CAP 定理(CAP theorem)又被称作布鲁尔定理(Brewer’s theorem),是加州大学伯克利分校的计算机科学家埃里克·布鲁尔(Eric Brewer)在 2000 年的 ACM PODC 上提出的一个猜想。2002 年,麻省理工学院的赛斯·吉尔伯特(Seth Gilbert)和南希·林奇(Nancy Lynch)发表了布鲁尔猜想的证明,使之成为分布式计算领域公认的一个定理。对于设计分布式系统的架构师来说,CAP 是必须掌握的理论。
从0开始学架构,CAP 理论
CAP 应用
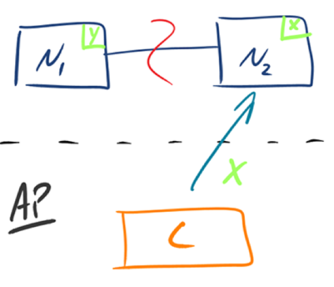
分布式系统理论上不可能选择 CA 架构,只能选择 CP 或者 AP 架构。
架构师怎么学,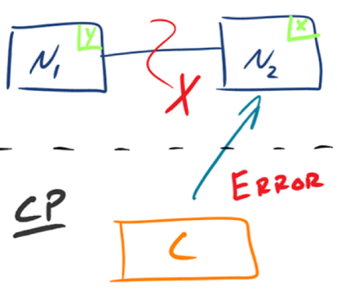
CAP 关键细节点
架构宝典 pdf、ACID
ACID 是数据库管理系统为了保证事务的正确性而提出来的一个理论,ACID 包含四个约束,下面我来解释一下。
BASE
程序员必读之软件架构。BASE 是指基本可用(Basically Available)、软状态( Soft State)、最终一致性( Eventual Consistency),核心思想是即使无法做到强一致性(CAP 的一致性就是强一致性),但应用可以采用适合的方式达到最终一致性。
BASE 理论本质上是对 CAP 的延伸和补充,更具体地说,是对 CAP 中 AP 方案的一个补充。前面在剖析 CAP 理论时,提到了其实和 BASE 相关的两点:
CAP & ACID & BASE
mongodb高可用架构、综合上面的分析,ACID 是数据库事务完整性的理论,CAP 是分布式系统设计理论,BASE 是 CAP 理论中 AP 方案的延伸。
FMEA 介绍
FMEA(Failure mode and effects analysis,故障模式与影响分析)
FMEA 方法
在架构设计领域,FMEA 的具体分析方法是:
FMEA 分析的方法其实很简单,就是一个 FMEA 分析表,常见的 FMEA 分析表格包含下面部分。
FMEA 实战
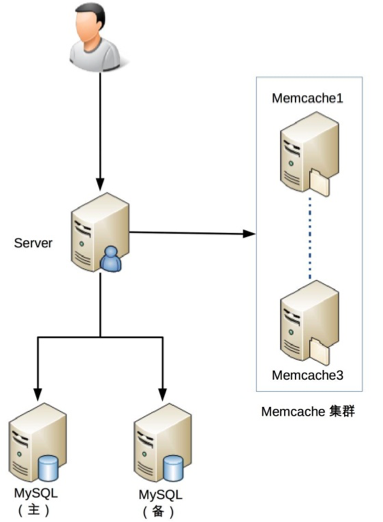
下面我以一个简单的样例来模拟一次 FMEA 分析。假设我们设计一个最简单的用户管理系统,包含登录和注册两个功能,其初始架构是:

