MHA(Master High Availability)是一套比较成熟的 MySQL 高可用方案,也是一款优秀的故障切换和主从提升的高可用软件。在MySQL故障切换过程中,MHA能做到在30秒之内自动完成数据库的故障切换操作,并且在进行故障切换的过程中,MHA能在最大程度上保证数据的一致性,以达到真正意义上的高可用。MHA还支持在线快速将Master切换到其他主机,通常只需0.5-2秒。目前MHA主要支持一主多从的架构,要搭建MHA,要求一个复制集群中必须最少有三台数据库服务器。

MHA由两部分组成:MHA Manager(管理节点)和MHA Node(数据节点)。
微服务架构高可用、MHA Manager可以单独部署在一台独立的机器上管理多个master-slave集群,也可以部署在一台slave节点上。负责检测master是否宕机、控制故障转移、检查MySQL复制状况等。
MHA Node运行在每台MySQL服务器上,不管是Master角色,还是Slave角色,都称为Node,是被监控管理的对象节点,负责保存和复制master的二进制日志、识别差异的中继日志事件并将其差异的事件应用于其他的slave、清除中继日志。
MHA Manager会定时探测集群中的master节点,当master出现故障时,它可以自动将最新数据的slave提升为新的master,然后将所有其他的slave重新指向新的master,整个故障转移过程对应用程序完全透明。
centos集群服务器搭建,MHA故障处理机制:
MHA优点:

高可用java架构图、准备工作1:节点搭建,修改节点主机名称和ip地址
| 节点ip地址(修改网卡信息) | 主机名称 (修改 /etc/hostname) |
|---|---|
| 192.168.80.110 | mhaManager |
| 192.168.80.128 | master |
| 192.168.80.55 | slave1 |
| 192.168.80.56 | slave2 |
准备工作2:
主从搭建,一主两从(实现半同步或者同步复制都可以)
参考地址:半同步或者同步复制搭建流程
haproxy高可用架构测试。测试:在master上添加一条数据 ,在slave1和slave2上同步此条数据
MHA搭建步骤1:
保证MHAManager,Master,Slave1,Slave2四台机器ssh互通在四台服务器上分别执行下面命令,生成公钥和私钥,命令执行过程中一直换行回车采用默认值进行生成即可
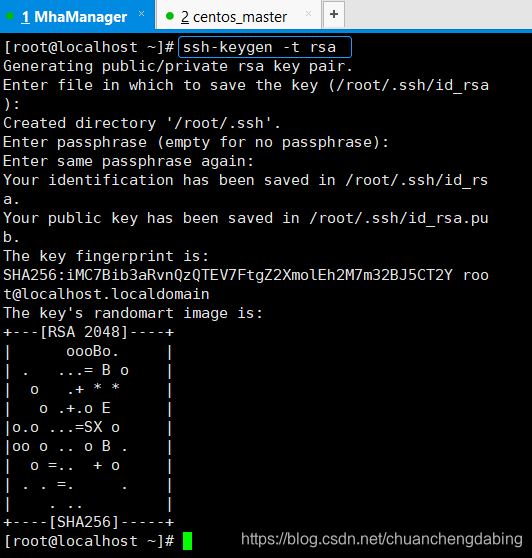
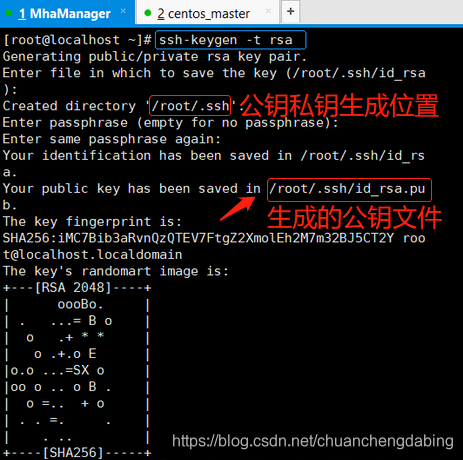
将四台机器的公钥(公钥所在位置:/root/.ssh/id_rsa.pub)复制到同一个文件中authorized_keys,authorized_keys文件中的内容如下:包含了四台节点的公钥信息

将此文件authorized_keys在四台机器中进行复制,此文件的复制位置是: /root/.ssh/authorized_keys
测试无密登陆:从 从节点 登陆主节点

搭建步骤2:
MHA下载安装修改yum源,下载wget工具
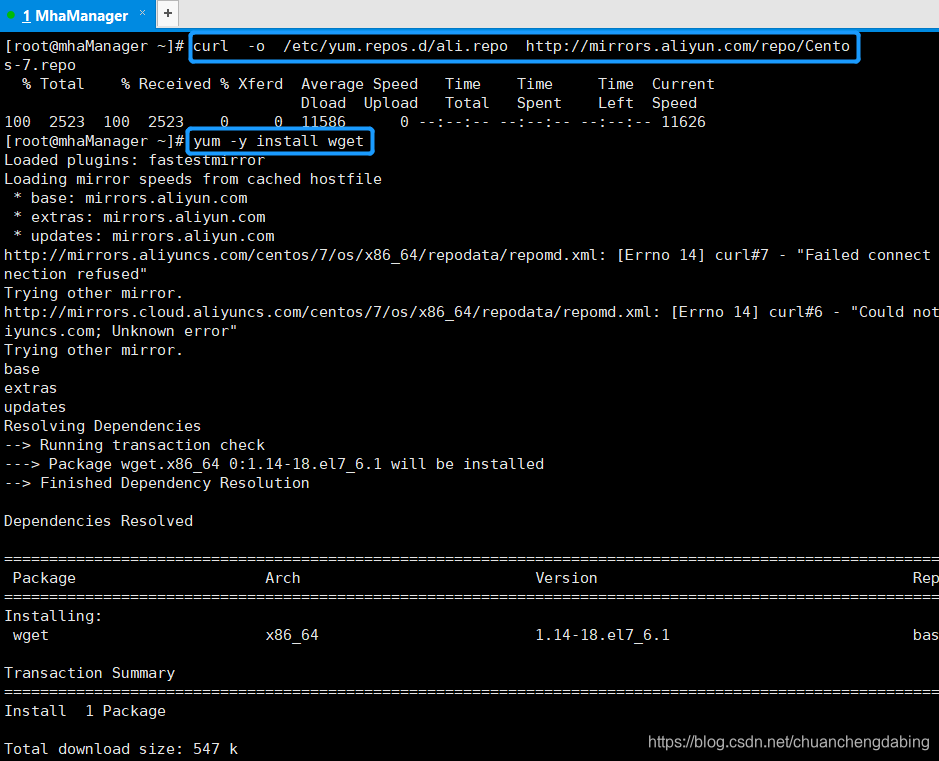
MHA版本下载注意
MySQL5.7对应的MHA版本是0.5.8,所以在GitHub上找到对应的rpm包进行下载,MHA manager和node的安装包需要分别下载:https://github.com/yoshinorim下载后,将Manager和Node的安装包分别上传到对应的服务器。(可使用WinSCP等工具)
| 名称 | 网盘下载地址 | 在线下载命令 |
|---|---|---|
| MHA manager | 链接: 提取码:5555 | wget https://github.com/yoshinorim/mha4mysql-manager/releases/download/v0.58/mha4mysql-manager-0.58-0.el7.centos.noarch.rpm |
