本文由屋友彭東成投稿。
=======================
第一課
首先跟大家簡單嘮叨兩句為什么要學習正則表達式,為什么在網絡爬蟲的時候離不開正則表達式。正則表達式在處理字符串的時候扮演著非常重要的角色,在網絡爬蟲的時候也十分常用,大家可以把它學的簡單一些,但是不能不學。
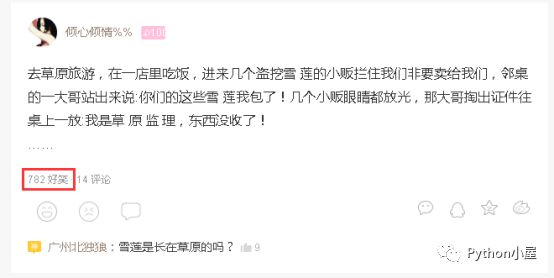
盡管網絡爬蟲相關庫給我們提供了豐富的庫如css、bs4、lxml等等,讓我們可以通過選擇器去匹配字符串,但是在HTML中數據往往存在標簽之中。通過選擇器確實可以匹配到標簽的內容,但是有時候標簽中存在的許多內容是冗余的,而我們只需要匹配其中部分內容即可(如匹配數字、時間等),如下圖所示。通過選擇器,我們一般可以獲取到“782好笑”這個字符串,但是我們只需要“782”這個數字的話,此時正則表達式就要派上用場了。
正則表達式可以幫我們判斷某個字符串是否符合某一個模式,其次正則表達式可以幫我們提取某個字符串中的重要部分,做子字符串的提取。今天簡單的給大家講解幾個正則表達式的特殊字符—— “^”、“.”、“*”,并且用實例進行演示,讓大家對正則表達式有個初步的了解。
本文用的Python是3版本,開發環境用的是pycharm,首先在本地新建一個demo.py文件,接下來開始進行演示。
1、正則表達式在Python中有個專門的庫叫re模塊,首先進行導入模塊。再定義一個字符串str,然后定義一個正則表達式匹配規則regex。?
2、“^d”代表的意思是以d元素開頭的任意一個字符串,也就是說只要是以d開頭的字符串,后面的元素不論是什么,都是符合規則的,總之必須要以d開頭。?
3、“.” 較為常用,其代表的意思是任意字符,其表示的范圍非常廣,可以接任意字符,不論是中英文,還是下劃線之類的特殊字符,都是可以代表的。舉個栗子,正則表達式“^d.”就是代表以d開頭的字符串,b后邊接任意字符都可以。?
4、“*” 也十分常用,其代表的意思是前面的字符可以重復任意多遍,可以是0次,1次,2次等任意多次。?
5、了解好這幾個特殊字符的用法之后,接下來通過代碼簡單的感受一下。如下圖所示,如果匹配成功,則返回yes;如果沒有匹配成功,則不返回任何東西。

可以看到程序運行之后,返回的結果為yes,說明匹配成功。正則表達式“^d.*”代表的意思是以d開頭的字符串,后面跟著任意字符,出現任意多遍。顯然,通過匹配可以得知該正則表達式匹配的結果和原始字符串一致,之后if判斷返回值為true,所以打印出結果為yes。
6、為了進一步驗證這個模式是否正確,我們將b改為a,其代表的意思該模式下的字符串是否以a開頭的。之后再次運行程序,如下圖所示。

此時可以看到無任何輸出,說明特殊字符“^”起到了作用。
=========================
第二課
今天繼續給大家分享Python正則表達式相關特殊字符知識點。
1、特殊字符“$”代表的意思是結尾字符。舉個栗子,正則表達式“3$”,表示匹配以3為結尾的字符串。代碼演示如下圖所示。

正則表達式匹配模式“.*3$”代表以3結尾的任意字符的字符串,很顯然匹配的結果和原始字符串是一致的,所以有返回結果。
2、如果將正則表達式匹配模式改為“.*4$”,則表示以4結尾的任意字符的字符串,此時是沒有任何的輸出結果的,如下圖所示。