初始架构很简单:MySQL 负责存储,Memcache(以下简称 MC)负责缓存,Server 负责业务处理。我们来看看这个架构通过 FMEA 分析后,能够有什么样的发现,下表是分析的样例(注意,这个样例并不完整,感兴趣的同学可以自行尝试将这个案例补充完整)。

经过上表的 FMEA 分析,将“后续规划”列的内容汇总一下,我们最终得到了下面几条需要改进的措施:
改进后的架构如下:
主备复制
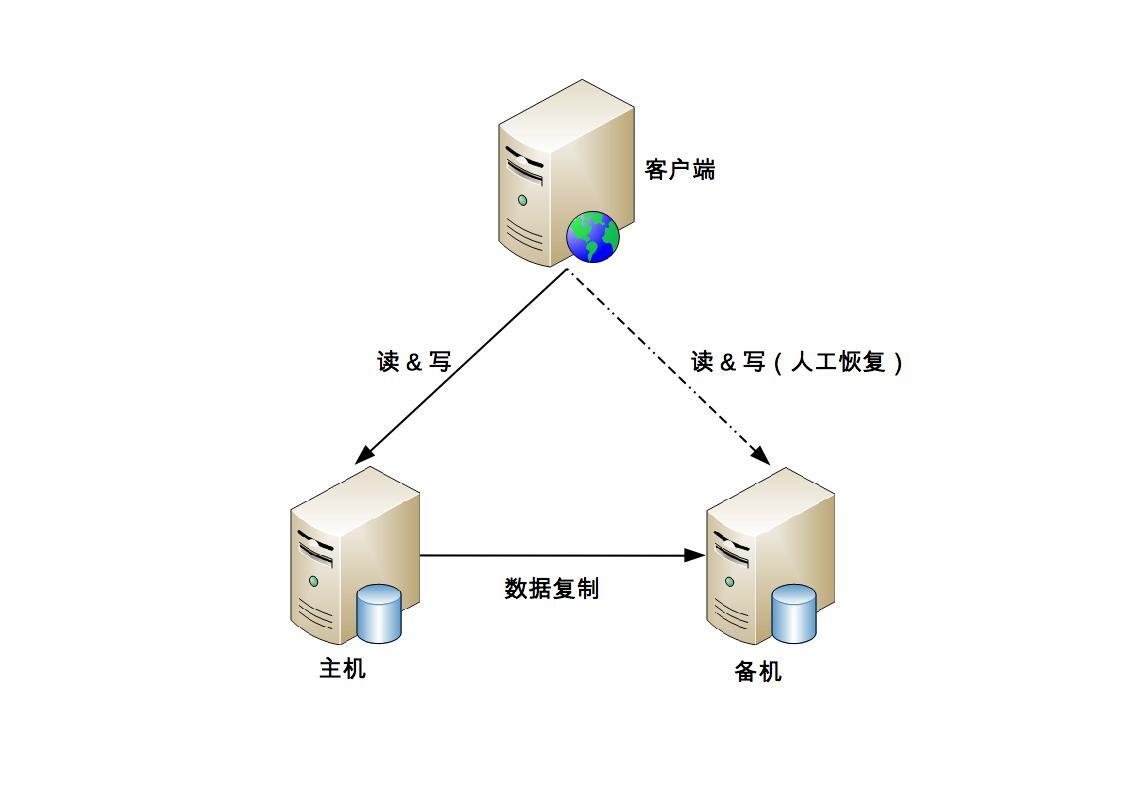
综合主备复制架构的优缺点,内部的后台管理系统使用主备复制架构的情况会比较多,例如学生管理系统、员工管理系统、假期管理系统等,因为这类系统的数据变更频率低,即使在某些场景下丢失数据,也可以通过人工的方式补全。
主从复制

综合主从复制的优缺点,一般情况下,写少读多的业务使用主从复制的存储架构比较多。例如,论坛、BBS、新闻网站这类业务,此类业务的读操作数量是写操作数量的 10 倍甚至 100 倍以上。
双机切换
故名思议,互连式就是指主备机直接建立状态传递的渠道,架构图请注意与主备复制架构对比。

中介式指的是在主备两者之外引入第三方中介,主备机之间不直接连接,而都去连接中介,并且通过中介来传递状态信息,其架构图如下:

MongoDB 的 Replica Set 采取的就是这种方式,其基本架构如下:

MongoDB(M) 表示主节点,MongoDB(S) 表示备节点,MongoDB(A) 表示仲裁节点。主备节点存储数据,仲裁节点不存储数据。客户端同时连接主节点与备节点,不连接仲裁节点。
幸运的是,开源方案已经有比较成熟的中介式解决方案,例如 ZooKeeper 和 Keepalived。ZooKeeper 本身已经实现了高可用集群架构,因此已经帮我们解决了中介本身的可靠性问题,在工程实践中推荐基于 ZooKeeper 搭建中介式切换架构。
模拟式指主备机之间并不传递任何状态数据,而是备机模拟成一个客户端,向主机发起模拟的读写操作,根据读写操作的响应情况来判断主机的状态。其基本架构如下:

主主复制
主主复制指的是两台机器都是主机,互相将数据复制给对方,客户端可以任意挑选其中一台机器进行读写操作,下面是基本架构图。
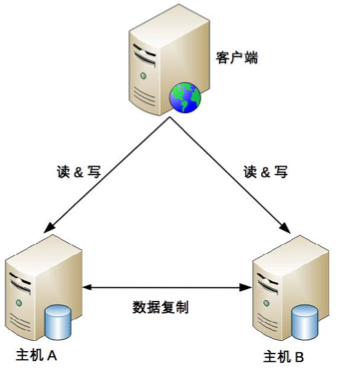
因此,主主复制架构对数据的设计有严格的要求,一般适合于那些临时性、可丢失、可覆盖的数据场景。例如,用户登录产生的 session 数据(可以重新登录生成)、用户行为的日志数据(可以丢失)、论坛的草稿数据(可以丢失)等。
