一方面, 面向對象語言對事物的體現都是以對象的形式,為了方便對多個對象的操作,就要對對象進行存儲。另一方面,使用Array存儲對象方面具有一些弊端,而Java 集合就像一種容器,可以動態地把多個對象的引用放入容器中。
? 數組初始化之后,長度就確定了,不能更改了
? 數組聲明的類型,就決定了元素初始化時候的類型
? 數組初始化之后,長度就不能改變了,不便于擴展
? 數組中提供的屬性和方法較少,不便于進行增刪改查插入等操作,且效率不高。數組無法直接獲取存儲元素的個數
? 數組存儲的數據是有序的,可以重復的,存儲的特點單一
java兩個list取交集?Java 集合類可以用于存儲數量不等的多個對象,還可用于保存具有映射關系的關聯數組。
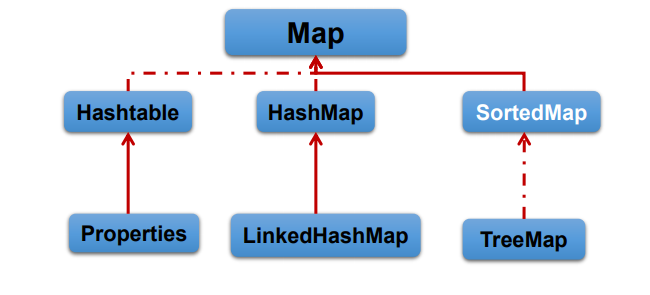
Java 集合可分為 Collection 和 Map 兩種體系 :
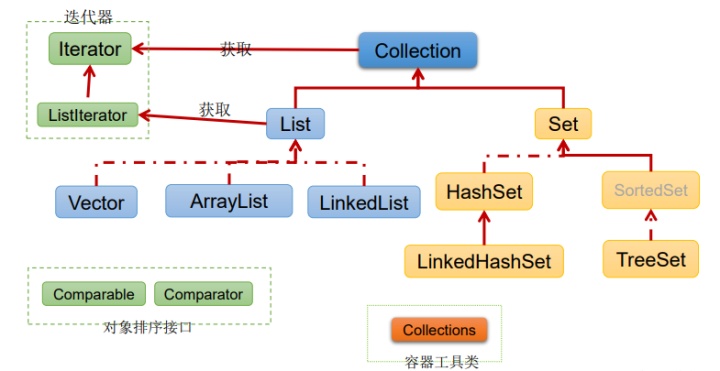
Collection接口:單列數據,定義了存取一組對象的方法的集合
? List:元素有序、可重復的集合
? Set:元素無序、不可重復的集合
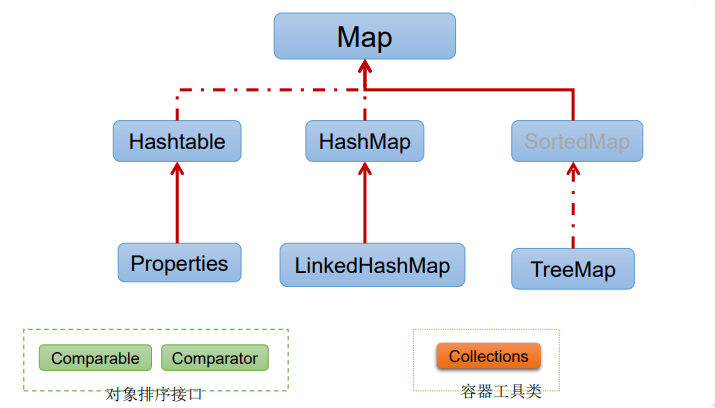
Map接口:雙列數據,保存具有映射關系“key-value對”的集合
list對象集合求差集。Collection接口繼承樹:
Map接口繼承樹:
add(Object obj)
addAll(Collection coll)
java的split函數,2.獲取有效元素的個數
int size()
3.清空集合
void clear()
4.判斷是否為空
boolean isEmpty()
java字符串轉成數組的方法,5.判斷是否包含某個元素
boolean contains(Object obj) 是通過元素的equals方法來判斷是否是同一個對象
boolean contains(Collection coll) 也是調用元素的equals方法來比較的。拿兩個集合的元素挨個比較。
6.刪除
boolean remove(Object obj) 通過元素的equals方法判斷是否存在該元素,再將其刪除,但是只會刪除找到的第一個匹配的元素
boolean removeAll(Collection coll) 取兩個集合的差集
如何得到列表list的交集與差集?7.取兩個集合的交集
boolean retainAll(Collection c) 把交集的結果存在當前集合中,c不會改變
8.集合是否相等
boolean equals(Object obj)
9.轉換成對象數組
Object[] toArray()
java按照某個字段排序、10. 獲取集合對象的哈希值
hashCode()
11. 遍歷
iterator() 返回迭代器對象,用于遍歷集合
Collection集合常用下圖所示方法遍歷:

注意:
Iterator 除了上面這種用迭代器遍歷集合的方法,還可以用foreach(又叫增強for循環)來遍歷
forjava集合底層數據結構。或者直接用Collection中的forEach()方法
collList集合類中元素有序、可以重復,集合中每個元素都有其對應的順序索引,每個元素都對應一個整數型的序號記載其在容器中的位置,可以根據序號存取容器中的元素。List接口的實現類常用的有:ArrayList、LinkedList和Vector。
List除了從Collection集合繼承的方法外,List 集合里添加了一些根據索引來操作集合元素的方法。
ArrayList的底層還是通過數組來實現的