| node | 链接: 提取码:5555 | wget https://github.com/yoshinorim/mha4mysql-node/releases/download/v0.58/mha4mysql-node-0.58-0.el7.centos.noarch.rpm |
搭建步骤3:MHA node安装(三台MySQL服务器需要安装node)
注意:按照顺序
注意1:MHA的Node依赖于perl-DBD-MySQL,所以要先安装perl-DBD-MySQL注意2:MHA的manager又依赖了perl-Config-Tiny、perl-Log-Dispatch、perl-Parallel-ForkManager注意3:由于perl-Log-Dispatch和perl-Parallel-ForkManager这两个被依赖包在yum仓库找不到(国内的yum源找不到),因此安装epel-release-latest-7.noarch.rpm(软件源)
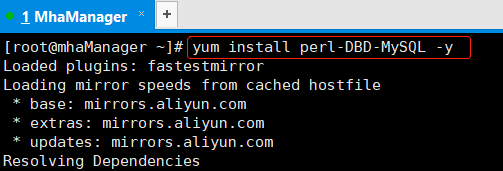
在四台服务器上安装mha4mysql-node
MHA的Node依赖于perl-DBD-MySQL,所以要先安装perl-DBD-MySQLyum install perl-DBD-MySQL -y
# 安装mha4mysql-noderpm -ivh mha4mysql-node-0.58-0.el7.centos.noarch.rpm
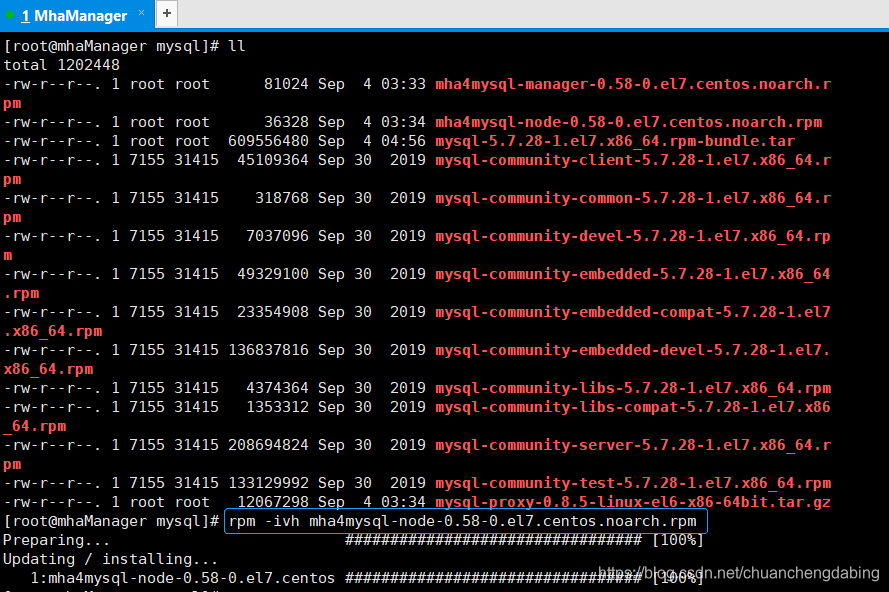
搭建步骤4:MHA manager安装:
# 在MHA Manager服务器已经安装了 mha4mysql-node
# 再继续安装 mha4mysql-manager
# MHA的manager又依赖了perl-Config-Tiny、perl-Log-Dispatch、perl-Parallel-ForkManager,也分别进行安装 # 注意:由于perl-Log-Dispatch和perl-Parallel-ForkManager这两个被依赖包在yum仓库找不到(国内的yum源找不到),因此安装epel-release-latest-7.noarch.rpm(软件源)rpm -ivh epel-release-latest-7.noarch.rpm # 安装epel软件源
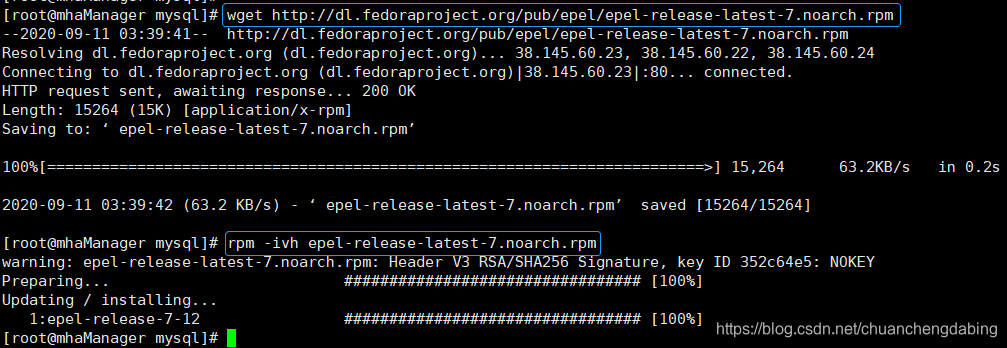
# MHA的manager又依赖了perl-Config-Tiny、perl-Log-Dispatch、perl-Parallel-ForkManager,也分别进行安装 yum install perl-DBD-MySQL perl-Config-Tiny perl-Log-Dispatch perl-Parallel-ForkManager -y
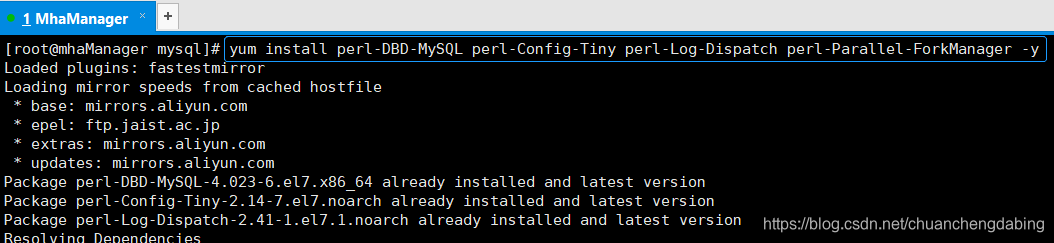
# 安装mha4mysql-managerrpm -ivh mha4mysql-manager-0.58-0.el7.centos.noarch.rpm

提示:由于perl-Log-Dispatch和perl-Parallel-ForkManager这两个被依赖包在yum仓库找不到(国内的yum源找不到),
因此安装epel-release-latest-7.noarch.rpm(软件源)。在使用时,可能会出现下面异常:Cannot
retrieve metalink for repository: epel/x86_64。可以尝试使
用/etc/yum.repos.d/epel.repo,然后注释掉mirrorlist,取消注释baseurl。
搭建步骤5:MHA 配置文件:
MHA 配置文件MHA Manager服务器需要为每个监控的 Master/Slave 集群提供一个专用的配置文件,而所有的Master/Slave 集群也可共享全局配置。