3、正則表達式特殊字符“?”比較常用,其代表的意思是非貪婪匹配模式。默認情況下,匹配字符串是一種貪婪的匹配,換句話說,默認情況下字符串會根據匹配模式,去匹配最大的長度。?
4、下圖是一個實例。其中括號代表的是提取字符串的子串,正則表達式會把滿足匹配條件的字符串放到括號里邊。匹配模式“.*(p.*p).*”代表的意思是:左邊的“.* ”的意思是任意字符串,可以是空,也可以是非空的字符串,之后是字符p,中間的“.* ” 的意思也是任意字符串,之后再是一個p,爾后右邊的“.* ” 的意思也是任意字符串。目前的邏輯就是將兩個p中間的字符串連同p一塊取出。

但是其輸出的結果卻為“pp”,并不是我們想要的“pccccccccccp”結果。原因是正則表達式的貪婪匹配所致,實際上它是反向匹配的,所以從字符串來看,匹配到的結果是“pp”。?
5、如果我們使用非貪婪模式,即將匹配模式“.*(p.*p).*”改為模式“.*?(p.*p).*”,在第一“p”之前加個特殊字符“?”,則運行的結果就如下圖所示。

可以看到匹配模式已經開始從左邊開始進行匹配,答案趨向于我們想要的結果。但是在后面卻出現了兩個p。原因是后面的那個p未指定其為非貪婪模式,所以后面的那個p仍然是從右邊開始反向取值的。
6、接下來,我們繼續使用非貪婪模式,即將匹配模式“.*(p.*p).*”改為模式“.*?(p.*?p).*”,在第二“p”之前也加個特殊字符“?”,則運行的結果就如下圖所示。

此時可以看到匹配的結果就是我們想要的結果了,原因是此時兩個p均采用了非貪婪模式,所以匹配模式,從左到右順序進行。
7、理解非貪婪模式之后,對于正則表達式的匹配就很好理解了,如下圖的結果將返回“pcccp”,非貪婪模式下。

8、下圖的結果將返回“pcccpcccccccpppp”,非貪婪模式和貪婪模式共存的情況下。

非貪婪模式在網絡爬蟲的過程中對于字符串的提取非常重要,務必要理解和掌握。
==============
第三課
今天繼續給大家分享Python正則表達式基礎。
1、正則表達式特殊字符“+”,其代表的意思“+”號前面的任意字符必須至少出現一次,才能匹配成功。如下圖所示,如果沒有加特殊字符“+”,則按照前面介紹的貪婪模式從右邊進行匹配,輸出的結果為“pp”。

2、現在將匹配模式由之前的“.*(p.*p).*”改為“.*(p.+p).*”,即將特殊字符“*”改為特殊字符“+”,用特殊字符“+”來限定前面的字符出現的次數,至少出現一次。運行程序,得到的結果為“ppp”,如下圖所示。

簡單的來理解一下,首先貪婪模式不在贅述,然后匹配到第一個字符p,之后碰到特殊字符“+”,表示匹配任意字符,但該字符至少出現一次,然后再匹配到第二個字符p,才會提取到匹配的字符串。
3、再次來感受一下,將之前的三個ppp改為現在的php,之后再運行程序,如下圖所示,得到的結果是php。

4、如果將之前的三個ppp改為現在的phhp,會有什么樣的結果呢?如下圖所示,毋庸置疑,答案肯定是phhp。

因為特殊字符“+”號表示只要任意字符至少出現一次,都會被提取出來。
5、簡單的來總結一下,特殊字符“*”和特殊字符“+”都是用來表示字符出現次數的限定詞,用于限定前面的任意字符出現的次數。不同的地方在于特殊字符“*”模式下,字符出現的次數可以是0次或者任意多次,而特殊字符“+”模式下,字符出現的次數至少是1次。

=====================
第四課
今天繼續給大家分享Python正則表達式基礎知識,主要給大家介紹一下特殊字符“{}”的用法。
特殊字符“{}”實質上也是一個限定詞的用法,其限定前面字符所出現的次數,其常用的模式有三種,分別是“{數字}”、“{數字,}”和“{數字1, 數字2}”。舉個例子,如“{1}”、“{1,}”和“{1, 3}”。到這里可能大家還不是很清楚,下面依次通過實例來演示一下,加深對特殊字符“{}”的理解。
1、如下圖所示,限定字符p前面的字符出現1次,則根據貪婪匹配模式,pap成功匹配到。

