首页
语法
变量
函数
技术动态
基础知识库
首页
/
js爬虫框架
Golang实现简单爬虫框架(5)——项目重构与数据存储
前言 在上一篇文章《Golang实现简单爬虫框架(4)——队列实现并发任务调度》中,我们使用用队列实现了任务调度,接下来首先对两种并发方式做一个同构,使代码统一。然后添加数据存储模块。 注意:本次并发是在上一篇文章简单并发实现的
时间:2023-09-13 | 阅读:26
开源通用爬虫框架YayCrawler-页面的抽取规则定义
本节我将向大家介绍一下YayCrawler的核心-页面的抽取规则定义,这也是YayCrawler能够做到通用的主要原因之一。如果我要爬去不同的网站的数据,尽管他们的网站采用的开发技术不同、页面的结构不同,但是我只要针对不同的网站定义不同的抽取规则即可,
时间:2023-09-10 | 阅读:25
Scrapy框架实现爬虫
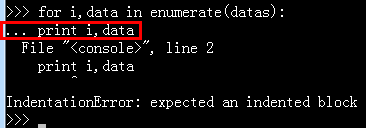
实战中的遇到的问题总结: 1. 解决方法: py好用的爬虫框架、只需要在print前面加tab键就可以了,即:后面需要缩进。 2.在win7下运行response.xpath报错的解决方法 python爬虫功能、 解决方法: 将‘’单引号改成双引号“” scrapy框架运行流
时间:2023-09-10 | 阅读:24
小白学 Python 爬虫:自动化测试框架 Selenium 从入门到实战
引言 前面连续几篇爬虫实战不知道各位同学玩的怎么样,小编是要继续更新了,本篇我们来介绍一个前面已将安装过的工具:Selenium ,如果说是叫爬虫工具其实并不合适,在业界很多时候是拿来做自动化测试的,所以本篇的标题也就叫成了自动化
时间:2023-09-06 | 阅读:22
Python爬虫-- Scrapy框架
Scrapy框架 Scrapy使用了Twisted作为框架,Twisted有些特殊的地方是它是事件驱动的,并且比较适合异步的代码。对于会阻塞线程的操作包含访问文件、数据库或者Web、产生新的进程并需要处理新进程的输出(如运行shell命令)、执行系统层次操作的代码(如等待系统队列)
时间:2023-09-05 | 阅读:414
阅读排行
2748℃
1
如何防止应用程序泄密?
2742℃
2
AlertDialog禁止返回键
2562℃
3
linux中MySQL密码的恢复方...
2498℃
4
node.js当中net模块的简单...
2250℃
5
我的高质量软件发布心得
2181℃
6
从源码角度看Spark on yar...
2030℃
7
在linux云服务器上运行Jar...
1604℃
8
codevs1521 华丽的吊灯
猜你喜欢
多线程-ThreadLocal,InheritableThreadLocal
初学者指南:服务器基本技术名词
利用iTextSharp填写中文(中日韩)PDF表单(完整解决方案)
基于jquery类库的绘制二维码的插件jquery.qrcode.js
Tensorflow 相关概念
以色列网络安全初创企业Cronus获350万美元A轮融资
NPOI操作word文档
零基础:邪恶带你3步快速掌握iSCSI搭建
备份事务日志时遇到 log corruption
FPGA学习(第8节)-Verilog设计电路的时序要点及时序仿真
一步步创建第一个Docker App —— 4. 部署应用
2016物联网大趋势搞不懂?别担心,CES为你指点迷津
热门标签
python3
Spring boot
python有什么用
python和java
java
Springboot教程
python编程
Leetcode
python爬蟲教程
python菜鳥教程
Springboot注解
Mybatis
Springboot框架
Springboot
UNIXLINUX
SpringBootApplication
python为什么叫爬虫
qpython
我要关灯
我要开灯
客户电话
工作时间:8:00-18:00
客服电话
电子邮件
admin@qq.com
官方微信
扫码二维码
获取最新动态
返回顶部