设计一个政府信息公开网站的信息存储系统,你会采取哪种架构?谈谈你的分析和理由。
政府信息网站使用主备或者主从架构就可以了。信息都是人工录入,可以补录。数据本来对实时性要求不高,所以出了故障人工修复也来得及。所以主备就够了,如果为了照顾形象可以用主从,保证主机故障后仍然可以查,不能新发
数据集群
数据集中集群与主备、主从这类架构相似,我们也可以称数据集中集群为 1 主多备或者 1 主多从。无论是 1 主 1 从、1 主 1 备,还是 1 主多备、1 主多从,数据都只能往主机中写,而读操作可以参考主备、主从架构进行灵活多变。下图是读写全部到主机的一种架构:
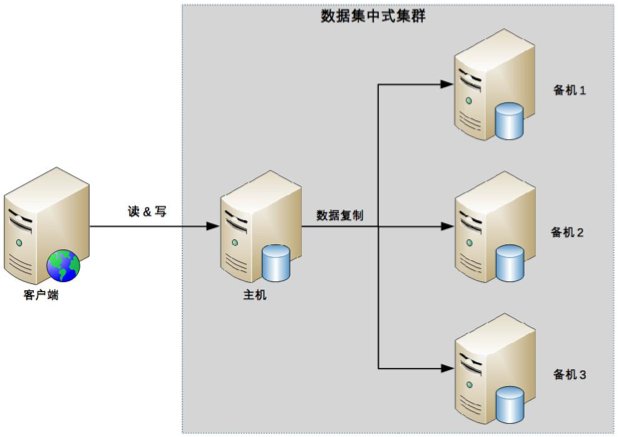
目前开源的数据集中集群以 ZooKeeper 为典型,ZooKeeper 通过 ZAB 算法来解决上述提到的几个问题,但 ZAB 算法的复杂度是很高的。
数据分散集群指多个服务器组成一个集群,每台服务器都会负责存储一部分数据;同时,为了提升硬件利用率,每台服务器又会备份一部分数据。
数据分散集群和数据集中集群的不同点在于,数据分散集群中的每台服务器都可以处理读写请求,因此不存在数据集中集群中负责写的主机那样的角色。但在数据分散集群中,必须有一个角色来负责执行数据分配算法,这个角色可以是独立的一台服务器,也可以是集群自己选举出的一台服务器。如果是集群服务器选举出来一台机器承担数据分区分配的职责,则这台服务器一般也会叫作主机,但我们需要知道这里的“主机”和数据集中集群中的“主机”,其职责是有差异的。
Hadoop 的实现就是独立的服务器负责数据分区的分配,这台服务器叫作 Namenode。Hadoop 的数据分区管理架构如下:

与 Hadoop 不同的是,Elasticsearch 集群通过选举一台服务器来做数据分区的分配,叫作 master node,其数据分区管理架构是:

数据集中集群架构中,客户端只能将数据写到主机;数据分散集群架构中,客户端可以向任意服务器中读写数据。正是因为这个关键的差异,决定了两种集群的应用场景不同。一般来说,数据集中集群适合数据量不大,集群机器数量不多的场景。例如,ZooKeeper 集群,一般推荐 5 台机器左右,数据量是单台服务器就能够支撑;而数据分散集群,由于其良好的可伸缩性,适合业务数据量巨大、集群机器数量庞大的业务场景。例如,Hadoop 集群、HBase 集群,大规模的集群可以达到上百台甚至上千台服务器。