初始化配置目录
#目录说明
#/var/log (CentOS目录)
# /mha (MHA监控根目录)
# /app1 (MHA监控实例根目录)
# /manager.log (MHA监控实例日志文件)
配置监控全局配置文件:
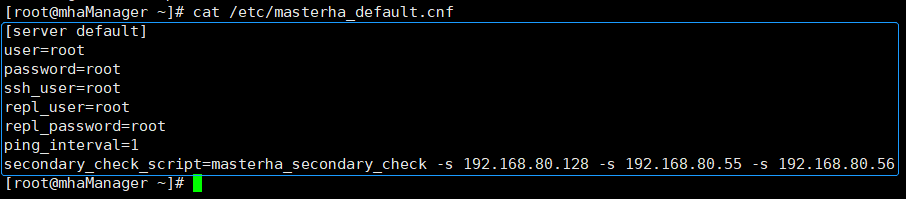
vim /etc/masterha_default.cnf
参数说明:
# 填写mha的账户 (此账户是在master主节点数据库中创建的账户,可以使用root账户,也可以单独在master上的mysql数据库中创建一个账户)user=xxx 注意:此账户一定需要有远程访问权限# 填写mha的密码password=xxx # 使用ssh命令的账户ssh_user=xxx # 主库和从库的mysql账户(master和slave的mysql密码需要保持一致)repl_user=xxx
# 主库和从库的mysql密码(master和slave的mysql密码需要保持一致)repl_password=xxx
配置监控实例配置文件:
mkdir -p /var/log/mha/app1touch /var/log/mha/app1/manager.logvim /etc/mha/app1.cnf
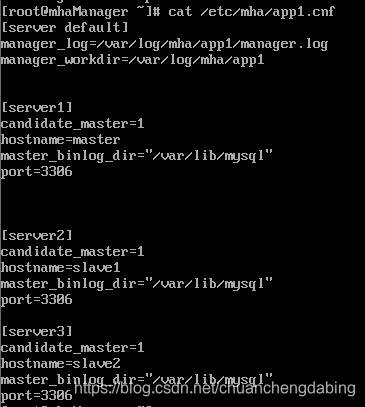
搭建步骤6:MHA 配置检测:
执行ssh通信检测在MHA Manager服务器上执行:masterha_check_ssh --conf=/etc/mha/app1.cnf
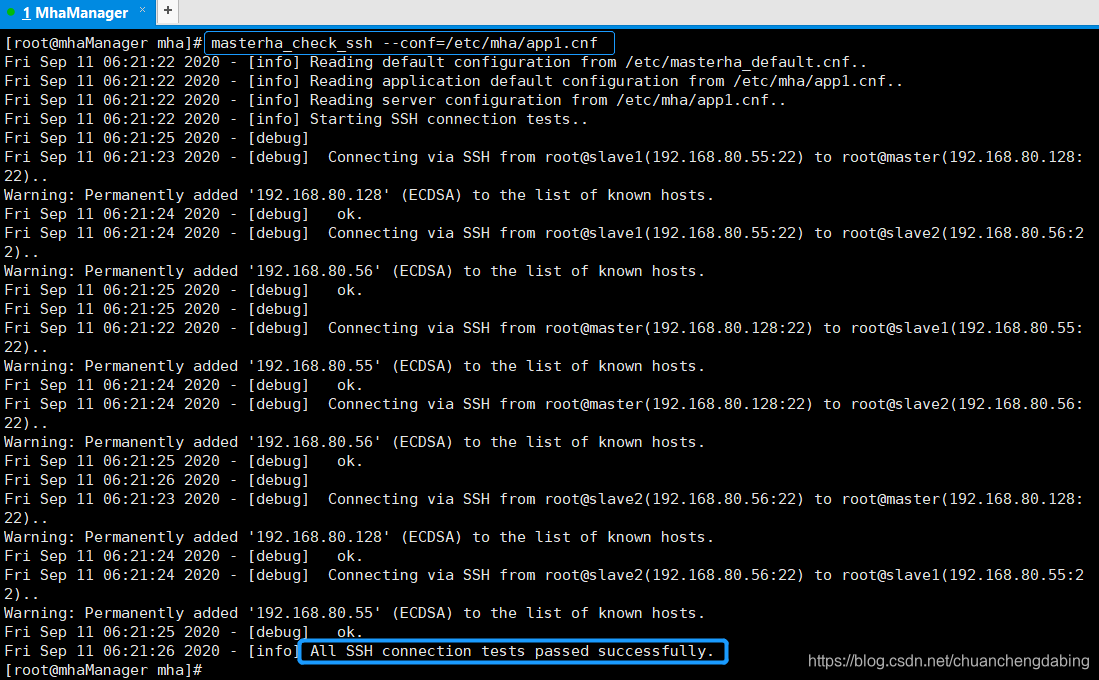
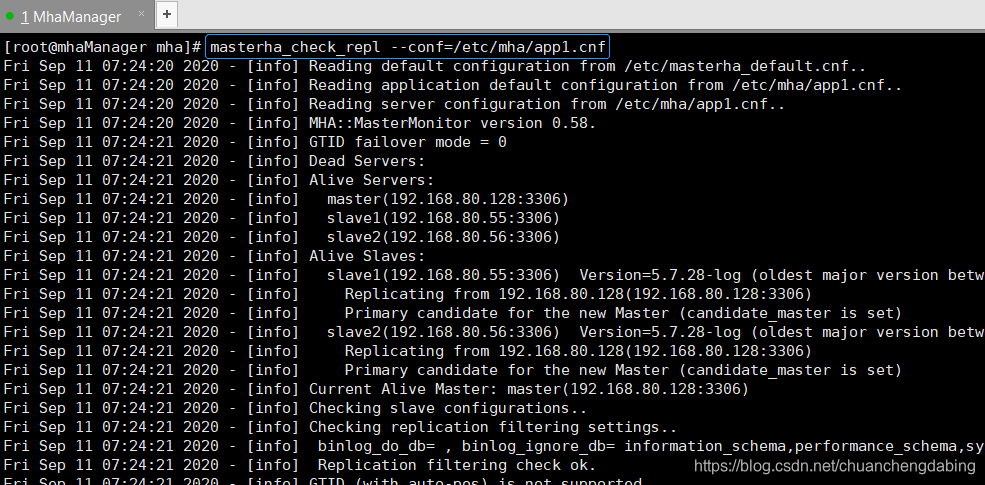
搭建步骤7:检测MySQL主从复制:
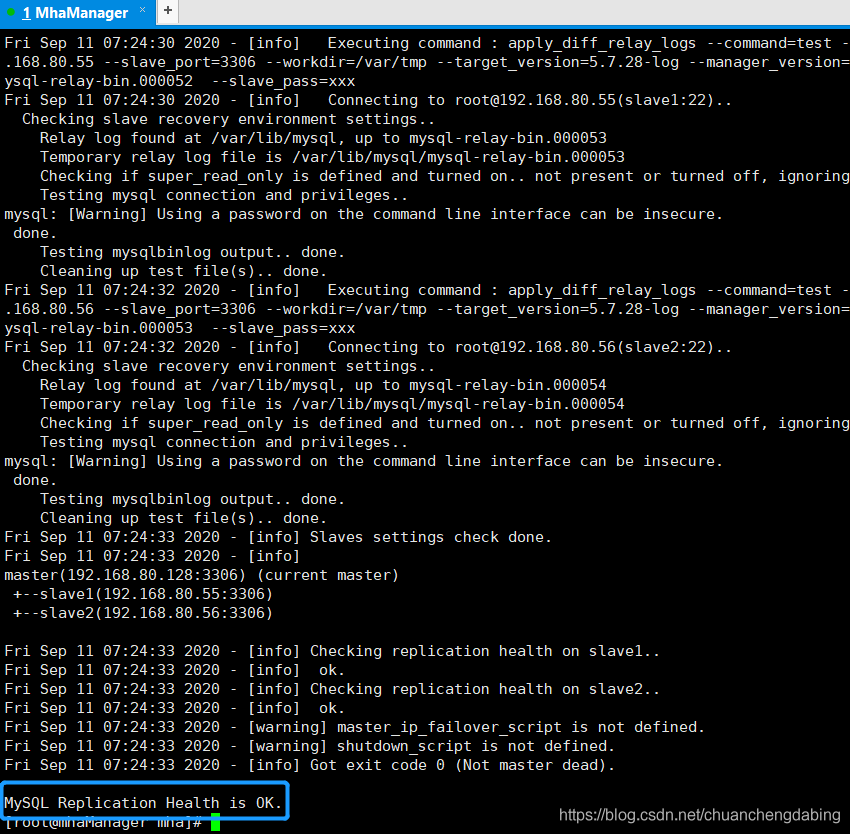
在MHA Manager服务器上执行:masterha_check_repl --conf=/etc/mha/app1.cnf出现“MySQL Replication Health is OK.”证明MySQL复制集群没有问题。
搭建步骤8:MHA Manager启动:
在MHA Manager服务器上执行:nohup masterha_manager --conf=/etc/mha/app1.cnf --remove_dead_master_conf --ignore_last_failover < /dev/null > /var/log/mha/app1/manager.log 2>&1 &

查看监控状态命令如下:masterha_check_status --conf=/etc/mha/app1.cnf

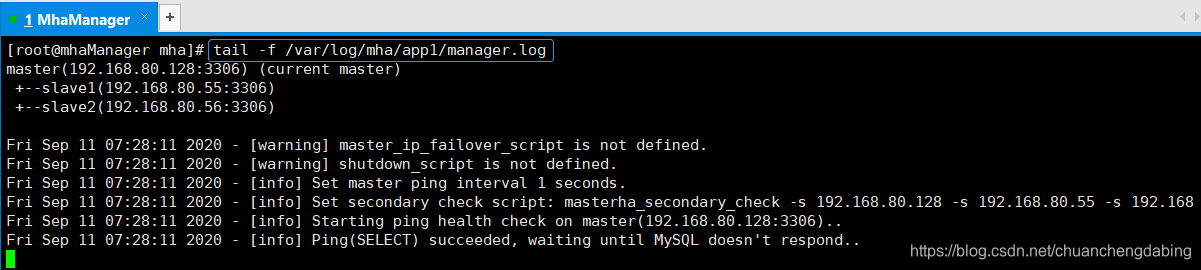
查看监控日志命令如下:tail -f /var/log/mha/app1/manager.log
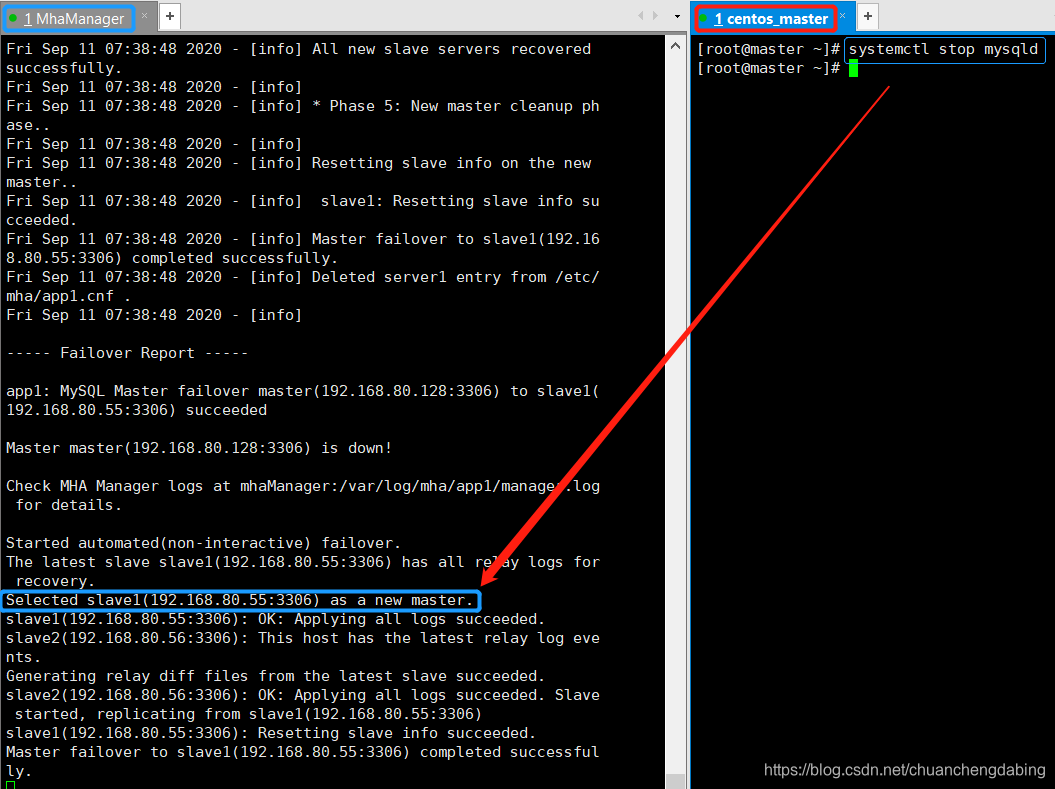
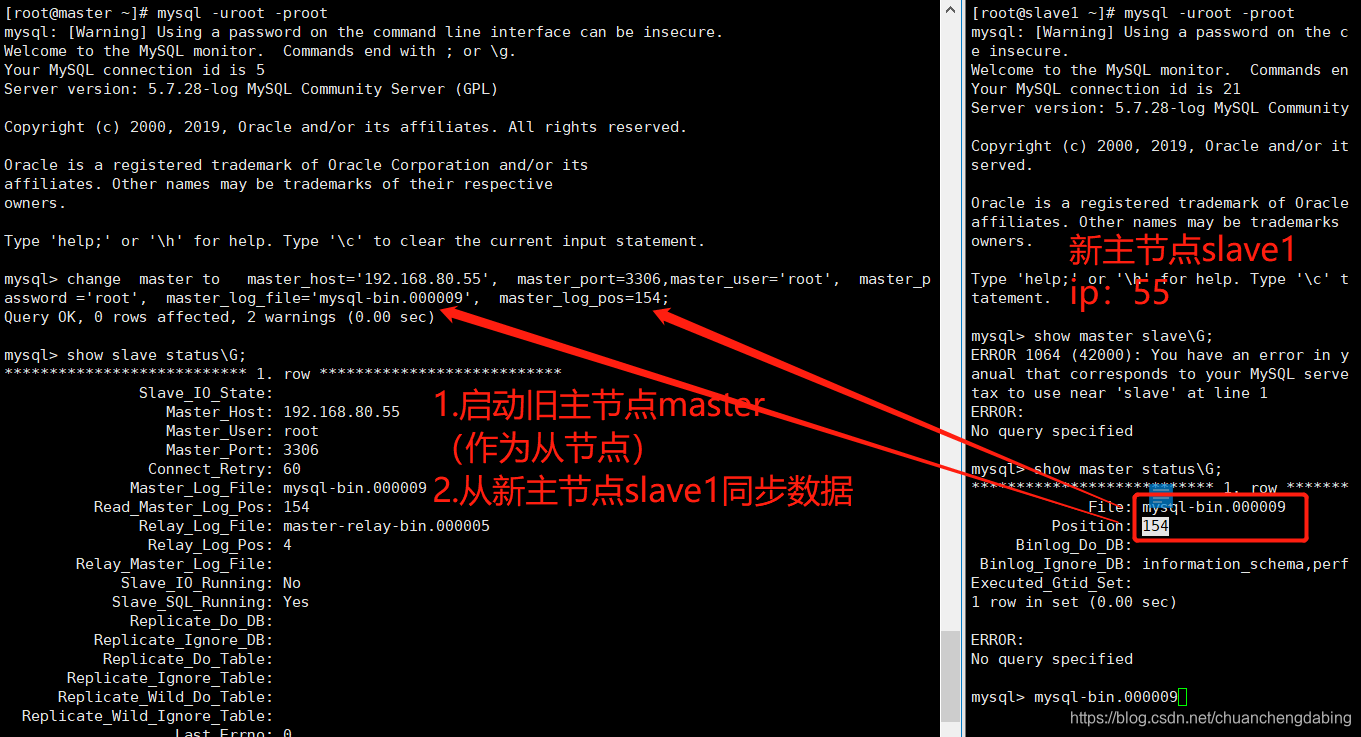
搭建步骤9:测试MHA故障转移(模拟主节点崩溃)
在MHA Manager服务器执行打开日志命令:tail -200f /var/log/masterha/app1/app1.log关闭Master MySQL服务器服务,模拟主节点崩溃:systemctl stop mysqld查看MHA日志,可以看到哪台slave切换成了master:show master status;
systemctl start mysqld

change master to master_host='192.168.80.55', master_port=3306,master_user='root', master_password ='root', master_log_file='xxx', master_log_pos=当前新主节点的日志位置;start slave; // 开启同步
