摘要
面試時,交流有關mysql索引問題時,發現有些人能夠濤濤不絕的說出B+樹和B樹,平衡二叉樹的區別,卻說不出B+樹和hash索引的區別。這種一看就知道是死記硬背,沒有理解索引的本質。本文旨在剖析這背后的原理,歡迎留言探討
問題
redis和mysql結合使用,如果對以下問題感到困惑或一知半解,請繼續看下去,相信本文一定會對你有幫助
mysql 索引如何實現
mysql 索引結構B+樹與hash有何區別。分別適用于什么場景
數據庫的索引還能有其他實現嗎
MySQL索引的實現原理、redis跳表是如何實現的
跳表和B+樹,LSM樹有和區別呢
解析
首先為什么要把mysql索引和redis跳表放在一起討論呢,因為他們解決的都是同一種問題,用于解決數據集合的查找問題,即根據指定的key,快速查到它所在的位置(或者對應的value)
redis查看當前數據庫索引,當你站在這個角度去思考問題時,還會不知道B+樹索引和hash索引的區別嗎
數據集合的查找問題
現在我們將問題領域邊界劃分清楚了,就是為了解決數據集合的查找問題。這一塊需要考慮哪些問題呢
需要支持哪些查找方式,單key/多key/范圍查找,
怎么保證redis和數據庫數據一致,插入/刪除效率
查找效率(即時間復雜度)
存儲大小(空間復雜度)
我們看下幾種常用的查找結構
hash
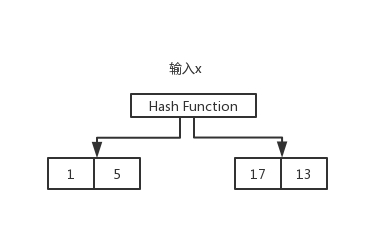
hash是key,value形式,通過一個散列函數,能夠根據key快速找到value
B+樹
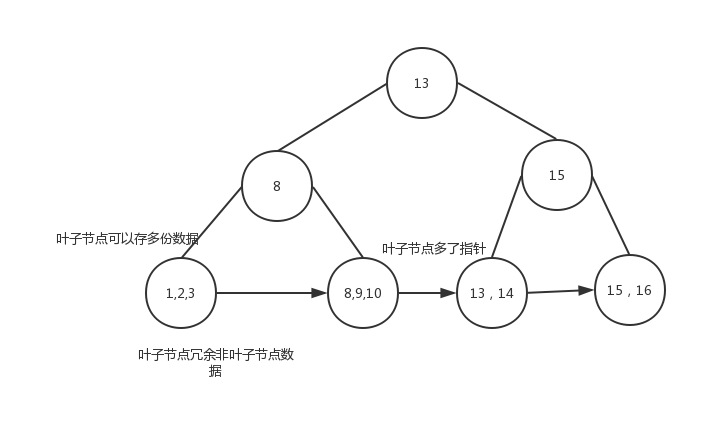
B+樹是在平衡二叉樹基礎上演變過來,為什么我們在算法課上沒學到B+樹和跳表這種結構呢。因為他們都是從工程實踐中得到,在理論的基礎上進行了妥協。
B+樹首先是有序結構,為了不至于樹的高度太高,影響查找效率,在葉子節點上存儲的不是單個數據,而是一頁數據,提高了查找效率,而為了更好的支持范圍查詢,B+樹在葉子節點冗余了非葉子節點數據,為了支持翻頁,葉子節點之間通過指針連接。
跳表
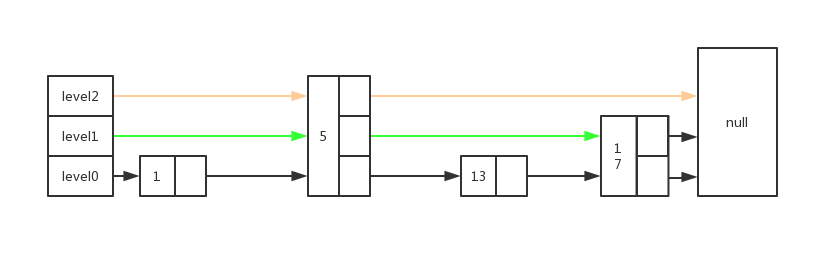
跳表是在鏈表的基礎上進行擴展的,為的是實現redis的sorted set數據結構。 level0: 是存儲原始數據的,是一個有序鏈表,每個節點都在鏈上 level0+: 通過指針串聯起節點,是原始數據的一個子集,level等級越高,串聯的數據越少,這樣可以顯著提高查找效率,
總結
數據結構實現原理key查詢方式查找效率存儲大小插入、刪除效率
Hash
哈希表
支持單key
接近O(1)
小,除了數據沒有額外的存儲
O(1)
B+樹
平衡二叉樹擴展而來
單key,范圍,分頁
O(Log(n)
除了數據,還多了左右指針,以及葉子節點指針
O(Log(n),需要調整樹的結構,算法比較復雜
跳表
有序鏈表擴展而來
單key,分頁
O(Log(n)
除了數據,還多了指針,但是每個節點的指針小于<2,所以比B+樹占用空間小
O(Log(n),只用處理鏈表,算法比較簡單
版权声明:本站所有资料均为网友推荐收集整理而来,仅供学习和研究交流使用。

工作时间:8:00-18:00
客服电话
电子邮件
admin@qq.com
扫码二维码
获取最新动态