在JDK1.7中ArrayList像餓漢式,在創建List對象的時候就直接創建了一個初始容量為10的數組;
在JDK1.8中ArrayList像懶漢式,創建對象的時候創建一個長度為0的數組,當添加第一個元素的時候再創建一個容量為10的數組。
list求并集?注意:Arrays.asList(…) 方法返回的 List 集合,既不是 ArrayList 實例,也不是Vector 實例。 Arrays.asList(…) 返回值是一個固定長度的 List 集合
因為LinkedList底層是用鏈表實現的,所以插入和刪除的效率比ArrayList要搞,對于頻繁的插入和刪除,建議使用LinkedList。
LinkedList中的方法:
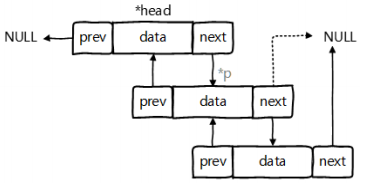
具體的底層實現:
LinkedList底層是用雙向鏈表實現的,內部定義了Node類型的first和last,用于記錄首末元素。同時定義內部類Node,作為LinkedList保存數據的基本結構,Node除了保存數據還定義了兩個變量:
源碼:
private list取值。
Vector 是一個古老的集合,JDK1.0就有了。大多數操作與ArrayList相同,區別之處在于Vector是線程安全的。
新增方法:
void addElement(Object obj)
void insertElementAt(Object obj,int index)
void setElementAt(Object obj,int index)
java list集合、void removeElement(Object obj)
void removeAllElements()
二者都線程不安全,相對線程安全的Vector,執行效率高。此外,ArrayList是實現了基于動態數組的數據結構,LinkedList基于鏈表的數據結構。對于隨機訪問get和set,ArrayList覺得優于LinkedList,因為LinkedList要移動指針。對于新增和刪除操作add(特指插入)和remove,LinkedList比較占優勢,因為ArrayList要移動數據。
Vector和ArrayList幾乎是完全相同的,唯一的區別在于Vector是同步類(synchronized),屬于強同步類。因此開銷就比ArrayList要大,訪問要慢。正常情況下,大多數的Java程序員使用 ArrayList而不是Vector,因為同步完全可以由程序員自己來控制。Vector每次擴容請求其大小的2倍空間,而ArrayList是1.5倍。Vector還有一個子類Stack。
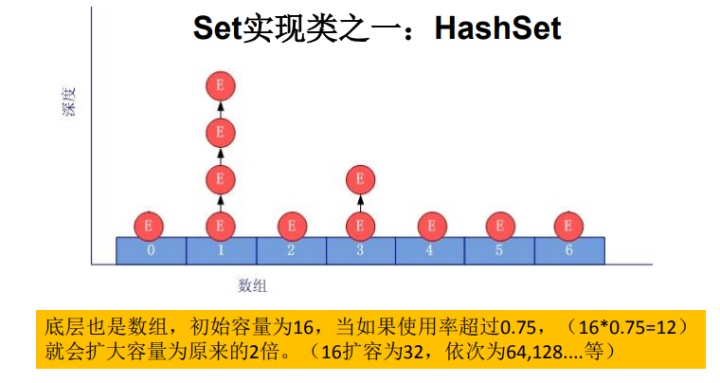
HashSet 按 Hash 算法來存儲集合中的元素,具有很好的存取、查找、刪除性能。
HashSet判斷兩個元素相同的標準:
兩個對象通過 hashCode() 方法比較相等,并且兩個對象的 equals() 方法返回值也相等。
注意:
對于存放在Set容器中的對象,對應的類一定要重寫equals()和hashCode(Object obj)方法,以實現對象相等規則。即:“相等的對象必須具有相等的散列碼”。
? 首先會調用該對象的HashCode()方法,來得到該對象的HashCode值,然后根據HashCode的值,通過某種散列函數決定該對象在HashSet底層數組中的存儲位置(這個散列函數會與底層數組的長度相計算得到在數組中的下標,并且這種散列函數計算還盡可能保證能均勻存儲元素,越是散列分布,該散列函數設計的越好)。
? 如果該位置沒有存儲其他元素,那么就直接添加成功;如果已經有元素了,則比較兩個元素的HashCode值。
