首页
语法
变量
函数
技术动态
基础知识库
首页
/
Python爬取数据
抓取网络源码python_使用Python进行网络抓取的新手指南
抓取网络源码python 有很多很棒的书可以帮助您学习Python,但是谁真正读了这些A到Z? (剧透:不是我)。 python爬取网络数据、 接下来是我的第一个Python抓取项目指南。 假定的Python和HTML知识很少。 这旨在说明如何使用Python库请求访问网
时间:2023-09-18 | 阅读:20
Python爬虫_数据存储
文章目录HTML正文抽取多媒体文件抽取Email提醒 HTML正文抽取 HTML正文存储主要分为两种格式:JSON和CSV 储存为JSON 需求:抽取小说标题、章节、章节名称和链接 爬虫python?首先使用Requests访问http://seputu.com/,获取HTML文档内容,并打印文档内
时间:2023-09-10 | 阅读:24
python爬取appstore的评论数据的步骤_python数据抓取分析
{"moduleinfo":{"card_count":[{"count_phone":1,"count":1}],"search_count":[{"count_phone":4,"count":4}]},"card":[{"des":"阿里技术人对外发布原创技术内容的最大平台;社区覆盖了云
时间:2023-09-09 | 阅读:29
用Python把github上非常实用的数据全部抓取下来! 留给自己备用
这是我根据这个流程实现的代码,网址:LiuRoy/github_spider Python爬取数据, 运行结果 因为每个请求延时很高,爬虫运行效率很慢,访问了几千个请求之后拿到了部分数据,这是按照查看数降序排列的python项目: 这是按粉丝数降序排列的
时间:2023-09-09 | 阅读:22
python爬取2019年计算机就业_2019年最新Python爬取腾讯招聘网信息代码解析
原标题:2019年最新Python爬取腾讯招聘网信息代码解析前言Python爬取数据。初学Python的小伙们在入门的时候感觉这门语言有很大的难度,但是他的用处是非常广泛的,在这里将通过实例代码讲解如何通过Python语言实现对于腾讯招聘网站信息的抓取废话不多说,各
时间:2023-09-08 | 阅读:29
python如何处理spark上的数据_Pyspark获取并处理RDD数据代码实例
弹性分布式数据集(RDD)是一组不可变的JVM对象的分布集,可以用于执行高速运算,它是Apache Spark的核心。在pyspark中获取和处理RDD数据集的方法如下:python调用shell、1. 首先是导入库和环境配置(本测试在linux的pycharm上完成)import osfrom pyspark imp
时间:2023-09-07 | 阅读:23
阅读排行
2753℃
1
如何防止应用程序泄密?
2748℃
2
AlertDialog禁止返回键
2567℃
3
linux中MySQL密码的恢复方...
2504℃
4
node.js当中net模块的简单...
2255℃
5
我的高质量软件发布心得
2186℃
6
从源码角度看Spark on yar...
2036℃
7
在linux云服务器上运行Jar...
1612℃
8
codevs1521 华丽的吊灯
猜你喜欢
float浮点数的四舍五入
OO模式-Composite
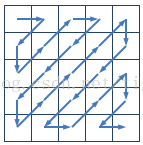
对于下面的4×4的矩阵,
1 5 3 9
CCF201412-2 Z字形扫描(解法二)(100分)
2015 年出现的十大流行 Python 库
BZOJ 3038: 上帝造题的七分钟2【线段树区间开方问题】
网络电话全民亲情祝福 中秋团圆新方式
ELK学习总结(2-2)单模式CRUD操作
[置顶]别羡慕别人的舒服,静下心来坚持奋斗!!!
关于在大网段中拆出小网段地址
玩转iOS开发:iOS 10 新特性《Thread Sanitizer》
《vSphere性能设计:性能密集场景下CPU、内存、存储及网络的最佳设计实践》一3.2.2 建立实验室...
使用IPMI工具实现对服务器的远程管理
热门标签
python3
Spring boot
python有什么用
python和java
java
Springboot教程
python编程
Leetcode
python爬蟲教程
python菜鳥教程
Springboot注解
Mybatis
Springboot框架
Springboot
UNIXLINUX
SpringBootApplication
python为什么叫爬虫
qpython
我要关灯
我要开灯
客户电话
工作时间:8:00-18:00
客服电话
电子邮件
admin@qq.com
官方微信
扫码二维码
获取最新动态
返回顶部













![[置顶]别羡慕别人的舒服,静下心来坚持奋斗!!!](/upload/rand_pic/2-119.jpg)



