首页
语法
变量
函数
技术动态
基础知识库
首页
/
Spark SQL
Scala安装,scala模板写入es_Spark——scala 实用小方法
Scala安装。这一阵刚刚接触scala,主要也是用在spark上~完全小白一个,看着Scala感觉与python很像,想着可能比较容易上手,结果……真是需要处理一个就得查一个啊,用python或Java很容易写出来的代码,用scala得查半天,晕死……为
时间:2023-09-23 | 阅读:15
Spark SQL,Apache CarbonData 2.0 开发实用系列之一:与Spark SQL集成使用
【摘要】 在Spark SQL中使用CarbonData 【准备CarbonData】 在浏览器地址栏输入以下链接,点击"download"按钮下载已经准备好的CarbonData jar包 链接:https://github.com/QiangCai/carbonjars/blob/master/master/apache-carbondata-2.1.0-SNAPSHOT-bin-spark2
时间:2023-09-22 | 阅读:16
docker自启动命令,Spark-submit执行流程,了解一下
摘要:本文主要是通过Spark代码走读来了解spark-submit的流程。 1.任务命令提交 我们在进行Spark任务提交时,会使用“spark-submit -class .....”样式的命令来提交任务,该命令为Spark目录下的shell脚本。它的作用是查询spark-home,调用spark-clas
时间:2023-09-22 | 阅读:14
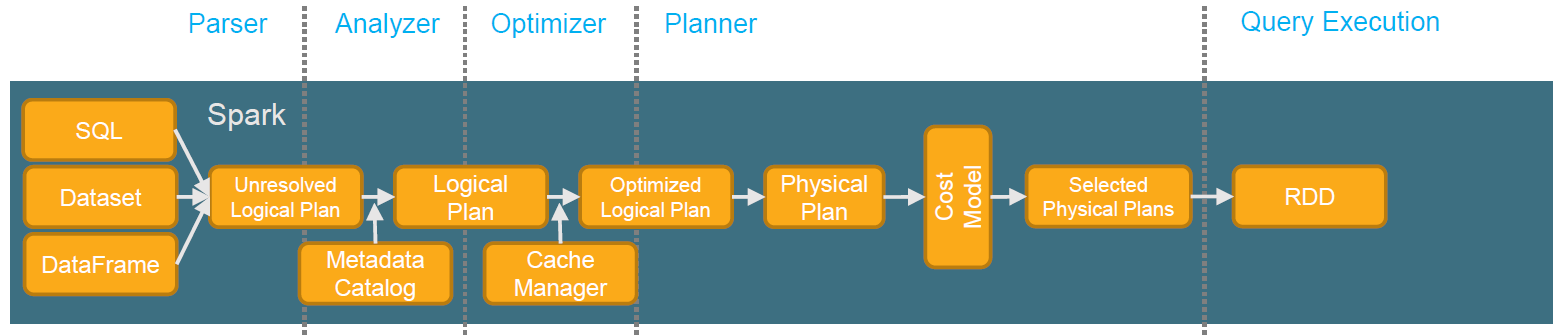
python heap,Spark 开源新特性:Catalyst 优化流程裁剪
摘要:为了解决过多依赖 Hive 的问题, SparkSQL 使用了一个新的 SQL 优化器替代 Hive 中的优化器, 这个优化器就是 Catalyst。 本文分享自华为云社区《Spark 开源新特性:Catalyst 优化流程裁剪》,作者:hzjturbo 。 1. 问题背景 上图是典型的Spark
时间:2023-09-22 | 阅读:19
关于spark
1、各个大大小小的Maillist、官方论坛 2、参考:http://spark.apache.org/community.html#events 目前在中国有4个meetup活动,分别在北京,杭州,上海和深圳,去http://meetup.com上报名参加即可,每次活动都会请到企业内部人员进行实践
时间:2023-09-19 | 阅读:15
spark代码连接hive_spark连接Hive
作者是通过metastore方式实现spark连接hive数据库,所以首先启动metastore:hive --service metastore另外需要将core-site.xml、hdfs-site.xml、hive-site.xml三个文件复制到的spark/conf文件夹下。image.pngpython socketserver?hive-site.cml中要包含metastore的地址
时间:2023-09-17 | 阅读:13
java 时间序列预测_基于spark的时间序列预测包Sparkts._的使用
最近研究了一下时间序列预测的使用,网上找了大部分的资源,都是使用python来实现的,使用python来实现虽然能满足大部分的需求,但是python有一点缺点按就是只能使用一台计算资源进行计算,如果数据量大的时候,就有可能不能胜任,
