首页
语法
变量
函数
技术动态
基础知识库
首页
/
hadoop推荐算法
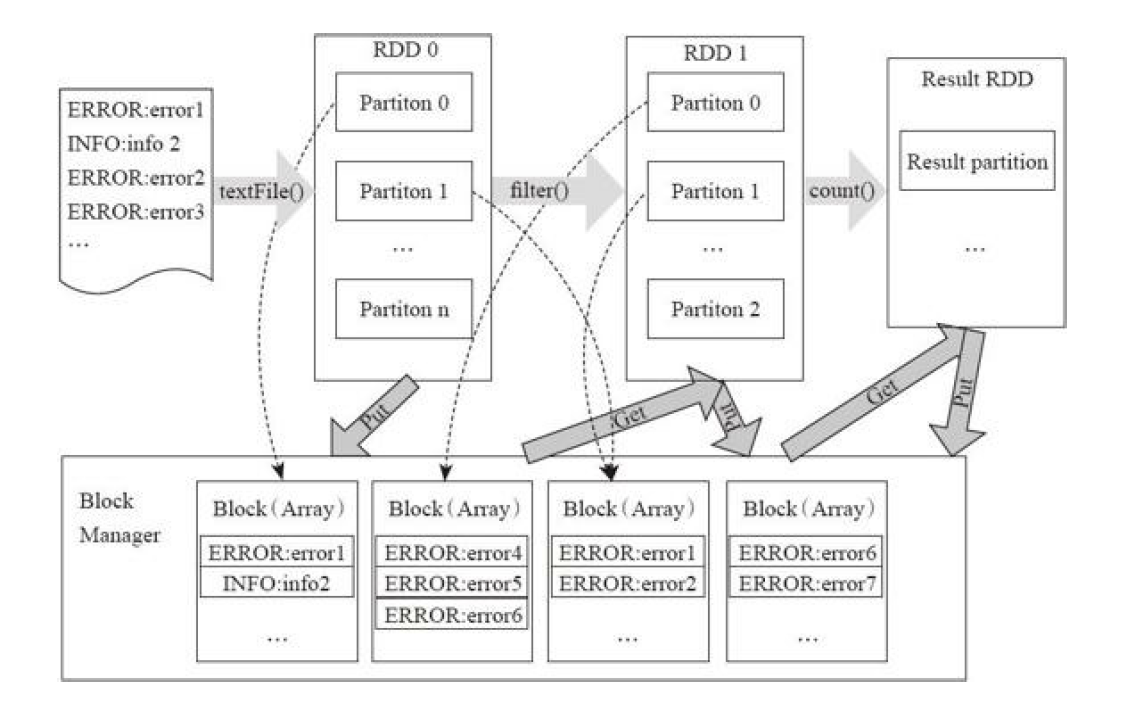
vsepr模型计算公式,Spark计算模型
通过一个经典的程序来说明 //输入与构造 RDD val file=sc.textFile("***") //转换Transformation val errors=file.filter(line=>line.contains("ERRORS")) //输出 Action error.count() 从RDD的转换和存储角度看这个过程: 用户程序对
时间:2023-09-28 | 阅读:24
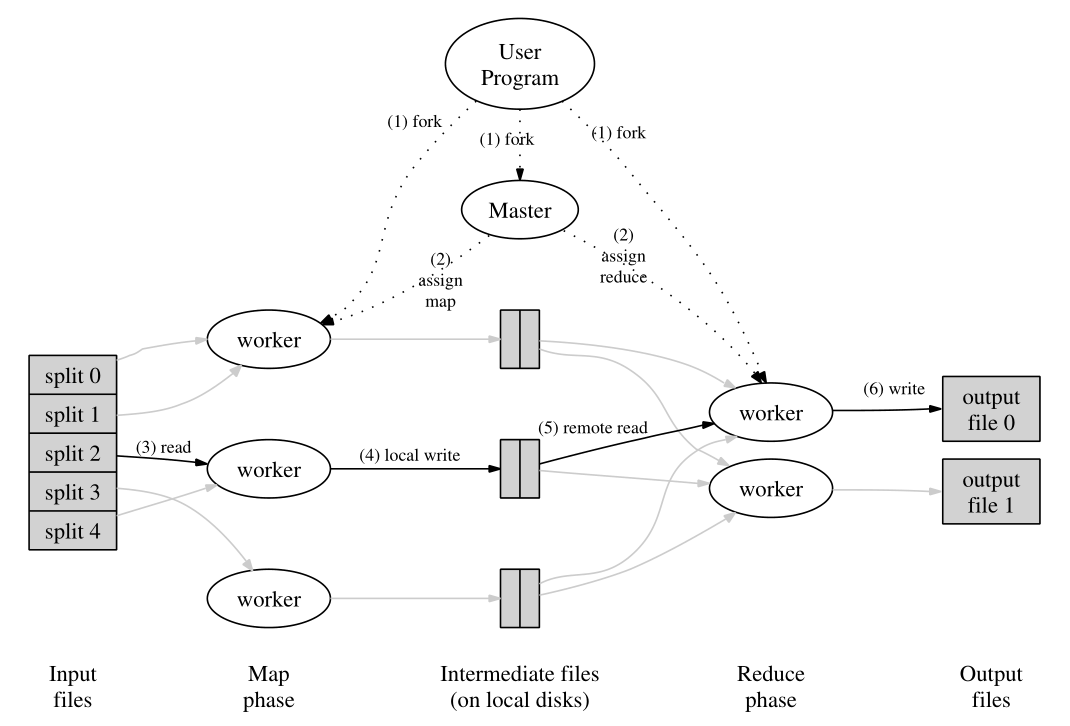
map保存数据怎么实现的,计算map代码_大数据系列之计算框架MapReduce
CDA数据分析师 出品1、 MapReduce计算框架简介map保存数据怎么实现的、Mapreduce 是hadoop项目中的分布式运算程序的编程框架,是用户开发"基于hadoop的数据分析应用"的核心框架,Mapreduce 程序本质上是并行运行的。分布式程序运行在大规模计算机集群上&
时间:2023-09-22 | 阅读:19
EMA算法的C#实现