2、如果將匹配模式更改為“.*(p.{2}p).*”,則無任何的輸出,如下圖所示,因為此時并沒有任何的字字符串符合匹配條件。

3、相應的,我們將原始字符串做一下更改,如下圖所示,此時“.*(p.{2}p).*”匹配模式有對應的結果,如下圖所示。

4、特殊字符“{1,}”代表的是前面的字符出現1次及以上;特殊字符“{2,}”代表的是前面的字符出現2次及以上;特殊字符“{3,}”代表的是前面的字符出現3次及以上;以此類推。舉個栗子,如下圖所示。

我們要匹配出現p字符前面出現3次及以上的次數,此時子字符串phhhhp被提取出來,但是pap和paap都沒有提取到,因為其不滿足匹配條件。
5、特殊字符“{1, 3}” 代表的是前面的字符至少出現1次,最多出現3次;特殊字符“{2, 5}” 代表的是前面的字符至少出現2次,最多出現5次;以此類推。舉個栗子,如下圖所示。
當使用特殊字符“{1, 3}”的時候,如下圖所示:
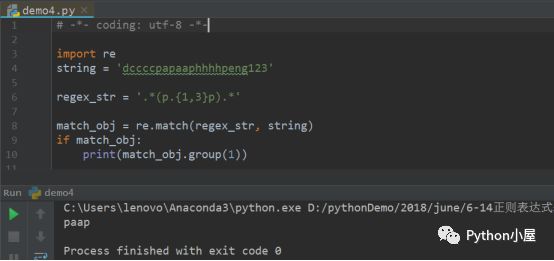
貪婪模式下,字符串從右邊開始往左取,首先遇到相對滿足條件的子字符串是phhhhp,但是并不符合規則,因為該子字符串出現的次數為4次,而限定條件為1次到3次,所以這個子字符串不符合匹配條件,爾后繼續往前匹配,得到匹配結果paap,滿足匹配條件。
6、同理,當使用特殊字符“{3, 5}”的時候,如下圖所示:

根據上一步的分析可以得知,該匹配結果為phhhhp。
==================
第五課
今天要給大家的講的特殊字符是豎線“|”。豎線“|”實質上是一個或的關系。
1、直接上代碼演示,比方說我們需要匹配一個字符串“dcpeng123”,匹配模式為 “(dcpeng|dcpeng123)”,記得匹配模式中要有括號,否則后面的group方法會報錯。

如上圖所示,匹配模式“(dcpeng|dcpeng123)”的意思是只要匹配“dcpeng”或者“dcpeng123”中的任意一個,就說明提取成功。“|”實質上是一個“或”的關系,匹配的結果為“dcpeng”可以滿足匹配條件,匹配的結果為“dcpeng123”也可以滿足匹配條件。所以在這里,正則表達式首先匹配了字符串“dcpeng”,所以打印出來的結果就是“dcpeng”。
2、當我們把匹配模式中兩個字符串的順序調整一下,如下圖所示。

根據第一步的分析步驟,其匹配結果為“dcpeng123”,在此就不再贅述了。
3、如果我們將原始字符串做一下更改,更改為“dcpeng”,而保持匹配模式不變,如下圖所示。

此時的匹配結果為“dcpeng”。原因是匹配模式首先是“dcpeng123”,與原始字符串匹配不上,之后通過特殊字符“|”再定位到“dcpeng”,發現可以與原始字符串匹配上,所以匹配成功,輸出匹配結果。
4、如果我們只是想匹配字符串中的一部分,那應該如何做呢?如下圖所示,只需要將匹配模式用括號括起來就可以了,而括號外面的部分保持與原始字符串一致即可。

此時可以看到輸出的結果為“dcpeng”。這里容易犯錯,很多小伙伴很可能以為結果是“dcpeng123”,只需要記住我們匹配的內容只是在括號中,外邊的世界與我們無關。
同樣的,如果我們將原始字符串改為“dccpeng123”,保存匹配模式不變,此時的匹配結果為“dccpeng”,如下圖所示。

5、如果真想匹配到外邊的結果,就應該再加一層括號,將外邊的內容與括進來,入下圖所示。當程序運行之后,我們得到的匹配結果是“dccpeng123”。

當程序運行之后,實際上是以最外層的這個括號為順序的,然后依次向內進行匹配。當group方法中取第一個括號的內容時,匹配到的結果是最外層括號中的內容,所以是“dccpeng123”。可以看到“123”也被提取出來了。
同理,當group方法中取第二個括號的內容時,匹配到的結果是最二層括號中的內容,所以是“dccpeng”,如下圖所示。