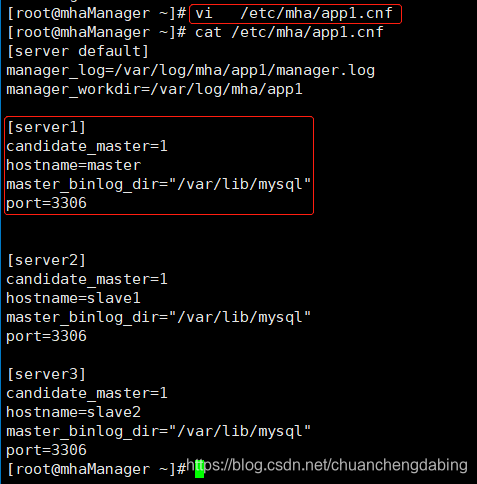
vi /etc/mha/app1.cnf#添加节点
结束MHA Manager进程:
masterha_stop --global_conf=/etc/masterha/masterha_default.conf --conf=/etc/mha/app1.cnf

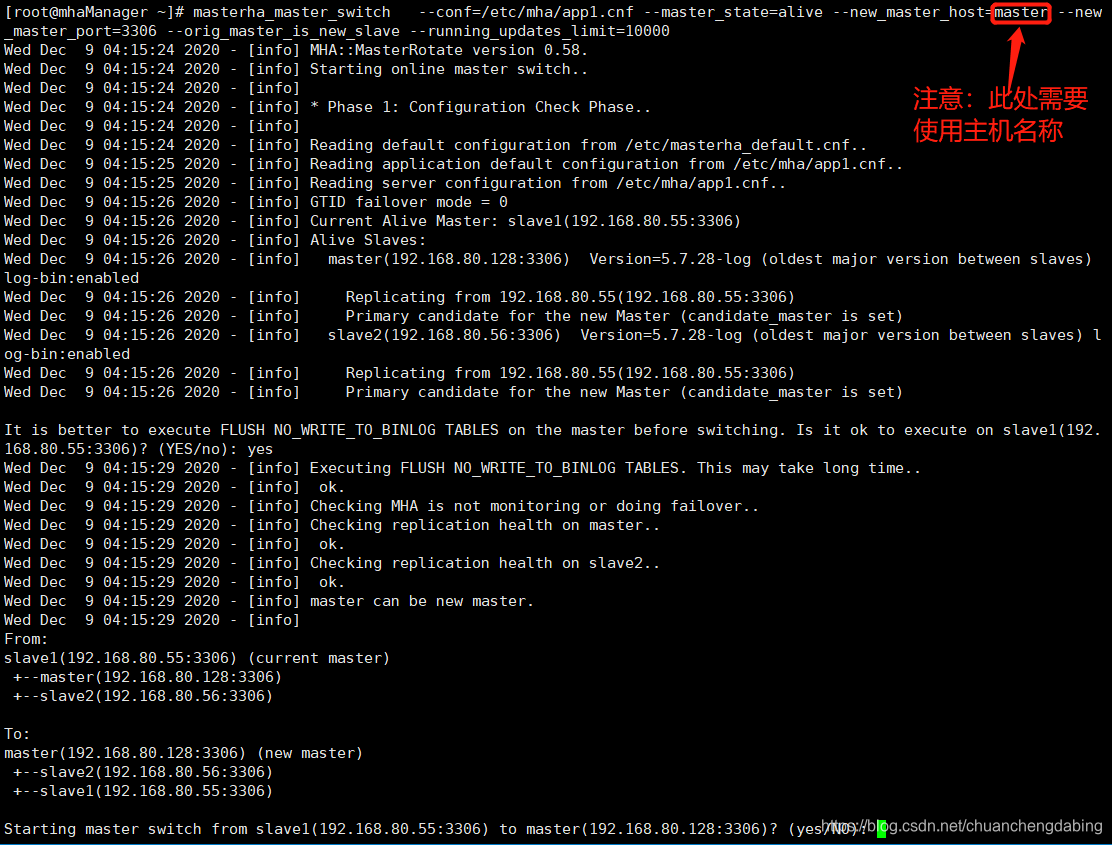
执行切换命令: masterha_master_switch --conf=/etc/mha/app1.cnf --master_state=alive --new_master_host=master--new_master_port=3306 --orig_master_is_new_slave--running_updates_limit=10000
注意:
master如果使用ip地址,会报错:[error][/usr/share/perl5/vendor_perl/MHA/ServerManager.pm, ln1218] 192.168.80.128 is not alive!需要将ip地址设置成主机名即可
完整的执行脚本如下:
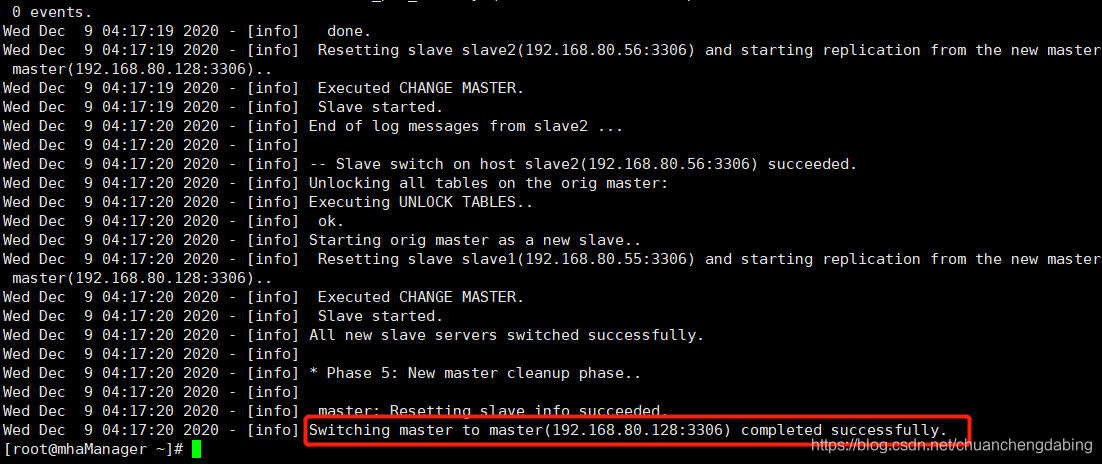
[root@mhaManager ~]# masterha_master_switch --conf=/etc/mha/app1.cnf --master_state=alive --new_master_host=master --new_master_port=3306 --orig_master_is_new_slave --running_updates_limit=10000Wed Dec 9 04:15:24 2020 - [info] MHA::MasterRotate version 0.58.Wed Dec 9 04:15:24 2020 - [info] Starting online master switch..Wed Dec 9 04:15:24 2020 - [info] Wed Dec 9 04:15:24 2020 - [info] * Phase 1: Configuration Check Phase..Wed Dec 9 04:15:24 2020 - [info] Wed Dec 9 04:15:24 2020 - [info] Reading default configuration from /etc/masterha_default.cnf..Wed Dec 9 04:15:25 2020 - [info] Reading application default configuration from /etc/mha/app1.cnf..Wed Dec 9 04:15:25 2020 - [info] Reading server configuration from /etc/mha/app1.cnf..Wed Dec 9 04:15:26 2020 - [info] GTID failover mode = 0Wed Dec 9 04:15:26 2020 - [info] Current Alive Master: slave1(192.168.80.55:3306)Wed Dec 9 04:15:26 2020 - [info] Alive Slaves:Wed Dec 9 04:15:26 2020 - [info] master(192.168.80.128:3306) Version=5.7.28-log (oldest major version between slaves) log-bin:enabledWed Dec 9 04:15:26 2020 - [info] Replicating from 