数据分区
设计一个良好的数据分区架构,需要从多方面去考虑。
计算高可用的主要设计目标是当出现部分硬件损坏时,计算任务能够继续正常运行。因此计算高可用的本质是通过冗余来规避部分故障的风险,单台服务器是无论如何都达不到这个目标的。所以计算高可用的设计思想很简单:通过增加更多服务器来达到计算高可用。
计算高可用架构的设计复杂度主要体现在任务管理方面,即当任务在某台服务器上执行失败后,如何将任务重新分配到新的服务器进行执行。因此,计算高可用架构设计的关键点有下面两点。
接下来,我将详细阐述常见的计算高可用架构:主备、主从和集群。
主备
主备架构是计算高可用最简单的架构,和存储高可用的主备复制架构类似,但是要更简单一些,因为计算高可用的主备架构无须数据复制,其基本的架构示意图如下:
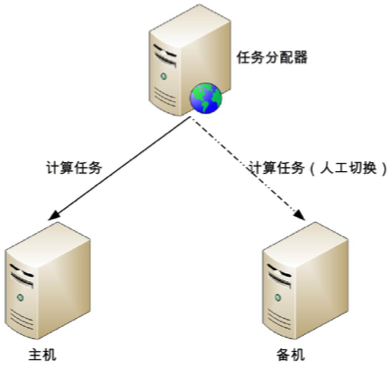
根据备机状态的不同,主备架构又可以细分为冷备架构和温备架构。一般情况下推荐用温备的方式。
和存储高可用中的主备复制架构类似,计算高可用的主备架构也比较适合与内部管理系统、后台管理系统这类使用人数不多、使用频率不高的业务,不太适合在线的业务。
主从
和存储高可用中的主从复制架构类似,计算高可用的主从架构中的从机也是要执行任务的。任务分配器需要将任务进行分类,确定哪些任务可以发送给主机执行,哪些任务可以发送给备机执行,其基本的架构示意图如下:

集群
主备架构和主从架构通过冗余一台服务器来提升可用性,且需要人工来切换主备或者主从。这样的架构虽然简单,但存在一个主要的问题:人工操作效率低、容易出错、不能及时处理故障。因此在可用性要求更加严格的场景中,我们需要系统能够自动完成切换操作,这就是高可用集群方案。
高可用计算的集群方案根据集群中服务器节点角色的不同,可以分为两类:一类是对称集群,即集群中每个服务器的角色都是一样的,都可以执行所有任务;另一类是非对称集群,集群中的服务器分为多个不同的角色,不同的角色执行不同的任务,例如最常见的 Master-Slave 角色。
对称集群更通俗的叫法是负载均衡集群,因此接下来我使用“负载均衡集群”这个通俗的说法,架构示意图如下:
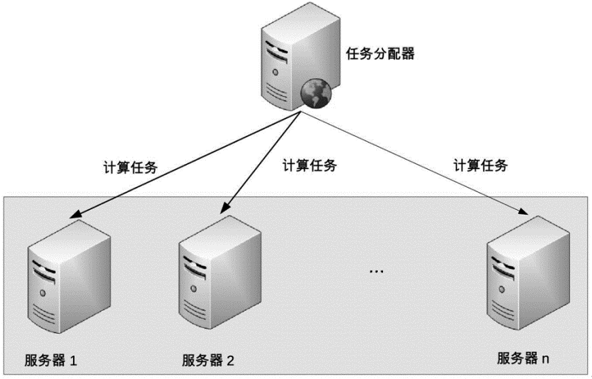
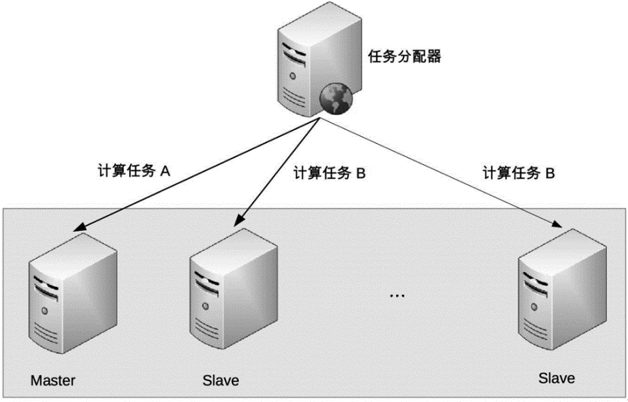
