主要還是以binlog、流量日志和系統日志為主。
這里面我主要想講兩點,一個這么多數據源我怎么選?我們認為以數倉的經驗來看:
首先就是數據源的來源盡可能要統一。這個統一有兩層含義:
第二個要點就是數據亂序的問題,我們在采集數據的時候會有一個比較大的問題,可能同一條數據,由于分區的存在,這條數據先發生的狀態后消費到,后發生的狀態先消費到。我們在解決這一問題的時候采用的是美團內部的一個數據組件。
其實,保證數據有序的主要思路就是利用 kafka 的分區來保證數據在分區內的局部有序。至于具體如何操作,可以參考《美團點評基于 Flink 的實時數倉建設實踐》。這是我們美團數據同步部門做的一套方案,可以提供非常豐富的策略來保證同一條數據是按照生產順序進行保序消費的,實現在源頭解決數據亂序的問題。
解決原始數據中數據存在噪聲、不完整和數據形式不統一的情況。形成規范,統一的數據源。如果可能的話盡可能和離線保持一致。
明細層的建設思路其實跟離線數倉的基本一致,主要在于如何解決 ODS 層的數據可能存在的數據噪聲、不完整和形式不統一的問題,讓它在倉庫內是一套滿足規范的統一的數據源。我們的建議是如果有可能的話,最好入什么倉怎么入倉,這個過程和離線保持一致。
尤其是一些數據來源比較統一,但是開發的邏輯經常變化的系統,這種情況下,我們可能采用的其實是一套基于配置的入倉規則。可能離線的同學有一套入倉的系統,他們配置好規則就知道哪些數據表上數據要進入實時數倉,以及要錄入哪些字段,然后實時和離線是采用同一套配置進行入倉,這樣就可以保證我們的離線數倉和實時數倉在 DW 層長期保持一個一致的狀態。
實際上建設 DW 層其實主要的工作主要是以下4部分。

唯一標紅的就是模型的規范化,其實模型的規范化,是一個老生常談的問題,可能每個團隊在建設數倉之前,都會先把自己的規范化寫出來。但實際的結果是我們會看到其實并不是每一個團隊最終都能把規范落地。
在實時的數倉建設當中,我們要特別強調模型的規范化,是因為實施數倉有一個特點,就是本身實時作業是一個7×24 小時調度的狀態,所以當修改一個字段的時候,可能要付出的運維代價會很高。在離線數倉中,可能改了某一個表,只要一天之內把下游的作業也改了,就不會出什么問題。但是實時數倉就不一樣了,只要改了上游的表結構,下游作業必須是能夠正確解析上游數據的情況下才可以。
另外使用像 kafka 這樣的系統,它本身并不是結構化的存儲,沒有元數據的概念,也不可能像改表一樣,直接把之前不規范的表名、表類型改規范。要在事后進行規范代價會很大。所以建議一定要在建設之初就盡快把這些模型的規范化落地,避免后續要投入非常大的代價進行治理。
除了數據本身我們會在每條數據上額外補充一些信息,應對實時數據生產環節的一些常見問題

我們會給每一條數據都補充一個唯一鍵和一個主鍵,這兩個是一對的,唯一鍵就是標識是唯一一條數據的,主鍵是標記為一行數據。一行數據可能變化很多次,但是主鍵是一樣的,每一次變化都是其一次唯一的變化,所以會有一個唯一鍵。唯一鍵主要解決的是數據重復問題,從分層來講,數據是從我們倉庫以外進行生產的,所以很難保證我們倉庫以外的數據是不會重復的。
可能有些人交付數據給也會告知數據可能會有重復。生成唯一鍵的意思是指我們需要保證 DW 層的數據能夠有一個標識,來解決可能由于上游產生的重復數據導致的計算重復問題。生成主鍵,其實最主要在于主鍵在 kafka 進行分區操作,跟之前接 ODS 保證分區有序的原理是一樣的,通過主鍵,在 kafka 里進行分區之后,消費數據的時候就可以保證單條數據的消費是有序的。
版本和批次這兩個其實又是一組。當然這個內容名字可以隨便起,最重要的是它的邏輯。
首先,版本。版本的概念就是對應的表結構,也就是 schema 一個版本的數據。由于在處理實時數據的時候,下游的腳本依賴表上一次的 schema 進行開發的。當數據表結構發生變化的時候,就可能出現兩種情況:第一種情況,可能新加或者刪減的字段并沒有用到,其實完全不用感知,不用做任何操作就可以了。另外一種情況,需要用到變動的字段。此時會產生一個問題,在 Kafka 的表中,就相當于有兩種不同的表結構的數據。這時候其實需要一個標記版本的內容來告訴我們,消費的這條數據到底應該用什么樣的表結構來進行處理,所以要加一個像版本這樣的概念。