? 如果兩個元素的哈希值不相等,那么就可以通過鏈表的方式將添加的元素和原來有的元素鏈接起來;如果兩個元素的哈希值相等,就要調用equals() 方法比較兩個元素是否一樣了。
? 如果equals() 方法返回true,則添加失敗,如果返回false,則添加成功,該元素通過鏈表的方式和原來鏈接的元素鏈接在一起。
HashSet的底層實現實際上是HashMap,如下圖所示:
LinkedHashSet 是 HashSet 的子類
LinkedHashSet 根據元素的 hashCode 值來決定元素的存儲位置,但它同時使用雙向鏈表維護元素的次序,這使得元素看起來是以插入順序保存的。
LinkedHashSet插入性能略低于 HashSet,但在迭代訪問 Set 里的全部元素時有很好的性能。

TreeSet 是 SortedSet 接口的實現類,TreeSet 可以確保集合元素處于排序狀態。TreeSet底層使用紅黑樹結構存儲數據。
新增的方法如下: (了解)
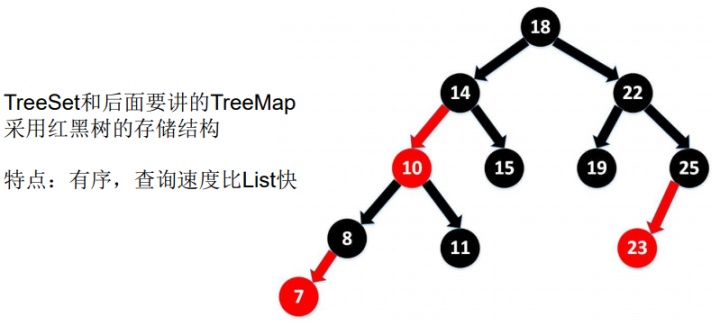
TreeSet 會調用集合元素的 compareTo(Object obj) 方法來比較元素之間的大小關系,然后將集合元素按升序(默認情況)排列。
注意:如果要把一個對象添加到TreeSet中,則該對象的類必須實現Comparable接口。實現 Comparable 的類必須實現 compareTo(Object obj) 方法,兩個對象即通過 compareTo(Object obj) 方法的返回值來比較大小。
向 TreeSet 中添加元素時,只有第一個元素無須比較compareTo()方法,后面添加的所有元素都會調用compareTo()方法進行比較。
因為只有相同類的兩個實例才能比較,所以向 TreeSet 中添加的應該是同一個類的對象。
對于 TreeSet 集合而言,它判斷兩個對象是否相等的唯一標準是:兩個對象通 過 compareTo(Object obj) 方法比較返回值。
TreeSet的自然排序要求元素所屬的類實現Comparable接口,如果元素所屬的類沒有實現Comparable接口,或不希望按照升序(默認情況)的方式排列元素或希望按照其它屬性大小進行排序,則考慮使用定制排序。定制排序,通過Comparator接口來實現。需要重寫compare(T o1,T o2)方法。
利用int compare(T o1,T o2)方法,比較o1和o2的大小:如果方法返回正整數,則表示o1大于o2;如果返回0,表示相等;返回負整數,表示o1小于o2。
注意:
面試題:
其中Person類中重寫了hashCode()和equal()方法
HashSet Map接口繼承樹:
Object put(Object key,Object value) 將指定key-value添加到(或修改)當前map對象中
void putAll(Map m) 將m中的所有key-value對存放到當前map中
Object remove(Object key) 移除指定key的key-value對,并返回value
void clear() 清空當前map中的所有數據
Object get(Object key) 獲取指定key對應的value
boolean containsKey(Object key) 是否包含指定的key
boolean containsValue(Object value):是否包含指定的value
int size() 返回map中key-value對的個數
boolean isEmpty() 判斷當前map是否為空
boolean equals(Object obj) 判斷當前map和參數對象obj是否相等