时间:2023-09-15 | 阅读:14
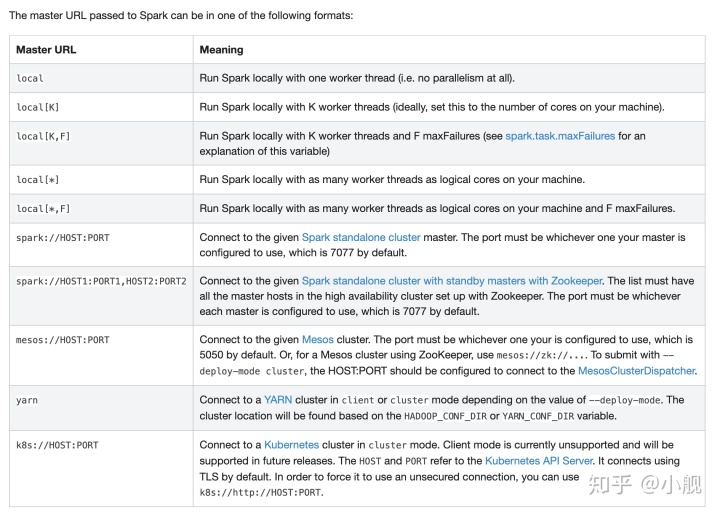
spark任务shell运行_Spark原理与实战之部署模式与运行机制
前言:Spark的运行模式指的是Spark应用程序以怎样的方式运行,单节本地点运行还是多节点集群运行,自己进行资源调度管理还是依靠别人进行调度管理。Spark提供了多种多样,灵活多变的部署模式。spark大型项目实战、一、部署模式这是spark官方给出的ma
时间:2023-09-15 | 阅读:20
spark mapWithState 实现
mapWithState()可以保存流的状态,并能做到当前rdd和前一段时间的rdd进行比较或者聚合。 当stream调用mapWithState()方法的时候,将会返回一个MapWithStateDStreamImpl。 @Experimental def mapWithState[StateType: ClassTag, MappedType: ClassTag](spec:
时间:2023-09-15 | 阅读:17
spark job生成的时间驱动
JobGenerator中有一个timer成员,根据配置中的时间间隔不断产生GenerateJobs事件来触发job的产生,以成为job产生的起点。Timer通过clock来作为构建时间的依据。oracle定时执行sql、 val clock = {val clockClass = ssc.sc.conf.get("spark.streaming
时间:2023-09-15 | 阅读:13
«
1
2
3
4
5
6
»
阅读排行
2715℃
1
如何防止应用程序泄密?
2714℃
2
AlertDialog禁止返回键
2531℃
3
linux中MySQL密码的恢复方...
2370℃
4
node.js当中net模块的简单...
2220℃
5
我的高质量软件发布心得
2153℃
6
从源码角度看Spark on yar...
2009℃
7
在linux云服务器上运行Jar...
1564℃
8
codevs1521 华丽的吊灯
猜你喜欢
Spring Session 2.0.0.M1 发布,分布式解决方案
学习进度条08
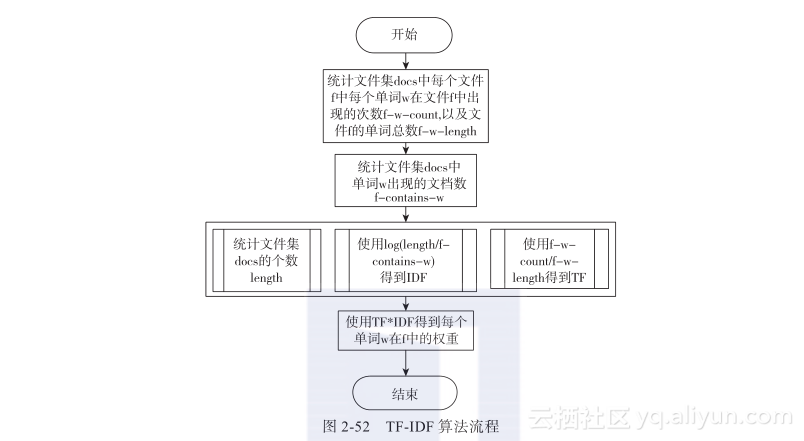
《Hadoop与大数据挖掘》——2.6 TF-IDF算法原理及Hadoop MapReduce实现
squid 出错页面GMT时间修改(FreeBSD)
npm 是干什么的?
jq的优缺点总结
JavaSE 学习参考:数组遍历
必备知识:大数据处理应遵循的原则
重庆市教育云服务平台基本建成
树上倍增求LCA及例题
华为RSPAN
node.js当中net模块的简单应用(基于控制台的点对点通信)
热门标签
python3
Spring boot
python有什么用
python和java
java
Springboot教程
python编程
Leetcode
python爬蟲教程
python菜鳥教程
Springboot注解
Mybatis
Springboot框架
Springboot
UNIXLINUX
SpringBootApplication
python为什么叫爬虫
qpython
我要关灯
我要开灯
客户电话
工作时间:8:00-18:00
客服电话
电子邮件
admin@qq.com
官方微信
扫码二维码
获取最新动态
返回顶部