首页
语法
变量
函数
技术动态
基础知识库
首页
/
大数据分析hadoop
不小心退出云班课还有数据吗,云小课 | 大数据融合分析:GaussDW(DWS)轻松导入MRS-Hive数据源
摘要:通过建立GaussDB(DWS)与MRS的连接,支持数据仓库服务SQL on Hadoop,以外表方式实现Hive数据的快捷导入,满足大数据融合分析的应用场景。 本文分享自华为云社区《【云小课】EI第17课 大数据融合分析:GaussDB(DWS)轻松导入MRS-Hive数据源
时间:2023-09-22 | 阅读:13
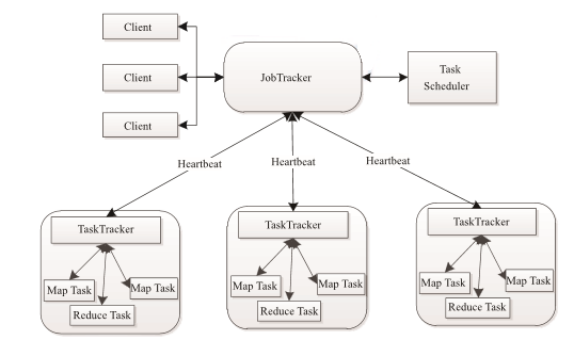
大数据开发 | MapReduce介绍
1. MapReduce 介绍1.1MapReduce的作用 假设有一个计算文件中单词个数的需求,文件比较多也比较大,在单击运行的时候机器的内存受限,磁盘受限,运算能力受限,而一旦将单机版程序扩展到集群来分布式运行,将极大增加程序的复杂度和开发难
时间:2023-09-15 | 阅读:16
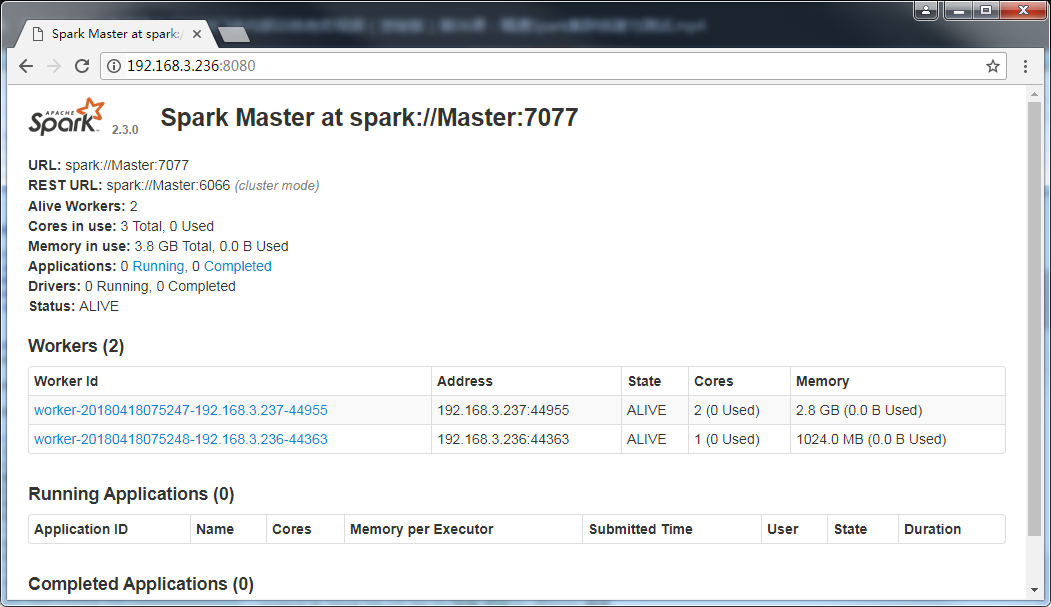
大数据-03-Spark入门
Spark 简介 行业广泛使用Hadoop来分析他们的数据集。原因是Hadoop框架基于一个简单的编程模型(MapReduce)。这里,主要关注的是在处理大型数据集时在查询之间的等待时间和运行程序的等待时间方面保持速度。 Hadoop只是实现Spark的方法之一。Spark以两种方
时间:2023-09-15 | 阅读:13
rdd分片 spark_大数据面试题(Spark(一))
大数据面试题(Spark(一))大家好,我是蓦然,这一系列大数据面试题是我秋招时自己总结准备的,后续我会总结出PDF版,希望对大家有帮助!1、spark的有几种部署模式,每种模式特点?(☆☆☆☆☆)1)本地模式Spark不一定非要跑在hadoo
时间:2023-09-07 | 阅读:13
大数据自学——Spark
Spark自学之路 Spark基础——思维导图 #1.1Spark是什么 Apache Spark 是一个快速的,多用途的计算系统,相对于Hadoop MapReduce将中间结果保存在磁盘中,Spark使用了内存保存中间结果,能在数据尚未写入硬盘时在内存中进行运算。Spark只是一个计算框
时间:2023-09-06 | 阅读:22
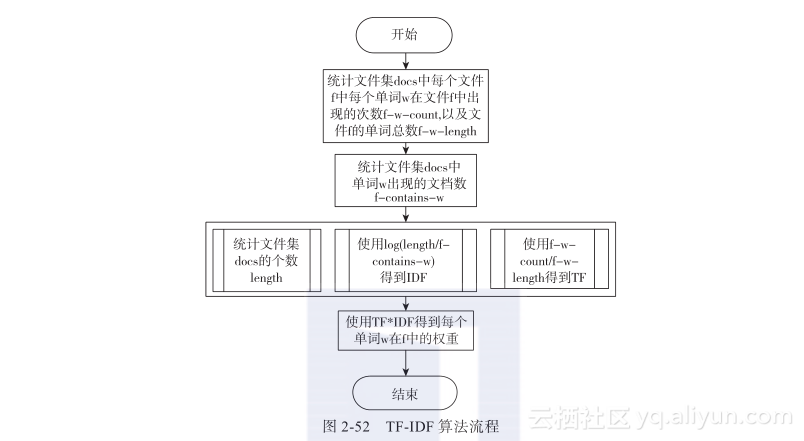