第二,批次。批次實際上是一個更不常見的場景,有些時候可能會發生數據重導,它跟重啟不太一樣,重啟作業可能就是改一改,然后接著上一次消費的位置啟動。而重導的話,數據消費的位置會發生變化。
比如,今天的數據算錯了,領導很著急讓我改,然后我需要把今天的數據重算,可能把數據程序修改好之后,還要設定程序,比如從今天的凌晨開始重新跑。這個時候由于整個數據程序是一個 7x24 小時的在線狀態,其實原先的數據程序不能停,等重導的程序追上新的數據之后,才能把原來的程序停掉,最后使用重導的數據來更新結果層的數據。
在這種情況下,必然會短暫的存在兩套數據。這兩套數據想要進行區分的時候,就要通過批次來區分。其實就是所有的作業只消費指定批次的數據,當重導作業產生的時候,只有消費重導批次的作業才會消費這些重導的數據,然后數據追上之后,只要把原來批次的作業都停掉就可以了,這樣就可以解決一個數據重導的問題。
其次就是維度數據,我們的明細層里面包括了維度數據。關于維度的數據的處理,實際上是先把維度數據分成了兩大類采用不同的方案來進行處理。
第一類數據就是一些變化頻率比較低的數據,這些數據其實可能是一些基本上是不會變的數據。比如說,一些地理的維度信息、節假日信息和一些固定代碼的轉換。

這些數據實際上我們采用的方法就是直接可以通過離線倉庫里面會有對應的維表,然后通過一個同步作業把它加載到緩存中來進行訪問。還有一些維度數據創建得會很快,可能會不斷有新的數據創建出來,但是一旦創建出來,其實也就不再會變了。
比如說,美團上開了一家新的門店,門店所在的城市名字等這些固定的屬性,其實可能很長時間都不會變,取最新的那一條數據就可以了。這種情況下,我們會通過公司內部的一些公共服務,直接去訪問當前最新的數據。最終,我們會包一個維度服務的這樣一個概念來對用戶進行屏蔽,具體是從哪里查詢相關細節,通過維度服務即可關聯具體的維度信息。
第二類是一些變化頻率較高的數據。比如常見的病人心腦科的狀態變動,或者某一個商品的價格等。這些東西往往是會隨著時間變化比較頻繁,比較快。而對于這類數據,我們的處理方案就稍微復雜一點。首先對于像價格這樣變化比較頻繁的這種維度數據,會監聽它的變化。比如說,把價格想象成維度,我們會監聽維度價格變化的消息,然后構建一張價格變換的拉鏈表。
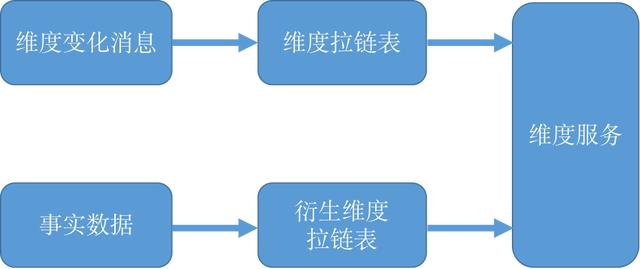
一旦建立了維度拉鏈表,當一條數據來的時候,就可以知道,在這個數據某一時刻對應的準確的維度是多少,避免了由于維度快速的變化導致關聯錯維度的問題。
另一類如新老客這維度,于我們而言其實是一種衍生維度,因為它本身并不是維度的計算方式,是用該用戶是否下過單來計算出來的,所以它其實是用訂單數據來算出來的一個維度。
所以類似訂單數的維度,我們會在 DW 層建立一些衍生維度的計算模型,然后這些計算模型輸出的其實也是拉鏈表,記錄下一個用戶每天這種新老客的變化程度,或者可能是一個優質用戶的變化的過程。由于建立拉鏈表本身也要關聯維度,所以可以通過之前分組 key 的方式來保障不亂序,這樣還是將其當做一個不變的維度來進行關聯。
通過這種方式來建立拉鏈表相對麻煩,所以實際上建議利用一些外部組件的功能。實際操作的時候,我們使用的是 Hbase。HBase 本身支持數據多版本的,而且它能記錄數據更新的時間戳,取數據的時候,甚至可以用這個時間戳來做索引。
所以實際上只要把數據存到 HBase 里,再配合上 mini-versions ,就可以保證數據不會超時死掉。上面也提到過,整個實時數倉有一個大原則,不處理離線數倉能處理的過程。相當于處理的過程,只需要處理三天以內的數據,所以還可以通過配置 TTL 來保證 HBase 里的這些維度可以盡早的被淘汰掉。因為很多天以前的維度,實際上也不會再關聯了,這樣就保證維度數據不會無限制的增長,導致存儲爆炸。
處理維度數據之后,這個維度數據怎么用?