192.168.80.55(192.168.80.55:3306)Wed Dec 9 04:15:26 2020 - [info] Primary candidate for the new Master (candidate_master is set)Wed Dec 9 04:15:26 2020 - [info] slave2(192.168.80.56:3306) Version=5.7.28-log (oldest major version between slaves) log-bin:enabledWed Dec 9 04:15:26 2020 - [info] Replicating from 192.168.80.55(192.168.80.55:3306)Wed Dec 9 04:15:26 2020 - [info] Primary candidate for the new Master (candidate_master is set)It is better to execute FLUSH NO_WRITE_TO_BINLOG TABLES on the master before switching. Is it ok to execute on slave1(192.168.80.55:3306)? (YES/no): yesWed Dec 9 04:15:29 2020 - [info] Executing FLUSH NO_WRITE_TO_BINLOG TABLES. This may take long time..Wed Dec 9 04:15:29 2020 - [info] ok.Wed Dec 9 04:15:29 2020 - [info] Checking MHA is not monitoring or doing failover..Wed Dec 9 04:15:29 2020 - [info] Checking replication health on master..Wed Dec 9 04:15:29 2020 - [info] ok.Wed Dec 9 04:15:29 2020 - [info] Checking replication health on slave2..Wed Dec 9 04:15:29 2020 - [info] ok.Wed Dec 9 04:15:29 2020 - [info] master can be new master.Wed Dec 9 04:15:29 2020 - [info] From:slave1(192.168.80.55:3306) (current master)+--master(192.168.80.128:3306)+--slave2(192.168.80.56:3306)To:master(192.168.80.128:3306) (new master)+--slave2(192.168.80.56:3306)+--slave1(192.168.80.55:3306)Starting master switch from slave1(192.168.80.55:3306) to master(192.168.80.128:3306)? (yes/NO): yesWed Dec 9 04:17:17 2020 - [info] Checking whether master(192.168.80.128:3306) is ok for the new master..Wed Dec 9 04:17:17 2020 - [info] ok.Wed Dec 9 04:17:17 2020 - [info] slave1(192.168.80.55:3306): SHOW SLAVE STATUS returned empty result. To check replication filtering rules, temporarily executing CHANGE MASTER