EMA表示的是指数平滑移动平均,其函数的定义为Y=EMA(X,N) 则Y=[2*X+(N-1)*Y']/(N+1), 其中Y'表示上一周期Y值。 求X的N日指数平滑移动平均,它真正的公式表达是:当日指数平均值=平滑系数*(当日指数值-昨日指数平均值&#
时间:2023-09-16 | 阅读:14
Hadoop之MapReduce分布式计算
简单介绍一下项目背景——很简单,作死去接下老师的活,然后一干就是半个月,一直忙着从零基础到使用Hadoop中的MapReduce来解决一个实际问题,也就是用来计算一个数据量较大的二度朋友关系。 那么首先是我的上一篇博文:Hadoop之初体验 上一篇
时间:2023-09-15 | 阅读:16
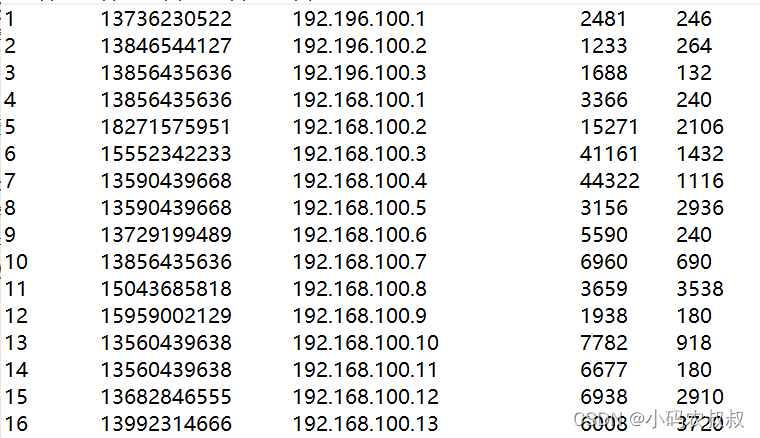
那么最终的效果可按如下格式输出
hadoop 实现序列化
前言 序列化想必大家都很熟悉了,对象在进行网络传输过程中,需要序列化之后才能传输到客户端,或者客户端的数据序列化之后送达到服务端 序列化的标准解释如下: hadoop启动hdfs命令。序列化就是把内存中的对象,转换成字节序列(或其他
时间:2023-09-15 | 阅读:14
期望输出数据的格式如:
hadoop 实现数据排序
