首页
语法
变量
函数
技术动态
基础知识库
首页
/
知乎爬蟲爬不了了
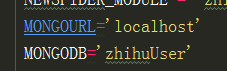
scrapy大型爬蟲,scrapy框架爬取知乎用戶
實現爬取一個大V的知乎用戶開始爬取開始,我選了輪子哥,然后通過爬取輪子哥的粉絲和他關注的用戶信息,再逐一對爬取到的用戶進行進一步地獲取粉絲和關注的用戶信息,這樣一直爬下去就能爬到很多很多用戶,相當于能夠把知乎所有的用戶都能
时间:2023-11-19 | 阅读:20
java可以寫爬蟲嗎,java 百度爬蟲_零基礎寫Java知乎爬蟲之先拿百度首頁練練手
上一集中我們說到需要用Java來制作一個知乎爬蟲,那么這一次,我們就來研究一下如何使用代碼獲取到網頁的內容。首先,沒有HTML和CSS和JS和AJAX經驗的建議先去W3C(點我點我)小小的了解一下。java可以寫爬蟲嗎、說到HTML,這里就涉及到一個GET訪問和PO
时间:2023-10-20 | 阅读:32
Python爬去知乎問題,python實戰1.0——爬取知乎某問題下的回復
python實戰1.0——爬取知乎某問題下的回復 確定問題爬取進行簡單篩選保存數據 # 獲取問題下的回復總數 def get_number():url = 'https://www.zhihu.com/question/397995405'kv = {'User-Agent': 'Mozilla/5.0'} # 模擬登錄r = requests.
时间:2023-10-06 | 阅读:24
阅读排行
2805℃
1
如何防止应用程序泄密?
2790℃
2
AlertDialog禁止返回键
2712℃
3
linux中MySQL密码的恢复方...
2550℃
4
node.js当中net模块的简单...
2295℃
5
我的高质量软件发布心得
2235℃
6
从源码角度看Spark on yar...
2076℃
7
在linux云服务器上运行Jar...
1767℃
8
codevs1521 华丽的吊灯
猜你喜欢
apache开源项目 -- tajo
Android热修复Tinker接入文档
Linux运维常见问题解决集锦【转】
通过url传参实现多个页面使用同一个页面,再返回本页面
Spring Bean的生命周期(非常详细)
hibernate中get方法和load方法的根本区别
ReSIProcate环境搭建
13-5 15 xshell使用xftp pure-ftpd
html5canvas简单画图
图解CentOS系统启动流程
Mysql慢查询操作梳理
Skype 释出新的 Linux 客户端
热门标签
python3
Spring boot
python有什么用
python和java
java
Springboot教程
python编程
Leetcode
python爬蟲教程
python菜鳥教程
Springboot注解
Mybatis
Springboot框架
Springboot
UNIXLINUX
SpringBootApplication
python为什么叫爬虫
qpython
我要关灯
我要开灯
客户电话
工作时间:8:00-18:00
客服电话
电子邮件
admin@qq.com
官方微信
扫码二维码
获取最新动态
返回顶部