非对称集群中不同服务器的角色是不同的,不同角色的服务器承担不同的职责。以 Master-Slave 为例,部分任务是 Master 服务器才能执行,部分任务是 Slave 服务器才能执行。非对称集群的基本架构示意图如下:
计算高可用架构从形式上和存储高可用架构看上去几乎一样,它们的复杂度是一样的么?谈谈你的理解。
计算高可用架构,主要解决当单点发生故障后,原本发送到故障节点的任务,任务如何分发给非故障节点,根据业务特点选择分发和重试机制即可,不存在数据一致性问题,只需要保证任务计算完成即可。
存储高可用架构,解决的问题是当单点发生故障了,任务如何分发给其他非故障节点,以及如何保障数据的一致性问题。
所以存储的高可用比计算的高可用的设计更为复杂。
顾名思义,异地多活架构的关键点就是异地、多活,其中异地就是指地理位置上不同的地方,类似于“不要把鸡蛋都放在同一篮子里”;多活就是指不同地理位置上的系统都能够提供业务服务,这里的“活”是活动、活跃的意思。判断一个系统是否符合异地多活,需要满足两个标准:
因此,异地多活虽然功能很强大,但也不是每个业务不管三七二十一都要上异地多活。例如,常见的新闻网站、企业内部的 IT 系统、游戏、博客站点等,如果无法承受异地多活带来的复杂度和成本,是可以不做异地多活的,只需要做异地备份即可。因为这类业务系统即使中断,对用户的影响并不会很大,例如,A 新闻网站看不了,用户换个新闻网站即可。而共享单车、滴滴出行、支付宝、微信这类业务,就需要做异地多活了,这类业务系统中断后,对用户的影响很大。例如,支付宝用不了,就没法买东西了;滴滴用不了,用户就打不到车了。
架构模式
根据地理位置上的距离来划分,异地多活架构可以分为同城异区、跨城异地、跨国异地。
关键在于搭建高速网络将两个机房连接起来,达到近似一个本地机房的效果。架构设计上可以将两个机房当作本地机房来设计,无须额外考虑。
关键在于数据不一致的情况下,业务不受影响或者影响很小,这从逻辑的角度上来说其实是矛盾的,架构设计的主要目的就是为了解决这个矛盾。
主要是面向不同地区用户提供业务,或者提供只读业务,对架构设计要求不高。
技巧 1:保证核心业务的异地多活
技巧 2:保证核心数据最终一致性
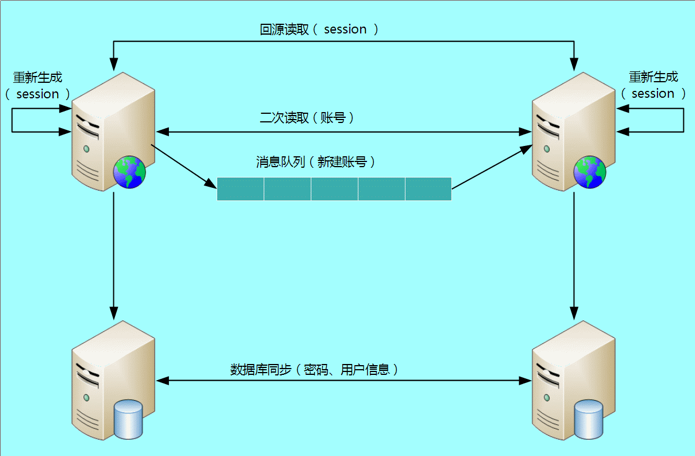
技巧 3:采用多种手段同步数据
综合上述的各种措施,最后“用户子系统”同步方式整体如下:
