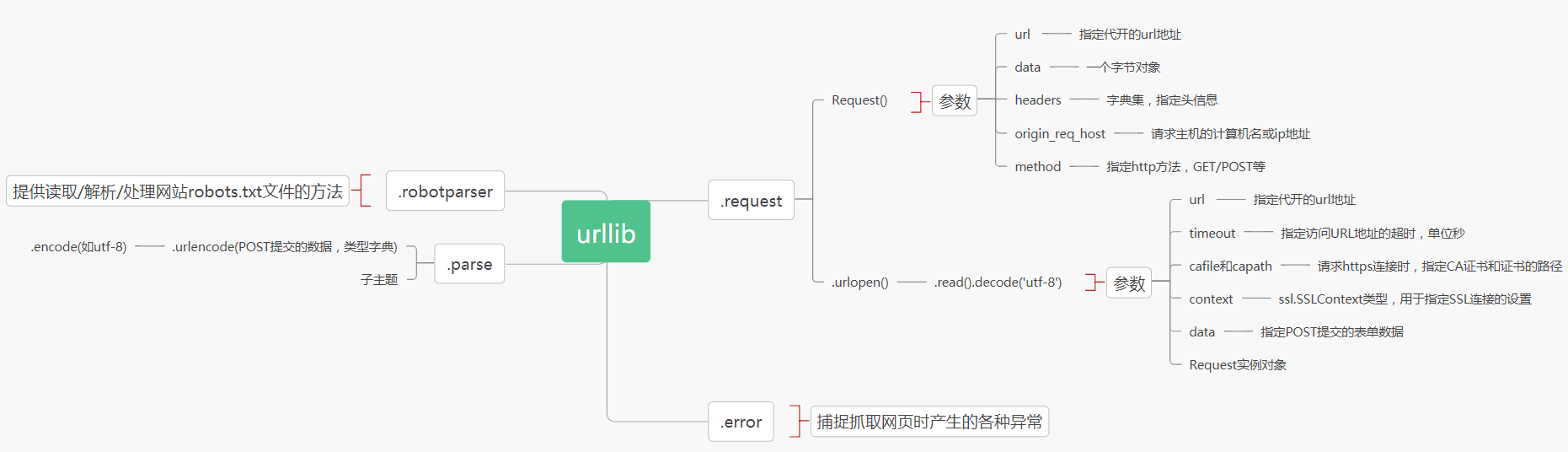
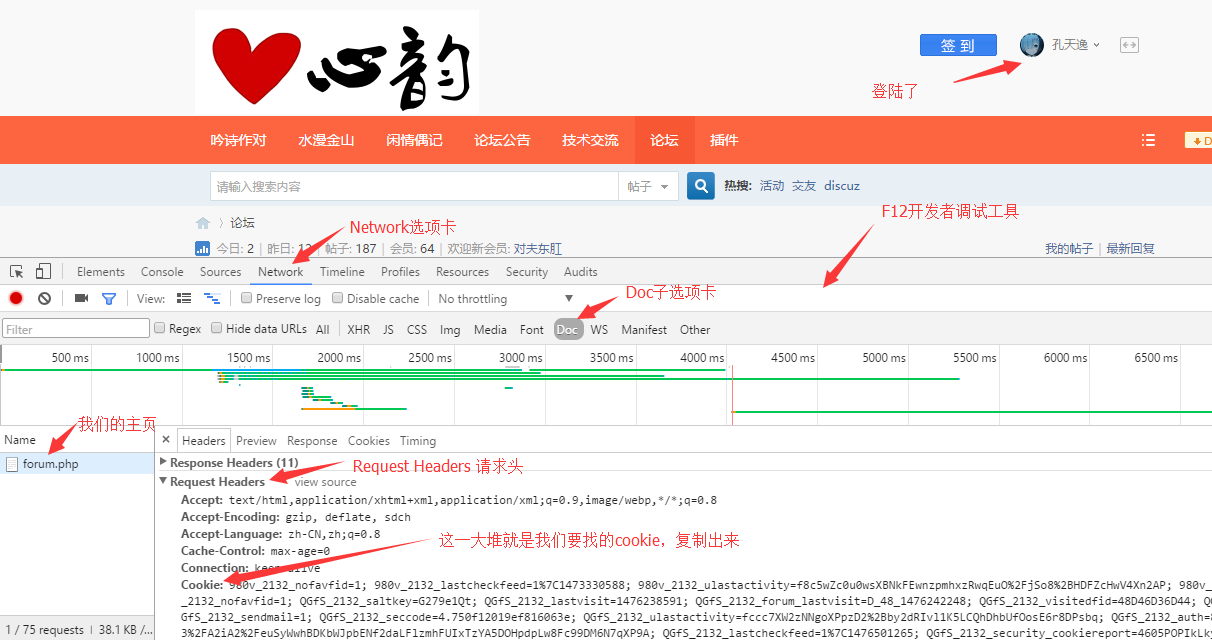
在scrapy中,設置cookie需要是字典格式的,可是我們從瀏覽器Copy出來的是字符串格式的,所以我們需要寫個小程序來轉化一下
transCookie.py
配置如下
工作时间:8:00-18:00
客服电话
电子邮件
admin@qq.com
扫码二维码
获取最新动态