第一種方案,也是最簡單的方案,就是使用 UDTF 關聯。其實就是寫一個 UDTF 去查詢上面提到的維度服務,具體來講就是用 LATERAL TABLE 關鍵詞來進行關聯,內外關聯都是支持的。
另外一種方案就是通過解析 SQL ,識別出關聯的維表以及維表中的字段,把它原本的查詢進行一次轉化為原表.flatmap (維表),最后把整個操作的結果轉換成一張新的表來完成關聯操作。
但是這個操作要求使用者有很多周邊的系統來進行配合,首先需要能解析 SQL ,同時還能識別文本,記住所有維表的信息,最后還要可以執行 SQL 轉化,所以這套方案適合一些已經有成熟的基于 Flink SQL 的 SQL開發框架的系統來使用。如果只是單純的寫封裝的代碼,建議還是使用 UDTF 的方式來進行關聯會非常的簡單,而且效果也是一樣的。
在建設實時數倉的匯總層的時候,跟離線的方案其實會有很多一樣的地方。
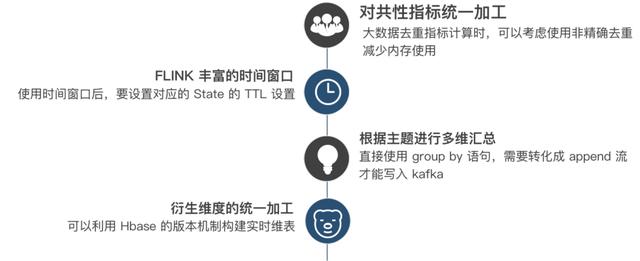
第一點是對于一些共性指標的加工,比如說 pv、uv、交易額這些運算,我們會在匯總層進行統一的運算。另外,在各個腳本中多次運算,不僅浪費算力,同時也有可能會算錯,需要確保關于指標的口徑是統一在一個固定的模型里面的。本身 Flink SQL 已經其實支持了非常多的計算方法,包括這些 count distinct 等都支持。
值得注意的一點是,它在使用 count distinct 的時候,他會默認把所有的要去重的數據存在一個 state 里面,所以當去重的基數比較大的時候,可能會吃掉非常多的內存,導致程序崩潰。這個時候其實是可以考慮使用一些非精確系統的算法,比如說 BloomFilter 非精確去重、 HyperLogLog 超低內存去重方案,這些方案可以極大的減少內存的使用。
第二點就是 Flink 比較有特色的一個點,就是 Flink 內置非常多的這種時間窗口。Flink SQL 里面有翻滾窗口、滑動窗口以及會話窗口,這些窗口在寫離線 SQL 的時候是很難寫出來的,所以可以開發出一些更加專注的模型,甚至可以使用一些在離線開發當中比較少使用的一些比較小的時間窗口。
比如說,計算最近10分鐘的數據,這樣的窗口可以幫助我們建設一些基于時間趨勢圖的應用。但是這里面要注意一點,就是一旦使用了這個時間窗口,要配置對應的 TTL 參數,這樣可以減少內存的使用,提高程序的運行效率。另外,如果 TTL 不夠滿足窗口的話,也有可能會導致數據計算的錯誤。
第三點,在匯總層進行多維的主題匯總,因為實時倉庫本身是面向主題的,可能每一個主題會關心的維度都不一樣,所以我們會在不同的主題下,按照這個主題關心的維度對數據進行一些匯總,最后來算之前說過的那些匯總指標。但是這里有一個問題,如果不使用時間窗口的話,直接使用 group by ,它會導致生產出來的數據是一個 retract 流,默認的 kafka 的 sink 它是只支持 append 模式,所以在這里要進行一個轉化。
如果想把這個數據寫入 kafka 的話,需要做一次轉化,一般的轉化方案實際上是把撤回流里的 false 的過程去掉,把 true 的過程保存起來,轉化成一個 append stream ,然后就可以寫入到 kafka 里了。
第四點,在匯總層會做一個比較重要的工作,就是衍生維度的加工。如果衍生維度加工的時候可以利用 HBase 存儲,HBase 的版本機制可以幫助你更加輕松地來構建一個這種衍生維度的拉鏈表,可以幫助你準確的 get 到一個實時數據當時的準確的維度。
