Spark在集群上執行代碼案例java的切詞使用案例(Demo)Spark中文切詞代碼需求:利用jieba進行中文分詞,并打包上傳到集群進行執行 java的切詞使用案例(Demo) @Test
public void testDemo() {JiebaSegmenter segmenter = new
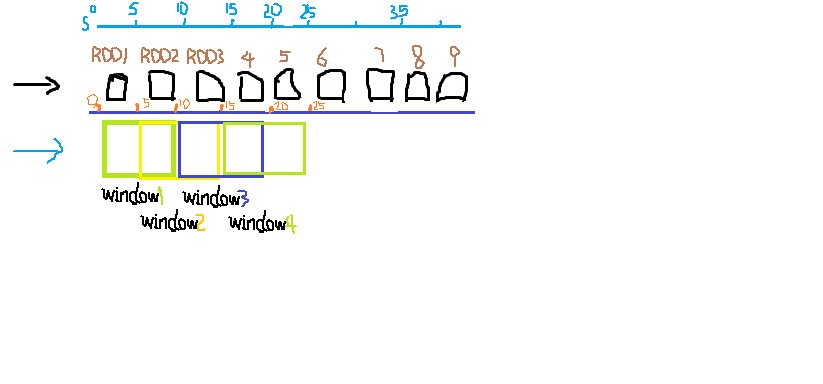
collectAsMap(): Map[K, V] 返回key-value對,key是唯一的,如果rdd元素中同一個key對應多個value,則只會保留一個。/** * Return the key-value pairs in this RDD to the master as a Map. * * Warning: this doesn't return a multimap (so if you