首页
语法
变量
函数
技术动态
基础知识库
首页
/
hdfs数据存储
gaussdb数据库,GaussDB(for MySQL)如何在存储架构设计上做到高可靠、高可用
摘要:GaussDB(for MySQL)通过ND算子下推解决存储节点和计算节点之间的传输速度,减少网络开销这个难题。 数据库作为高效稳定处理海量数据交易/分析的坚强数据底座,底层架构设计的重要性不言而喻。 以当前主流的存算分离架构为例,如何提高存储节点
时间:2023-09-22 | 阅读:22
用nifi把hdfs数据导到hive
全景图: 1. ListHDFS & FetchHDFS: ListHDFS: FetchHDFS: 2. EvaluateJsonPath: {"status": {"code":500,"message":"FAILED","detail":"DTU ID not exists"}} 如果json里有数组,需要先用SplitJson分
时间:2023-09-16 | 阅读:27
大数据-HDFS文件系统是什么
导语 Hadoop中附带了一个HDFS(Hadoop分布式文件系统)的分布式文件系统,专门用来存储超级大文件使用,它为整个的Hadoop应用生态圈提供了基础的文件存储功能。 文档目录HDFS 特点不适用HDFS的场景HDFS体系结构HDFS数据块复制HDFS读取和写入流程
时间:2023-09-15 | 阅读:17
hdfs配置解析
2014/9/8hadoop 记录 第一天: 一:节点的划分:hdfs数据存储,对于HDFS来讲,将整个集群中的节点,依据它们运行的进程,划分为三种:名字节点:namenode数据节点:datanode第二名字节点:seconderynamenod
时间:2023-09-13 | 阅读:20
flume 一对多hdfs_10PB 规模的 HDFS 数据在 eBay 的迁移实战
导读hdfs和hbase的区别。INTRODUCTIONHadoop分布式文件系统(HDFS)是指被设计成适合运行在通用硬件上的分布式文件系统(Distributed File System)。本文将介绍eBay ADI Hadoop team如何克服万难,在短短两小时内将近1000万级别文件数量与10PB规模大小的数据全部迁移至新
时间:2023-09-10 | 阅读:18
HDFS使用0
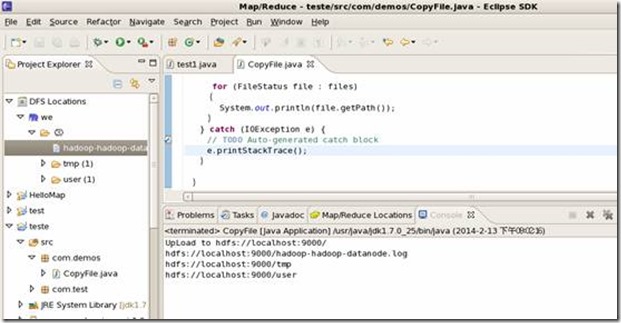
创建上传文件的: hdfs命令?转载于:https://www.cnblogs.com/greentomlee/p/3736045.html
时间:2023-09-09 | 阅读:23
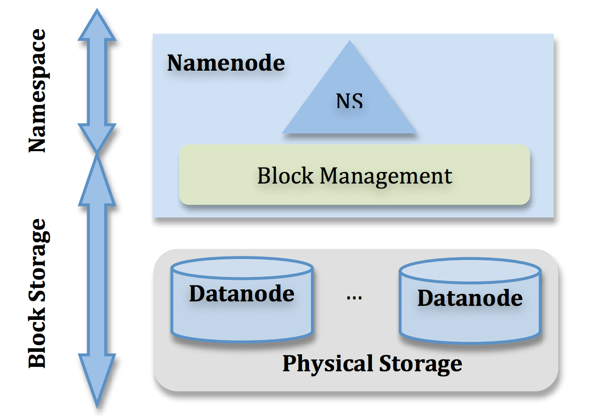
HDFS的NameNode内存解析
概述 从整个HDFS系统架构上看,NameNode是其中最重要、最复杂也是最容易出现问题的地方,而且一旦NameNode出现故障,整个Hadoop集群就将处于不可服务的状态,同时随着数据规模和集群规模地持续增长,很多小量级时被隐藏的问题逐渐暴露出来。所
时间:2023-09-06 | 阅读:19
Hadoop 系列之 HDFS
Hadoop 系列之 HDFS 花絮 上一篇文章Hadoop 系列之 1.0和2.0架构中,提到了 Google 的三驾马车,关于分布式存储,计算以及列式存储的论文,分别对应开源的 HDFS,Mapreduce以及 HBase。这里的 HDFS 是分布式文件系统,主要用于数据的存储。它的
时间:2023-09-06 | 阅读:21
Hive 老当益庄 | 深度解读 Flink 1.11:流批一体 Hive 数仓
精选30+云产品,助力企业轻松上云!>>> 首先恭喜 Table/SQL 的 blink planner 成为默认 Planner,撒花、撒花。 Flink 1.11 中流计算结合 Hive 批处理数仓,给离线数仓带来 Flink 流处理实时且 Exactly-once 的能力。另外,Flink
时间:2023-09-06 | 阅读:12
阅读排行
2752℃
1
如何防止应用程序泄密?
2747℃
2
AlertDialog禁止返回键
2566℃
3
linux中MySQL密码的恢复方...
2503℃
4
node.js当中net模块的简单...
2254℃
5
我的高质量软件发布心得
2185℃
6
从源码角度看Spark on yar...
2035℃
7
在linux云服务器上运行Jar...
1611℃
8
codevs1521 华丽的吊灯
猜你喜欢
关于我对于写博客写文章的理解
转载:【微信小程序】 wx:if 与 hidden(隐藏元素)区别
Selenium代码示例
今天与大家分享一下数人云对于SwarmKit的尝试和探索。Swarm早在2014年就出来了,和Docker Compose几乎是同一时期。Docker解决的是单机上容器的问题,但如何在一个集群一组的硬件资源上去调度容器?Swarm" alt="SwarmKit知多少——来自源码世界的深入解读">
SwarmKit知多少——来自源码世界的深入解读
元器件在线分销的探索之路
防止事件导致的oncreate的多次调用
应用场景不止于联接,新华三发布智能门户系统iPortal
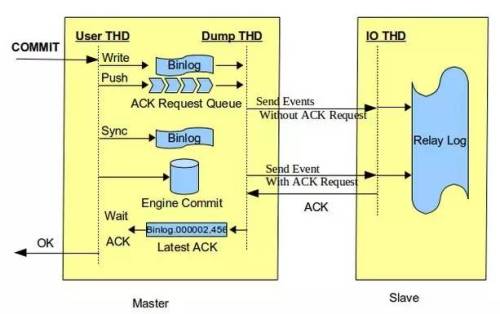
MySQL5.7 semi-sync replication功能增强
ArrayBlockingQueue与LinkedBlockingQueue
基于 Raphael 的 Web UI 设计 - 初稿
通过url传参实现多个页面使用同一个页面,再返回本页面
vue第一天
热门标签
python3
Spring boot
python有什么用
python和java
java
Springboot教程
python编程
Leetcode
python爬蟲教程
python菜鳥教程
Springboot注解
Mybatis
Springboot框架
Springboot
UNIXLINUX
SpringBootApplication
python为什么叫爬虫
qpython
我要关灯
我要开灯
客户电话
工作时间:8:00-18:00
客服电话
电子邮件
admin@qq.com
官方微信
扫码二维码
获取最新动态
返回顶部