前言 在很多业务场景下,需要对原始的数据读取分析后,将输出的结果按照指定的业务字段进行排序输出,方便上层应用对结果数据进行展示或使用,减少二次排序的成本 在hadoop的MapReduce中,提供了对于客户端的自定义排序的功能相关API MapReduc
时间:2023-09-15 | 阅读:20
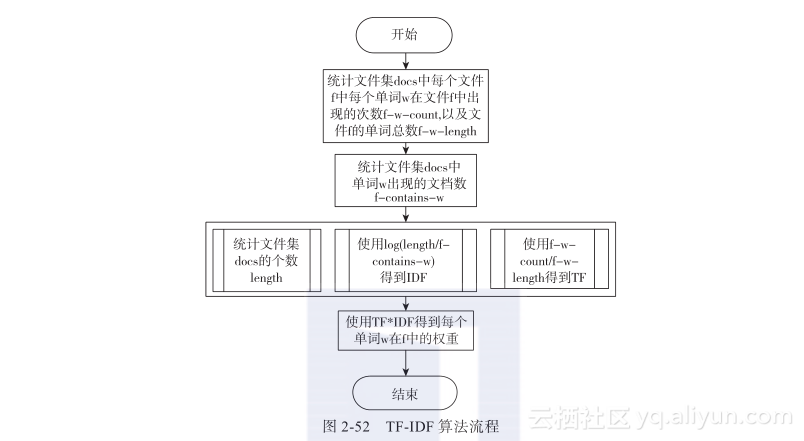
《Hadoop与大数据挖掘》——2.6 TF-IDF算法原理及Hadoop MapReduce实现
本节书摘来自华章计算机《Hadoop与大数据挖掘》一书中的第2章,第2.6节,作者 张良均 樊哲 位文超 刘名军 许国杰 周龙 焦正升,更多章节内容可以访问云栖社区“华章计算机”公众号查看。 2.6 TF-IDF算法原理及Hadoop MapReduce实现 2.6.1 TF-IDF算法原理
时间:2023-09-05 | 阅读:355
阅读排行
2684℃
1
如何防止应用程序泄密?
2498℃
2
linux中MySQL密码的恢复方...
2478℃
3
AlertDialog禁止返回键
2334℃
4
node.js当中net模块的简单...
2186℃
5
我的高质量软件发布心得
2116℃
6
从源码角度看Spark on yar...
1974℃
7
在linux云服务器上运行Jar...