此時可以看到“123”并沒有被提取出來,因為此時匹配的內容是“(dcpeng|dccpeng)”。
關于在括號中提取子字符串的用法在網絡爬蟲中非常常見,也是Python正則表達式的重點學習內容,需要重點掌握。
====================
第六課
今天給大家分享的正則表達式特殊符號是“[]”。中括號十分實用,其有特殊含義,其代表的意思是中括號中的字符只要滿足其中任意一個就可以。其用法一共有三種,分別對其進行具體的代碼演示,在最后進行總結,具體的教程如下。
1、如下圖所示,匹配模式為[abcd],在這里正則表達式代表的意思是字符串第一個字符是abcd四個字符中的任意一個,然后后面的字符是“cpeng123”,如果滿足匹配條件,則輸出結果,如果不滿足,則不顯示任何結果,如下圖所示。

很顯然原始字符串的第一個字符是d,和匹配模式相接,所以輸出結果。
2、為了更好的加強理解,現在將原始字符串改為“acpeng123”,其他部分不做改動,如下圖所示。

可以看到匹配的結果是“acpeng123”,匹配成功。
3、為進一步理解中括號的意思,現在將原始字符串改為“ecpeng123”,其他部分不做改動,如下圖所示。
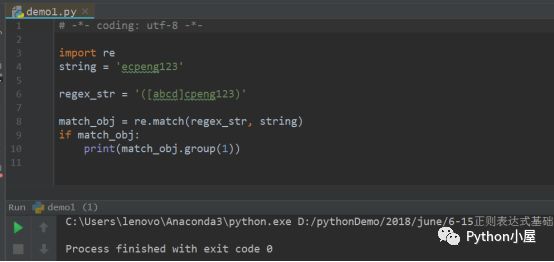
此時可以看到沒有任何結果輸出,因為在中括號中沒有對應的匹配字符,滿足不了匹配要求,所以無任何輸出。
4、看下面一個例子,提取電話號碼,這個在實際應用中十分常見。在這里介紹中括號的另外一種表達方式即[0-9],這個特殊字符代表的意思是數字0到9中的任意一個字符。下面的匹配模式'(1[34578][0-9]{9})'代表的意思是字符串以1開頭,然后第二個字符為3、4、5、7、8中任意一個,之后的字符是0到9中的數字,但是限定為9次,也就是說電話號碼的長度為1+1+9=11位。如果滿足上面的匹配要求,就輸出成功,否則就不輸出任何的字符。

如上圖,很明顯原始字符串滿足匹配的要求,所以有輸出結果。
拓展知識:[a-z]代表26個英文小寫字母;[A-Z]代表26個英文大寫字母。
5、為了進一步加強理解,將原始字符串改為160開頭的號碼,然后進行輸出,如下圖所示。

可以看到無任何輸出結果。
6、中括號的第三章用法是[^],在中括號中加入特殊字符“^”,表示非,取反的意思。舉個栗子,“[^1]”的意思是字符不等于1,下圖是代碼演示。

可以看到原始字符串與匹配模式'(1[34578][^1]{9})'匹配成功,因為從第二個字符之后,字符串中就沒有1出現,符合匹配規則。
即便是原始字符串中出現非數字的字符,只要不是1,也能夠匹配成功,如下圖所示。

7、為了加強理解,先將原始字符串中的號碼改為‘18042682515’,在字符串后邊加個1,然后匹配模式不改變,如下圖所示。

可以看到此時無任何輸出結果,因為原始字符串中出現了1,而匹配模式要求不能出現1,所以匹配不成功。
8、最后總結一下特殊字符中括號的用途。
一、中括號中的任意一個字符,如[abcd],代表a、b、c、d這四個字符中的任意一個。
二、表示區間,如[0-9],代表數字0到9中的任意一個。同理[a-z],[A-Z],其代表的意思在上面有提及,在此就不再贅述了。
三、表示非或者取反,專有的表達式是[^],如匹配模式[^1]表示匹配的字符不為1。
四、中括號中的“.”,如匹配模式[.]或“*”,如匹配模式[*],就是純粹的代表“.”號和“*”號,不再是代表特殊字符中代表的任意字符或出現多次的意思,這點需要特別注意。
===================
第七課
今天給大家分享的特殊字符是“\s”、“\S”。
1、“\s”代表的意思是匹配空格,匹配模式“加\s油”代表的是字符“加”和“油”之間有空格的意思,如下圖所示。

