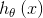切比雪夫不等式考察的是單個隨機變量的情況。
設隨機變量 X 具有數學期望
理學統計學?我們以連續型隨機變量對之進行證明:
根據單隨機變量的切比雪夫不等式,我們可獲得關于方差的一個重要性質:
D(X)=0 的充要條件是 X以概率1取常數
設隨機變量
由二項分布的定義可知,隨機變量 X是
統計學研究,
首先連續型隨機變量的:
\begin{split} &E(X)=\int_{-\infty}^\infty xf(x)dx\\ &D(X)=\int_{-\infty}^\infty (x-E(x))^2f(x)dx \end{split}
設隨機變量X\sim U(a, b)X~U(a,b):
\begin{split} E(x)=&\frac{a+b}2\\ D(x)=&E(X^2)-(E(x))^2\\ =&\frac{(b-a)^2}{12} \end{split}
常見的大數定理又有兩種形式:辛欽大數定律(弱大數定理)以及它的一個重要推論伯努利大數定理。
統計學界的大牛,設 X_1,X_2,\cdots,X_nX1,X2,?,Xn 是相互獨立,服從同一分布的隨機變量序列(i.i.d, independent identically distributed),具有數學期望 E(X_k)=\muE(Xk)=μ(k=1,2,\cdots,nk=1,2,?,n). 作前 nn 個變量的算術平均
證 我們只在隨機變量的方差為 D(Xk)=σ2(k=1,2,?,n)存在,這一條件下證明上述結果,因為
極簡統計學?又根據獨立性得(D(X+Y)=D(X)+D(Y)+2cov(x,y)):
將 1n∑k=1nXk 看做一個新的隨機變量(也即單隨機變量),再根據前述的切比雪夫不等式,得:
當 n→∞大數定理自然成立。
統計學魏宗舒,當然很快數學家們發明了更簡潔的記號和表達描述大數定理:序列 1n∑k=1nXk以概率收斂于 μ,記做 Xˉ?Pμ。
設 fA 是 nn 次獨立重復試驗中事件A
\lim_{n\to\infty}P\{|\frac{f_A}{n}-p|<\epsilon\}=1
fA~b(n,p),有:
一個通俗的理解是:樣本量足夠大的時候,樣本均值接近于期望值。
統計學黃良文、假設隨機變量 X等于:拋100次硬幣得到的正面的次數(
首先我們自然知道該隨機變量的期望值(Expected values):
大數定律是說,如果樣本量足夠大,樣本均值將趨近于期望值。
楊大成統計學。很多人會誤以為如果100次試驗后,如果正面數高于均值,大數定律會讓后面的正面數更少,這就是所謂的賭徒謬誤(gambler’s fallacy)。
事實上,概率并未發生任何改變,大數定律根本不關心前面的有限次試驗,后面還剩下無限次試驗,這無限次的期望值是50.
我們可使用python相關工具箱(scipy)對之進行簡單的仿真模擬:
import scipy.stats as st
import matplotlib.pyplot as pltdef main():n, p = 100, .5X = st.binom(n, p)# X ~ b(n, p) X_bar = [X.rvs(i+1).mean() for i in range(10000)]plt.figure(facecolor='w', edgecolor='k')plt.plot(range(10000), X_bar, 'g.')plt.axhline(y=50)plt.savefig('./large_number.png')plt.show()if __name__ == '__main__':main()
設隨機變量 X1,X2,?,Xn,? 相互獨立,服從同一分布,且具有數學期望和方差:E(Xk)=μ,D(Xk)=σ2,則隨機變量之和 ∑nk=1Xk 的標準化變量:
程琮醫學統計學?
當 n 充分大時,有
生成正態分布隨機數:
取 n 個獨立同均勻分布
import numpy as np
import matplotlib.pyplot as plt
import seaborn as snsdef main():N = 10**5X = (np.sum(np.random.rand(N, 192), 1)-96)/4sns.set(style='dark', palette='muted', color_codes=True, font_scale=1.5)plt.figure(figsize=(10, 5))plt.hist(X, 50)plt.show()
if __name__ == '__main__':main()
版权声明:本站所有资料均为网友推荐收集整理而来,仅供学习和研究交流使用。

工作时间:8:00-18:00
客服电话
电子邮件
admin@qq.com
扫码二维码
获取最新动态