1520℃
8
codevs1521 华丽的吊灯
猜你喜欢
选择云服务器的小窍门
相框
时评:别让智能设备成为网络安全的“蚁穴”
ipvs,ipvsadm的安装及使用
整理Excel表格中的批注
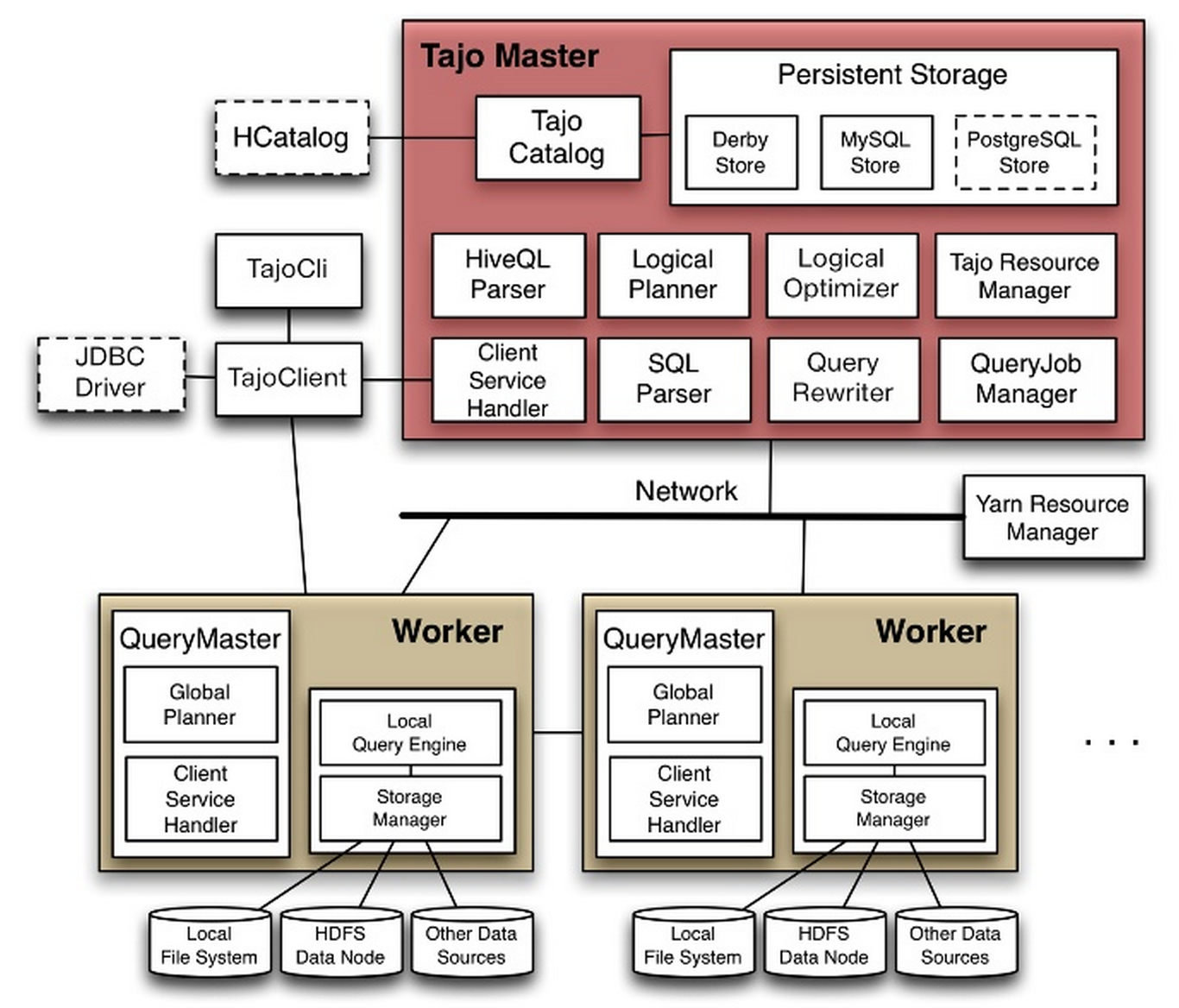
apache开源项目 -- tajo
Windows Server 2008 R2 域控DOS命令
layabox2:打地鼠(地鼠显示/停留/受击/消失)
centos下安装fastdfs(笔记系列)
政企多样化发力 社区半径引领智慧社区生态建设
Mysql慢查询操作梳理
LeetCode之Binary Tree Level Order Traversal 层序遍历二叉树
热门标签
python3
Spring boot
python有什么用
python和java
java
Springboot教程
python编程
Leetcode
python爬蟲教程
python菜鳥教程
Springboot注解
Mybatis
Springboot框架
Springboot
UNIXLINUX
SpringBootApplication
python为什么叫爬虫
qpython
我要关灯
我要开灯
客户电话
工作时间:8:00-18:00
客服电话
电子邮件
admin@qq.com
官方微信
扫码二维码
获取最新动态
返回顶部