可以看到原始字符串中“加”和“油”之間有空格,與匹配條件相符合,所以匹配成功。
2、為了加強理解,現在將原始字符串改為“加加油”,字符中間不為空格,保持匹配模式不變,如下圖所示。

可以看到無任何輸出,說明匹配不成功。
3、如果“加”和“油”之間有多個空格的話,則只需要在匹配模式中將“加\s油”改為“加\s+油”即可,如下圖所示。

4、“\S”代表的意思與“\s”代表的意思剛剛相反,也就是說匹配的那個字符只要不是空格,都可以匹配。如下圖所示,繼續用第二步那個例子,只要將匹配模式中的“\s”改為“\S”,其他的保持不變,如下圖所示。

可以看到此時就可以匹配成功。
5、而將原始字符串改為“加 油”,兩個字符中間有個空格,匹配模式不變,如下圖所示。

可以看到此時無任何輸出,說明匹配不成功。
6、同樣的,如果要匹配多個非空白字符的話,只需要將“\S”改為“\S+”即可,如下圖所示。

=====================
第八課
今天給大家分享的特殊字符是“\w”和“\W”。
1、“\w”代表的意思是該字符為任意字符,但是和特殊字符“.”的意思不同。“\w”代表的字符主要包括26個大寫字母A到Z,即[A-Z]、26個小寫字母a到z,即[a-z]、10個阿拉伯數字0到9,即[0-9]和下劃線“_”。總結起來就是,“\w”代表的意思是[A-Za-z0-9_]中任意一個字符。“.” 代表的意思是除換行符之外的任意字符,其范圍比“\w”代表的意思要廣。
下面是具體的代碼演示,如下圖所示:

可以看到此時用的是特殊字符中括號來代替特殊字符“\w”,匹配成功。
2、現在將[A-Za-z0-9_]改為\w,如下圖所示。

可以看到仍然可以匹配成功。
3、將原始字符串改為“加A油”,如下圖所示。

可以看到仍然可以匹配成功。
4、將原始字符串改為“加_油”,如下圖所示。

可以看到仍然可以匹配成功。
5、當將原始字符串改為“加-油”,如下圖所示。

可以看到此時就不可以匹配成功了,因為字符“-”并在包括在\w涵蓋的范圍之內。
6、“\W”代表的意思與“\w”剛剛相反,也就是匹配除了[A-Za-z0-9_]之外的其他字符。接上一步的例子,此時將“\w”改為“\W”,如下圖所示。

可以看到此時就匹配成功了。
7、將原始字符串“加-油”改為“加 油”,中間有空格,其他保持不變,如下圖所示。

很顯然,使用“\w”肯定不能匹配成功,但使用“\W”便可以成功的進行匹配。
8、為了進一步加強對這兩個符號的理解,將原始字符串中的中劃線“-”改為下劃線“_”,其他的保持不變,如下圖所示。

此時可以看到匹配不成功,無任何輸出。
=======================
第九課
今天給大家分享的特殊字符是[\u4E00-\u9FA5],這個特殊字符最好能夠記下來,如果記不得的話通過百度也是可以一下子查到的。
該特殊字符是固定的寫法,其代表的意思是漢字。換句話說,只要字符中是漢字,就可以通過該字符進行匹配,該特殊字符也是用中括號括起來的。具體的代碼演示如下。
1、原始字符串是“加油”,兩個漢字,然后將匹配模式直接為[\u4E00-\u9FA5],如下圖

可以看到此時的輸出結果僅僅出現了一個“加”字,因為該匹配模式默認是匹配一個字符。
2、如何想匹配多個字符,只需要在匹配模式后面加一個“+”號即可,表示匹配連續出現的漢字,如下圖所示。

此時可以看到“加油”全都匹配出來了。
3、為了進一步加強對該特殊字符的理解,現在將“加油”兩字中嵌入非漢字,如下圖所示。

可以看到只匹配到了“加”,但是非漢字字符“a”及其以后的字符全部都匹配不到了,因為原始字符串并不是連續出現的漢字。
4、將非漢字字符放到字符串最后邊,如下圖所示。