to a dummy host.Wed Dec 9 04:17:17 2020 - [info] slave1(192.168.80.55:3306): Resetting slave pointing to the dummy host.Wed Dec 9 04:17:17 2020 - [info] ** Phase 1: Configuration Check Phase completed.Wed Dec 9 04:17:17 2020 - [info] Wed Dec 9 04:17:17 2020 - [info] * Phase 2: Rejecting updates Phase..Wed Dec 9 04:17:17 2020 - [info] master_ip_online_change_script is not defined. If you do not disable writes on the current master manually, applications keep writing on the current master. Is it ok to proceed? (yes/NO): yesWed Dec 9 04:17:19 2020 - [info] Locking all tables on the orig master to reject updates from everybody (including root):Wed Dec 9 04:17:19 2020 - [info] Executing FLUSH TABLES WITH READ LOCK..Wed Dec 9 04:17:19 2020 - [info] ok.Wed Dec 9 04:17:19 2020 - [info] Orig master binlog:pos is mysql-bin.000009:313.Wed Dec 9 04:17:19 2020 - [info] Waiting to execute all relay logs on master(192.168.80.128:3306)..Wed Dec 9 04:17:19 2020 - [info] master_pos_wait(mysql-bin.000009:313) completed on master(192.168.80.128:3306). Executed 0 events.Wed Dec 9 04:17:19 2020 - [info] done.Wed Dec 9 04:17:19 2020 - [info] Getting new master's binlog name and position..Wed Dec 9 04:17:19 2020 - [info] mysql-bin.000002:154Wed Dec 9 04:17:19 2020 - [info] All other slaves should start replication from here. Statement should be: CHANGE MASTER TO MASTER_HOST='master or 192.168.80.128', MASTER_PORT=3306, MASTER_LOG_FILE='mysql-bin.000002', MASTER_LOG_POS=154, MASTER_USER='root', MASTER_PASSWORD='xxx';Wed Dec 9 04:17:19 2020 - [info] Wed Dec 9 04:17:19 2020 - [info] * Switching slaves in parallel..Wed Dec 9 04:17:19 2020 - [info] Wed Dec 9 04:17:19 2020 - [info] -- Slave switch on host slave2(192.168.80.56:3306) started, pid: 