核心思想
异地多活设计的理念可以总结为一句话:采用多种手段,保证绝大部分用户的核心业务异地多活!
今天,在掌握这 4 大技巧的基础上,我来讲讲跨城异地多活架构设计的 4 个步骤。
我们同样以用户管理系统的登录业务为例,简单分析如下表所示。
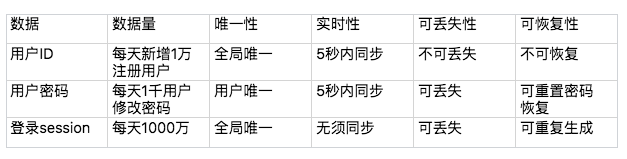
我们同样以用户管理系统的登录业务为例,针对不同的数据特点设计不同的同步方案,如下表所示。

常见的异常处理措施有这几类:多通道同步、同步和访问结合、日志记录、用户补偿
导致接口级故障的原因一般有下面几种:
解决接口级故障的核心思想和异地多活基本类似:优先保证核心业务和优先保证绝大部分用户。
降级
降级指系统将某些业务或者接口的功能降低,可以是只提供部分功能,也可以是完全停掉所有功能。例如,论坛可以降级为只能看帖子,不能发帖子;也可以降级为只能看帖子和评论,不能发评论;而 App 的日志上传接口,可以完全停掉一段时间,这段时间内 App 都不能上传日志。
降级的核心思想就是丢车保帅,优先保证核心业务。例如,对于论坛来说,90% 的流量是看帖子,那我们就优先保证看帖的功能;对于一个 App 来说,日志上传接口只是一个辅助的功能,故障时完全可以停掉。
常见的实现降级的方式有:
熔断
熔断和降级是两个比较容易混淆的概念,因为单纯从名字上看好像都有禁止某个功能的意思,但其实内在含义是不同的,原因在于降级的目的是应对系统自身的故障,而熔断的目的是应对依赖的外部系统故障的情况。
熔断机制实现的关键是需要有一个统一的 API 调用层,由 API 调用层来进行采样或者统计,如果接口调用散落在代码各处就没法进行统一处理了。
熔断机制实现的另外一个关键是阈值的设计,例如 1 分钟内 30% 的请求响应时间超过 1 秒就熔断,这个策略中的“1 分钟”“30%”“1 秒”都对最终的熔断效果有影响。实践中一般都是先根据分析确定阈值,然后上线观察效果,再进行调优。
限流
降级是从系统功能优先级的角度考虑如何应对故障,而限流则是从用户访问压力的角度来考虑如何应对故障。限流指只允许系统能够承受的访问量进来,超出系统访问能力的请求将被丢弃。
限流一般都是系统内实现的,常见的限流方式可以分为两类:基于请求限流和基于资源限流。
基于请求限流指从外部访问的请求角度考虑限流,常见的方式有:限制总量、限制时间量。