此時可以看到“加油”這兩個連續的漢字可以成功匹配,但是非漢字字符匹配不到。
5、如果將“加油”中間加個空格,改為“加 油”,其他的保持不變,如下圖所示。

此時可以看到輸出的結果僅僅是個“加”字,空格及其之后的字符都匹配不到,因為原始字符串并不是連續出現的漢字。
6、舉個栗子,在實際應用中,往往會需要用到連續匹配漢字的地方。如現在有個需求,需要匹配字符串中的“XX”大學,如“清華大學”、“北京大學”、“中山大學”等,我們只知道字符“XX”是連續的中文,此時就可以用到本文介紹的漢字字符,如下圖所示。

此時可以看到“清華大學”匹配成功。需要注意的是特殊字符“?”記得加上,代表非貪婪模式,如果不加這個字符的話,則匹配模式從字符的后面往前取,得到的結果僅僅為“華大學”,如下圖所示。

7、同樣的,如果要匹配“上海交通大學”,也是如此,如下圖所示。

溫馨提示
進入公眾號,通過菜單“最新資源”==>“歷史文章”可以快速查看分專題的文章列表,通過“最新資源”==>“微課專區”可以觀看Python微課,通過“最新資源”==>“培訓動態”可以查看近期Python培訓安排,通過“最新資源”==>“教學資源”可以查看Python教學資源。

--------董付國老師Python系列圖書--------
1)《Python程序設計(第2版)》清華大學出版社(2018年8月第9次印刷)https://item.jd.com/11949168.html
2)《Python可以這樣學》清華大學出版社(2018年7月第6次印刷)(本書已在臺灣發行繁體版)https://item.jd.com/12040511.html
3)《Python程序設計基礎(第2版)》清華大學出版社(2018年9月第6次印刷)https://item.jd.com/12319738.html
4)《中學生可以這樣學Python》清華大學出版社(2018年9月第3次印刷)https://item.jd.com/12258900.html
5)《Python程序設計開發寶典》清華大學出版社(2018年2月第3次印刷)https://item.jd.com/12143483.html
6)《玩轉Python輕松過二級》清華大學出版社(2018年7月第3次印刷)https://item.jd.com/12361144.html
7)《Python程序設計基礎與應用》機械工業出版社(2018年9月第1次印刷)https://item.jd.com/12433472.html?dist=jd
8)《Python程序設計實驗指導書》清華大學出版社(預計2019年1月出版)
9)《Python編程基礎與案例集錦(中學版)》電子工業出版社(預計2019年2月出版)
董老師127課免費視頻地址: https://pan.baidu.com/s/1jJeAs8Q 密碼: px59
Python課堂上我與學生斗智斗勇已8個學期
非計算機專業《Python程序設計基礎》教學參考大綱
計算機相關專業“Python程序設計”教學大綱(參考)
《Python程序設計》實驗指導書(30個實驗)
《Python程序設計基礎與應用》課后習題答案
《Python程序設計基礎(第2版)》習題答案
Python課程期末考試編程題自動批卷原理與實現模板
“Python小屋”免費資源匯總(截至2018年11月28日)
系列教學PPT:
1900頁Python系列PPT分享一:基礎知識(106頁)
1900頁Python系列PPT分享二:Python序列(列表、元組、字典、集合)(154頁)
1900頁Python系列PPT分享三:選擇與循環結構語法及案例(96頁)
1900頁Python系列PPT分享四:字符串與正則表達式(109頁)
1900頁Python系列PPT分享五:函數設計與應用(134頁)
1900頁Python系列PPT分享六:面向對象程序設計(86頁)
1900頁Python系列PPT分享七:文件操作(132頁)
1900頁Python系列PPT分享八:異常處理結構與程序調試、測試(70頁)
報告PPT(163頁):基于Python語言的課程群建設探討與實踐
報告PPT(123頁):Python編程基礎精要
2000頁Python系列PPT分享九:(GUI編程)(122頁)
Python實驗項目1例:使用進程池統計指定范圍內素數的個數
(PPT)Python程序設計課程教學內容組織與教學方法實踐
版权声明:本站所有资料均为网友推荐收集整理而来,仅供学习和研究交流使用。

工作时间:8:00-18:00
客服电话
电子邮件
admin@qq.com
扫码二维码
获取最新动态










![centsos7修改主机名 [root@st152 ~]# cat /etc/hostname](http://static.blog.csdn.net/images/save_snippets.png)