Set keySet() 返回所有key構成的Set集合
Collection values() 返回所有value構成的Collection集合
Set entrySet():返回所有key-value對構成的Set集合
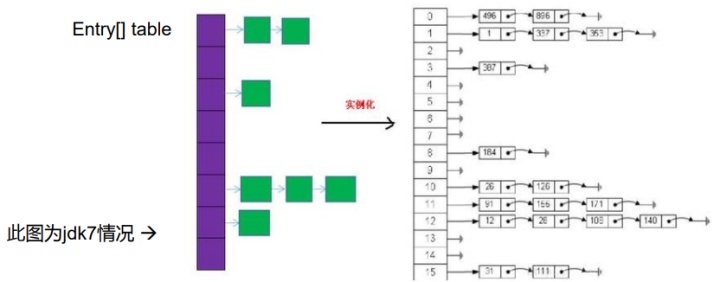
Map JDK 7及以前版本:HashMap是數組+鏈表結構(即為鏈地址法)
JDK 8版本發布以后:HashMap是數組+鏈表+紅黑樹實現。

DEFAULT_INITIAL_CAPACITY : HashMap的默認容量,16
MAXIMUM_CAPACITY: HashMap的最大支持容量,2^30^
DEFAULT_LOAD_FACTOR:HashMap的默認加載因子,0.75
TREEIFY_THRESHOLD:Bucket中鏈表長度大于該默認值,轉化為紅黑樹,8
UNTREEIFY_THRESHOLD:Bucket中紅黑樹存儲的Node小于該默認值,轉化為鏈表
MIN_TREEIFY_CAPACITY:桶中的Node被樹化時最小的hash表容量,64(當桶中Node的數量大到需要變紅黑樹時,若hash表容量小于MIN_TREEIFY_CAPACITY時,此時應執行resize擴容操作這個MIN_TREEIFY_CAPACITY的值至少是TREEIFY_THRESHOLD的4 倍)
table:存儲元素的數組,總是2的n次冪
entrySet:存儲具體元素的集
size:HashMap中存儲的鍵值對的數量
modCount:HashMap擴容和結構改變的次數。
threshold:擴容的臨界值 = 容量 * 加載因子
loadFactor:加載因子
HashMap的內部存儲結構其實是數組+鏈表+紅黑樹。當實例化一個HashMap時,系統會創建一個長度為Capacity的Node數組(JDK8中沒添加元素之前為0,在第一次add操作之后才會創建一個實際長度為16),這個長度在哈希表中被稱為容量(Capacity),在這個數組中可以存放元素的位置我們稱之為“桶”(bucket),每個bucket都有自己的索引,系統可以根據索引快速的查找bucket中的元素。
每個bucket中存儲一個元素,即一個Node對象,但每一個Node對象可以帶 一個引用變量next,用于指向下一個元素,因此,在一個桶中,就有可能生成一個Node鏈。也可能是一個一個TreeNode對象,每一個TreeNode對象 可以有兩個葉子結點left和right,因此,在一個桶中,就有可能生成一個TreeNode樹。而新添加的元素作為鏈表的last,或樹的葉子結點。
向HashMap中添加entry1(key,value),需要首先計算entry1中key的哈希值(根據 key所在類的hashCode()計算得到),此哈希值經過處理以后,得到在底層Node[]數組中要存儲的位置i。
如果位置i上沒有元素,則entry1直接添加成功。如果位置i上已經存在entry2(或還有鏈表存在的entry3,entry4),則需要通過循環的方法,依次比較entry1中key和其他的entry。
如果彼此hash值不同,則直接添加成功如果 hash值相同,繼續調用二者的equals()方法,如果返回值為true,則使用entry1的value 去替換equals為true的entry的value。
如果遍歷一遍以后,發現所有的equals返回都為false,則entry1仍可添加成功。
JDK8中添加的核心源碼:
final 當HashMap中的元素越來越多的時候,hash沖突的幾率也就越來越高,因為數組的長度是固定的。所以為了提高查詢的效率,就要對HashMap的數組進行擴容,而在HashMap數組擴容之后,最消耗性能的點就出現了:原數組中的數據必須重新計算其在新數組中的位置,并放進去,這就是resize。
擴容核心源碼:
final 擴容的時機:
當HashMap中的元素個數超過數組大小(數組總大小length,不是數組中個數 size) * loadFactor 時, 就會進行數 組擴容,loadFactor的默認值(DEFAULT_LOAD_FACTOR)為0.75,這是一個折中的取值。也就是說,默認情況 下,數組大小(DEFAULT_INITIAL_CAPACITY)為16,那么當HashMap中元素個數 超過16 * 0.75=12(這個值就是代碼中的threshold值,也叫做臨界值)的時候,就把 數組的大小擴展為 (16 << 2) = 32,即擴大一倍,然后重新計算每個元素在數組中的位置, 而這是一個非常消耗性能的操作,所以如果我們已經預知HashMap中元素的個數, 那么預設元素的個數能夠有效的提高HashMap的性能。
樹形化的條件:
當HashMap中的其中一個鏈的對象個數如果達到了8個,此時如果capacity沒有達到64,那么HashMap會先擴容解決,如果已經達到了64,那么這個鏈會變成樹,結點類型由Node變成TreeNode類型。當然,如果當映射關系被移除后, 下次resize方法時判斷樹的結點個數低于6個,也會把樹再轉為鏈表。
小結:
LinkedHashMap是HashMap的子類,LinkedHashMap在HashMap的存儲基礎上,使用了一對雙向鏈表來記錄添加元素的順序。
HashMap中的內部類:Node
static LinkedHashMap中的內部類:Entry
static TreeMap存儲 Key-Value 對時,需要根據 key-value 對進行排序,TreeMap 可以保證所有的 Key-Value 對處于有序狀態。TreeSet底層使用的是紅黑樹結構存儲數據。
TreeMap 的 Key 的排序:
TreeMap判斷兩個key相等的標準:
? 兩個key通過compareTo()方法或 者compare()方法返回0。
Hashtable是個古老的 Map 實現類,JDK1.0就提供了,和HashMap的區別在于Hashtable是線程安全的,并且Hashtable 不允許使用 null 作為 key 和 value。Hashtable實現原理和HashMap相同,功能相同。底層都使用哈希表結構,查詢速度快,很多情況下可以互用。
Properties 類是 Hashtable 的子類,該對象用于處理屬性文件。由于屬性文件里的 key、value 都是字符串類型,所以 Properties 里的 key 和 value 都是字符串類型。
存取數據時,建議使用setProperty(String key,String value)方法和 getProperty(String key)方法。
示例:
Properties Collections 是一個操作 Set、List 和 Map 等集合的工具類,Collections 中提供了一系列靜態的方法對集合元素進行排序、查詢和修改等操作, 還提供了對集合對象設置不可變、對集合對象實現同步控制等方法。
Collections 類中提供了多個 synchronizedXxx() 方法,該方法可使將指定集合包裝成線程同步的集合,從而可以解決多線程并發訪問集合時的線程安全問題
版权声明:本站所有资料均为网友推荐收集整理而来,仅供学习和研究交流使用。

工作时间:8:00-18:00
客服电话
电子邮件
admin@qq.com
扫码二维码
获取最新动态