限制总量的方式是限制某个指标的累积上限,常见的是限制当前系统服务的用户总量,例如某个直播间限制总用户数上限为 100 万,超过 100 万后新的用户无法进入;某个抢购活动商品数量只有 100 个,限制参与抢购的用户上限为 1 万个,1 万以后的用户直接拒绝。限制时间量指限制一段时间内某个指标的上限,例如,1 分钟内只允许 10000 个用户访问,每秒请求峰值最高为 10 万。
基于上述的分析,根据阈值来限制访问量的方式更多的适应于业务功能比较简单的系统,例如负载均衡系统、网关系统、抢购系统等。
基于请求限流是从系统外部考虑的,而基于资源限流是从系统内部考虑的,即:找到系统内部影响性能的关键资源,对其使用上限进行限制。常见的内部资源有:连接数、文件句柄、线程数、请求队列等。
例如,采用 Netty 来实现服务器,每个进来的请求都先放入一个队列,业务线程再从队列读取请求进行处理,队列长度最大值为 10000,队列满了就拒绝后面的请求;也可以根据 CPU 的负载或者占用率进行限流,当 CPU 的占用率超过 80% 的时候就开始拒绝新的请求。
排队
排队实际上是限流的一个变种,限流是直接拒绝用户,排队是让用户等待一段时间,全世界最有名的排队当属 12306 网站排队了。排队虽然没有直接拒绝用户,但用户等了很长时间后进入系统,体验并不一定比限流好。
由于排队需要临时缓存大量的业务请求,单个系统内部无法缓存这么多数据,一般情况下,排队需要用独立的系统去实现,例如使用 Kafka 这类消息队列来缓存用户请求。
下面是 1 号店的“双 11”秒杀排队系统架构
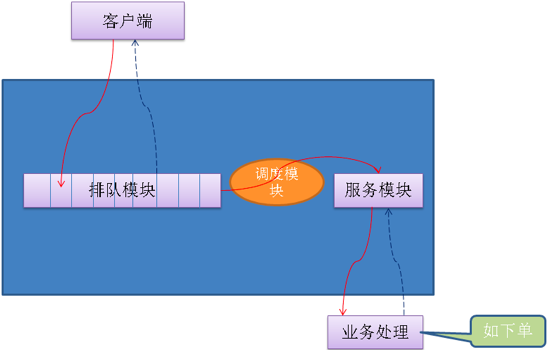
负责接收用户的抢购请求,将请求以先入先出的方式保存下来。每一个参加秒杀活动的商品保存一个队列,队列的大小可以根据参与秒杀的商品数量(或加点余量)自行定义。
负责排队模块到服务模块的动态调度,不断检查服务模块,一旦处理能力有空闲,就从排队队列头上把用户访问请求调入服务模块,并负责向服务模块分发请求。这里调度模块扮演一个中介的角色,但不只是传递请求而已,它还担负着调节系统处理能力的重任。我们可以根据服务模块的实际处理能力,动态调节向排队系统拉取请求的速度。
负责调用真正业务来处理服务,并返回处理结果,调用排队模块的接口回写业务处理结果。
版权声明:本站所有资料均为网友推荐收集整理而来,仅供学习和研究交流使用。

工作时间:8:00-18:00
客服电话
电子邮件
admin@qq.com
扫码二维码
获取最新动态