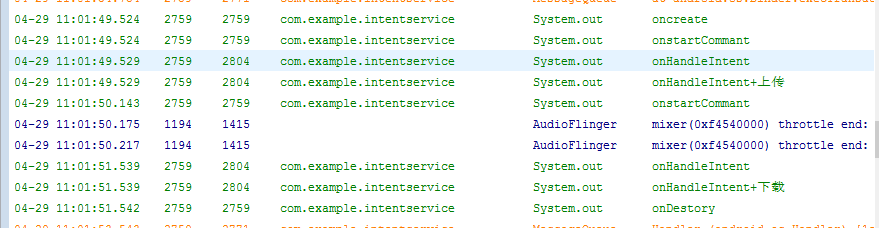
一,IntentService是Service的子类,比普通的Service增加了额外的功能。先看Service本身存在两个问题: Service不会专门启动一条单独的进程,Service与它所在应用位" alt="IntentService的使用介绍">
工作时间:8:00-18:00
客服电话
电子邮件
admin@qq.com
扫码二维码
获取最新动态