《Hadoop与大数据挖掘》——2.6 TF-IDF算法原理及Hadoop MapReduce实现
本节书摘来自华章计算机《Hadoop与大数据挖掘》一书中的第2章,第2.6节,作者 张良均 樊哲 位文超 刘名军 许国杰 周龙 焦正升,更多章节内容可以访问云栖社区“华章计算机”公众号查看。 2.6 TF-IDF算法原理及Hadoop MapReduce实现 2.6.1 TF-IDF算法原理
时间:2023-09-05 | 阅读:355
阅读排行
2683℃
1
如何防止应用程序泄密?
2497℃
2
linux中MySQL密码的恢复方...
2477℃
3
AlertDialog禁止返回键
2331℃
4
node.js当中net模块的简单...
2185℃
5
我的高质量软件发布心得
2115℃
6
从源码角度看Spark on yar...
1973℃
7
在linux云服务器上运行Jar...
1518℃
8
codevs1521 华丽的吊灯
猜你喜欢
网页统计所用到的名词解析
SQL Tuning Advisor使用实例
Wannafly模拟赛2
CSS魔法堂:选择器及其优先级
solr hdfs solr.in.sh
Firefox 用户加载的半数网页启用了 HTTPS
.net发送邮件outlook中文乱码
请给出linux中查看系统已经登录用户的命令?
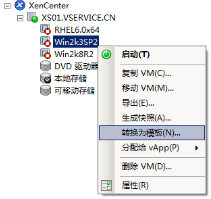
九、Citrix服务器虚拟化Xenserver虚拟机模版
grep、sed命令使用记录
070——VUE中vuex之使用getters计算每一件购物车中商品的总价
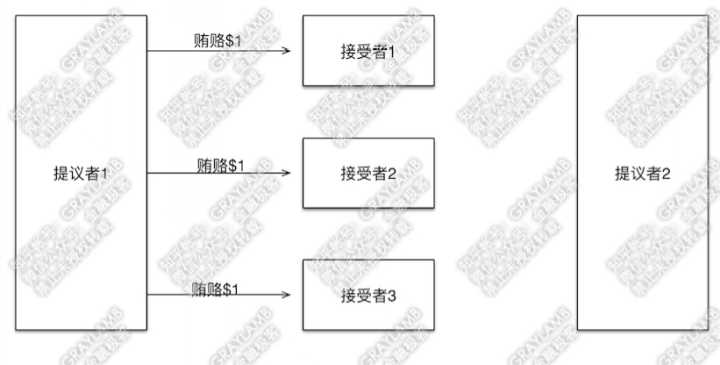
分布式系统一致性协议--Paxos算法
热门标签
python3
Spring boot
python有什么用
python和java
java
Springboot教程
python编程
Leetcode
python爬蟲教程
python菜鳥教程
Springboot注解
Mybatis
Springboot框架
Springboot
UNIXLINUX
SpringBootApplication
python为什么叫爬虫
qpython
我要关灯
我要开灯
客户电话
工作时间:8:00-18:00
客服电话
电子邮件
admin@qq.com
官方微信
扫码二维码
获取最新动态
返回顶部