7789Wed Dec 9 04:17:19 2020 - [info] Wed Dec 9 04:17:20 2020 - [info] Log messages from slave2 ...Wed Dec 9 04:17:20 2020 - [info] Wed Dec 9 04:17:19 2020 - [info] Waiting to execute all relay logs on slave2(192.168.80.56:3306)..Wed Dec 9 04:17:19 2020 - [info] master_pos_wait(mysql-bin.000009:313) completed on slave2(192.168.80.56:3306). Executed 0 events.Wed Dec 9 04:17:19 2020 - [info] done.Wed Dec 9 04:17:19 2020 - [info] Resetting slave slave2(192.168.80.56:3306) and starting replication from the new master master(192.168.80.128:3306)..Wed Dec 9 04:17:19 2020 - [info] Executed CHANGE MASTER.Wed Dec 9 04:17:19 2020 - [info] Slave started.Wed Dec 9 04:17:20 2020 - [info] End of log messages from slave2 ...Wed Dec 9 04:17:20 2020 - [info] Wed Dec 9 04:17:20 2020 - [info] -- Slave switch on host slave2(192.168.80.56:3306) succeeded.Wed Dec 9 04:17:20 2020 - [info] Unlocking all tables on the orig master:Wed Dec 9 04:17:20 2020 - [info] Executing UNLOCK TABLES..Wed Dec 9 04:17:20 2020 - [info] ok.Wed Dec 9 04:17:20 2020 - [info] Starting orig master as a new slave..Wed Dec 9 04:17:20 2020 - [info] Resetting slave slave1(192.168.80.55:3306) and starting replication from the new master master(192.168.80.128:3306)..Wed Dec 9 04:17:20 2020 - [info] Executed CHANGE MASTER.Wed Dec 9 04:17:20 2020 - [info] Slave started.Wed Dec 9 04:17:20 2020 - [info] All new slave servers switched successfully.Wed Dec 9 04:17:20 2020 - [info] Wed Dec 9 04:17:20 2020 - [info] * Phase 5: New master cleanup phase..Wed Dec 9 04:17:20 2020 - [info] Wed Dec 9 04:17:20 2020 - [info] master: Resetting slave info succeeded.Wed Dec 9 04:17:20 2020 - [info] Switching master to master(192.168.80.128:3306) completed successfully.
