首页
语法
变量
函数
技术动态
基础知识库
首页
/
java大数据
大数据开发 | MapReduce介绍
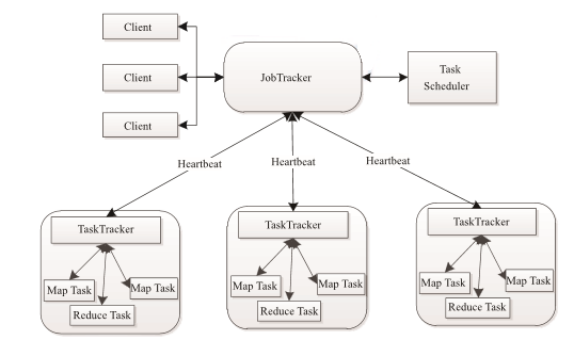
1. MapReduce 介绍1.1MapReduce的作用 假设有一个计算文件中单词个数的需求,文件比较多也比较大,在单击运行的时候机器的内存受限,磁盘受限,运算能力受限,而一旦将单机版程序扩展到集群来分布式运行,将极大增加程序的复杂度和开发难
时间:2023-09-15 | 阅读:16
大数据开发:剖析Hadoop和Spark的Shuffle过程差异
一、前言 对于基于MapReduce编程范式的分布式计算来说,本质上而言,就是在计算数据的交、并、差、聚合、排序等过程。而分布式计算分而治之的思想,让每个节点只计算部分数据,也就是只处理一个分片,那么要想求得某个key对应的全量数据
时间:2023-09-13 | 阅读:19
《Hadoop与大数据挖掘》——2.6 TF-IDF算法原理及Hadoop MapReduce实现
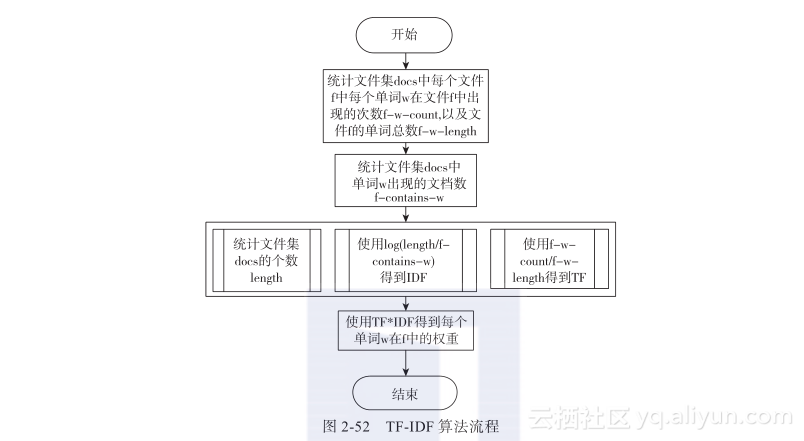
本节书摘来自华章计算机《Hadoop与大数据挖掘》一书中的第2章,第2.6节,作者 张良均 樊哲 位文超 刘名军 许国杰 周龙 焦正升,更多章节内容可以访问云栖社区“华章计算机”公众号查看。 2.6 TF-IDF算法原理及Hadoop MapReduce实现 2.6.1 TF-IDF算法原理
时间:2023-09-05 | 阅读:355
阅读排行
2683℃
1
如何防止应用程序泄密?
2497℃
2
linux中MySQL密码的恢复方...
2477℃
3
AlertDialog禁止返回键
2331℃
4
node.js当中net模块的简单...
2185℃
5
我的高质量软件发布心得
2115℃
6
从源码角度看Spark on yar...
1973℃
7
在linux云服务器上运行Jar...
1518℃
8
codevs1521 华丽的吊灯
猜你喜欢
重庆市教育云服务平台基本建成
前后端分离-从MVC到前后端分离
【个人重点】开发中应该重视的几点
认清当下的努力,可能毫无意义
调查显示超四成人“讨厌”大数据
CODEVS 3269 混合背包
用区块链保护共享数据?存储初创公司Gospel开始试水
redhat python3.4安装步骤
转自: http://blog.csdn.net/xiaxiaorui2003/article/details/3838631
SQL2005存储过程解密
jQuery Mobile中jQuery.mobile.changePage方法使用详解
codeforce 804B Minimum number of steps
热门标签
python3
Spring boot
python有什么用
python和java
java
Springboot教程
python编程
Leetcode
python爬蟲教程
python菜鳥教程
Springboot注解
Mybatis
Springboot框架
Springboot
UNIXLINUX
SpringBootApplication
python为什么叫爬虫
qpython
我要关灯
我要开灯
客户电话
工作时间:8:00-18:00
客服电话
电子邮件
admin@qq.com
官方微信
扫码二维码
获取最新动态
返回顶部