倉庫質量保證
經過上面的環節,如果你已經建立好了一個倉庫,你會發現想保證倉庫的正常的運行或者是保證它高質量的運行,其實是一個非常麻煩的過程,它要比一線的操作復雜得多,所以我們在建設完倉庫之后,需要建設很多的周邊系統來提高我們的生產效率。
下面介紹一下我們目前使用的一些工具鏈系統,工具鏈系統的功能結構圖如下圖。
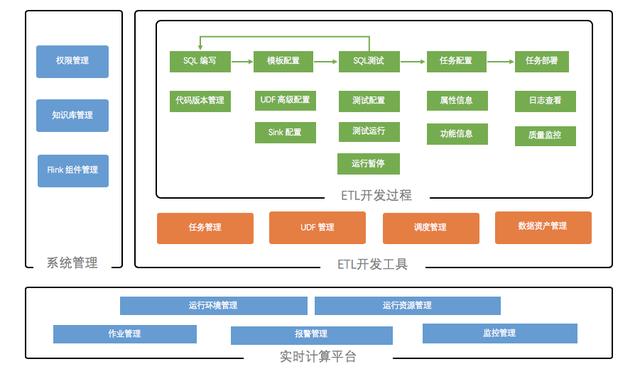
首先,工具鏈系統包括一個實時計算平臺,主要的功能是統一提交作業和一些資源分配以及監控告警,但是實際上無論是否開發數倉,大概都需要這樣的一個工具,這是開發 Flink 的基本工具。
對于我們來講,跟數倉相關的主要工具有兩塊:
其實整個這條工具鏈,每個工具都有它自己特定的用場場景,下面重點講解其中兩個。
■ 元數據管理
我們在 Flink SQL 的開發過程中,每一個任務都要重新把元數據重新寫一遍。因為 kafka 以及很多的緩存組件,如 Tair、Redis 都不支持元數據的管理,所以我們一定要盡早建設元數據管理系統。
■ 血緣管理
血緣其實對于實時數倉來講比較重要,在上文中也提到過,在實時的作業的運維過程當中,一旦對自己的作業進行了修改,必須保證下游都是能夠準確的解析新數據的這樣一個情況。如果是依賴于這種人腦去記憶,比如說誰用我的銷售表或者口頭通知這種方式來講的話,效率會非常的低,所以一定要建立一套就是血緣的管理機制。要知道到底是誰用了生產的表,然后上游用了誰的,方便大家再進行修改的時候進行周知,保證我們整個實時數倉的穩定。
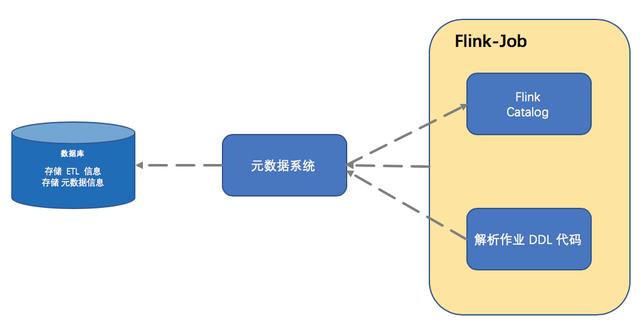
元數據和血緣管理系統,最簡單的實現方式大概分為以下三點:
首先通過元數據系統,把元數據系統里的元數據信息加載到程序中來,然后生成 Flink Catalog 。這樣就可以知道當前作業可以消費哪些表,使用哪些表。
當作業進行一系列操作,最終要輸出某張表的時候,解析作業里面關于輸出部分的 DDL 代碼,創建出新的元數據信息寫入到元數據系統。
作業本身的元數據信息以及它的運行狀態也會同步到元數據系統里面來,讓這些信息來幫助我們建立血緣關系。
最終的系統可以通過數據庫來存儲這些信息,如果你設計的系統沒那么復雜,也可以使用文件來進行存儲。重點是需要盡快建立一套這樣的系統,不然在后續的開發和運維過程當中都會非常的痛苦。
將實時數據寫入 Hive,使用離線數據持續驗證實時數據的準確性。
當建設完一個數倉之后,尤其是第一次建立之后,一定會非常懷疑自己數據到底準不準。在此之前的驗證方式就是通過寫程序去倉庫里去查,然后來看數據對不對。在后續的建設過程中我們發現每天這樣人為去對比太累了。
我們就采取了一個方案,把中間層的表寫到 Hive 里面去,然后利用離線數據豐富的質量驗證工具去對比離線和實時同一模型的數據差異,最后根據設定的閾值進行監控報警。這個方案雖然并不能及時的發現實時數據的問題,但是可以幫助你在上線前了解實時模型的準確程度。然后進行任務的改造,不斷提高數據的準確率。另外這個方案還可以檢驗離線數據的準確性。
作者:黃偉倫 美團研發工程師
版权声明:本站所有资料均为网友推荐收集整理而来,仅供学习和研究交流使用。

工作时间:8:00-18:00
客服电话
电子邮件
admin@qq.com
扫码二维码
获取最新动态