查看切换日志文件,即可了解128节点是否再次切换为主节点
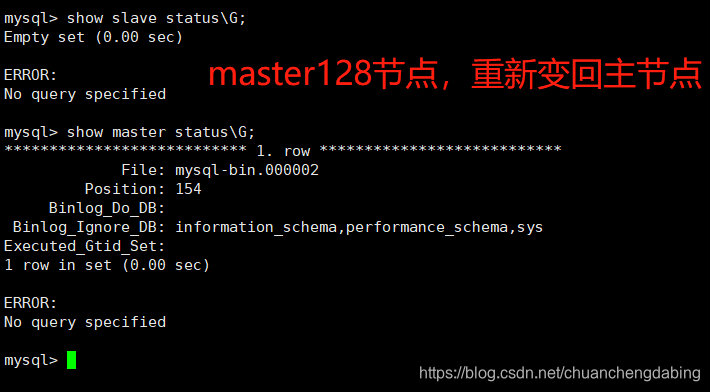
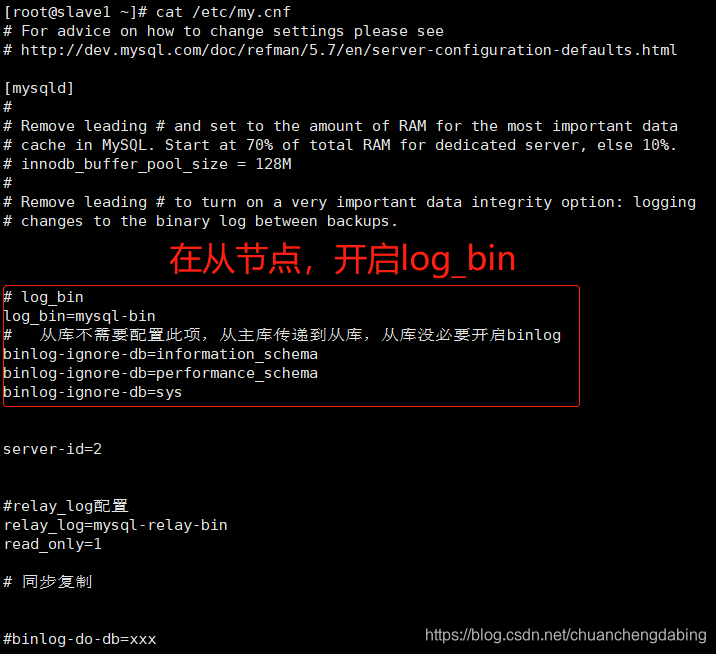
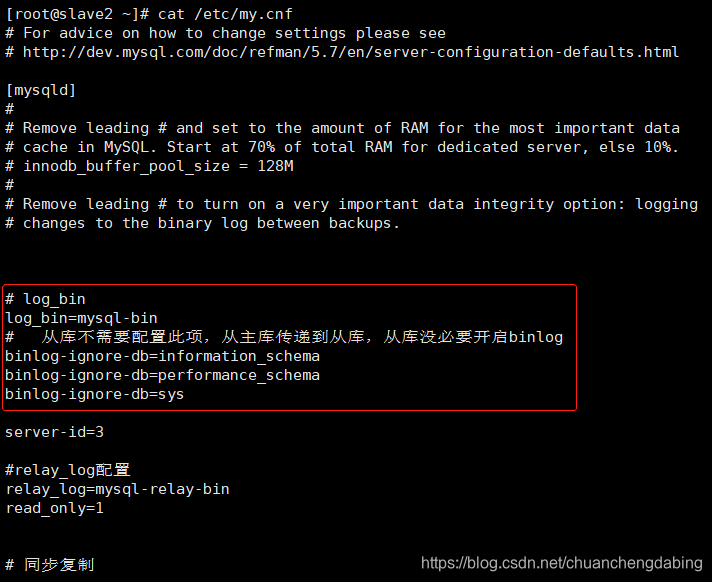
MHA安装报错None of slaves can be master. Check failover configuration file or log-bin settings in my.cnf修改:在俩个从节点开启log_bin
报错:[/usr/share/perl5/vendor_perl/MHA/ManagerUtil.pm, ln122] Got error when getting node version. Error:[/usr/share/perl5/vendor_perl/MHA/ManagerUtil.pm, ln123]bash: apply_diff_relay_logs: 未找到命令原因:node节点没有安装,在master和slave上执行解决:在master和slave节点上都需要安装nodewget https://github.com/yoshinorim/mha4mysql-node/releases/download/v0.58/mha4mysql-node-0.58-0.el7.centos.noarch.rpmrpm -ivh mha4mysql-node-0.58-0.el7.centos.noarch.rpm --force --nodeps
报错:[error][/usr/share/perl5/vendor_perl/MHA/MasterMonitor.pm, ln359] Slave configurations is not valid.[error][/usr/share/perl5/vendor_perl/MHA/MasterMonitor.pm, ln427] Error happened on checking configurations. at /usr/bin/masterha_check_repl line 48.[error][/usr/share/perl5/vendor_perl/MHA/MasterMonitor.pm, ln525] Error happened on monitoring servers.[info] Got exit code 1 (Not master dead).原因:主库和从库的my.cnf中配置的binlog-ignore-db和binlog-do-db要保持一致
主备切换是指将备库变为主库,主库变为备库,有可靠性优先和可用性优先两种策略。
主备延迟问题
主备延迟是由主从数据同步延迟导致的,与数据同步有关的时间点主要包括以下三个:* 主库 A 执行完成一个事务,写入 binlog,我们把这个时刻记为 T1;* 之后将binlog传给备库 B,我们把备库 B 接收完 binlog 的时刻记为 T2;* 备库 B 执行完成这个binlog复制,我们把这个时刻记为 T3。
所谓主备延迟,就是同一个事务,在备库执行完成的时间和主库执行完成的时间之间的差值,也就是 T3-T1。
在备库上执行show slave status命令,它可以返回结果信息,seconds_behind_master表示当前备库延迟了多少秒。
同步延迟主要原因如下:* 备库机器性能问题机器性能差,甚至一台机器充当多个主库的备库。* 分工问题备库提供了读操作,或者执行一些后台分析处理的操作,消耗大量的CPU资源。* 大事务操作大事务耗费的时间比较长,导致主备复制时间长。比如一些大量数据的delete或大表DDL操作都可能会引发大事务。
可靠性优先
主备切换过程一般由专门的HA高可用组件完成,但是切换过程中会存在短时间不可用,因为在切换过程中某一时刻主库A和从库B都处于只读状态。如下图所示:

主库由A切换到B,切换的具体流程如下:* 判断从库B的Seconds_Behind_Master值,当小于某个值才继续下一步* 把主库A改为只读状态(readonly=true)* 等待从库B的Seconds_Behind_Master值降为 0* 把从库B改为可读写状态(readonly=false)* 把业务请求切换至从库B
可用性优先
不等主从同步完成, 直接把业务请求切换至从库B ,并且让 从库B可读写 ,这样几乎不存在不可用时间,但可能会数据不一致。

如上图所示,在A切换到B过程中,执行两个INSERT操作,过程如下:* 主库A执行完 INSERT c=4 ,得到 (4,4) ,然后开始执行 主从切换* 主从之间有5S的同步延迟,从库B会先执行 INSERT c=5 ,得到 (4,5)* 从库B执行主库A传过来的binlog日志 INSERT c=4 ,得到 (5,4)* 主库A执行从库B传过来的binlog日志 INSERT c=5 ,得到 (5,5)* 此时主库A和从库B会有 两行 不一致的数据
通过上面介绍了解到,主备切换采用可用性优先策略,由于可能会导致数据不一致,所以大多数情况下,优先选择可靠性优先策略。在满足数据可靠性的前提下,MySQL的可用性依赖于同步延时的大小,同步延时越小,可用性就越高。
版权声明:本站所有资料均为网友推荐收集整理而来,仅供学习和研究交流使用。

工作时间:8:00-18:00
客服电话
电子邮件
admin@qq.com
扫码二维码
获取最新动态