首页
语法
变量
函数
技术动态
基础知识库
首页
/
爬虫框架对比
python网络爬虫教程,python爬虫程序框架的理论是什么_Python网络爬虫(scrapy框架简介和基础应用)
一、什么是Scrapy?Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架,非常出名,非常强悍。所谓的框架就是一个已经被集成了各种功能(高性能异步下载,队列,分布式,解析,持久化等)的具有很强通用性的项目模
时间:2023-09-23 | 阅读:22
爬虫、网页测试 及 java servlet 测试框架等介绍
scrapy 抓取网页并存入 mongodb的完整示例: java爬虫和python爬虫?https://github.com/rmax/scrapy-redis https://github.com/geekan/scrapy-examples #Multifarious(多样的) Scrapy examples. https://github.com/DormyMo/scrappy # scrapy best
时间:2023-09-16 | 阅读:27
开源通用爬虫框架YayCrawler-页面的抽取规则定义
本节我将向大家介绍一下YayCrawler的核心-页面的抽取规则定义,这也是YayCrawler能够做到通用的主要原因之一。如果我要爬去不同的网站的数据,尽管他们的网站采用的开发技术不同、页面的结构不同,但是我只要针对不同的网站定义不同的抽取规则即可,
时间:2023-09-10 | 阅读:25
Scrapy框架实现爬虫
实战中的遇到的问题总结: 1. 解决方法: py好用的爬虫框架、只需要在print前面加tab键就可以了,即:后面需要缩进。 2.在win7下运行response.xpath报错的解决方法 python爬虫功能、 解决方法: 将‘’单引号改成双引号“” scrapy框架运行流
时间:2023-09-10 | 阅读:24
java mongodb 返回所有field_Python爬虫框架:scrapy爬取知乎关注用户存入mongodb
环境需求基础环境沿用之前的环境,只是增加了MongoDB(非关系型数据库)和PyMongo(Python 的 MongoDB 连接库),默认我认为大家都已经安装好并启动 了MongoDB 服务。java连接mongodb数据库?测试爬虫效果我这里先写一个简单的爬虫,爬取用户的关注人数和粉丝数
时间:2023-09-09 | 阅读:18
Scrapy网络爬虫框架实际案例讲解,Python爬虫原来如此简单!
创建项目 Scrapy爬虫框架提供一个工具来创建项目,生成的项目中预置了一些文件,用户需要在这些文件中添加python代码。最后,如果你的时间不是很紧张,并且又想快速的提高,最重要的是不怕吃苦,建议你可以联系维:762459510 &#x
时间:2023-09-09 | 阅读:21
小白学 Python 爬虫:自动化测试框架 Selenium 从入门到实战
引言 前面连续几篇爬虫实战不知道各位同学玩的怎么样,小编是要继续更新了,本篇我们来介绍一个前面已将安装过的工具:Selenium ,如果说是叫爬虫工具其实并不合适,在业界很多时候是拿来做自动化测试的,所以本篇的标题也就叫成了自动化
时间:2023-09-06 | 阅读:22
Python爬虫Scrapy框架IP代理的配置与调试
在调试爬虫的时候,新手都会遇到关于ip的错误,好好的程序突然报错了,怎么解决,关于ip访问的错误其实很好解决,但是怎么知道解决好了呢?怎么确定是代理ip的问题呢?由于笔者主修语言是Java,所以有些解释可能和Python大佬
时间:2023-09-06 | 阅读:24
【Python爬虫】Scrapy爬虫框架
Scrapy爬虫框架介绍 pip install scrapyscrapy -h 更好地理解原理: Scrapy爬虫框架解析 requests库和Scarpy爬虫的比较 Scrapy爬虫的常用命令 scrapy -h
时间:2023-09-06 | 阅读:29
Python爬虫-- Scrapy框架
Scrapy框架 Scrapy使用了Twisted作为框架,Twisted有些特殊的地方是它是事件驱动的,并且比较适合异步的代码。对于会阻塞线程的操作包含访问文件、数据库或者Web、产生新的进程并需要处理新进程的输出(如运行shell命令)、执行系统层次操作的代码(如等待系统队列)
时间:2023-09-05 | 阅读:414
阅读排行
2749℃
1
如何防止应用程序泄密?
2743℃
2
AlertDialog禁止返回键
2563℃
3
linux中MySQL密码的恢复方...
2499℃
4
node.js当中net模块的简单...
2251℃
5
我的高质量软件发布心得
2182℃
6
从源码角度看Spark on yar...
2031℃
7
在linux云服务器上运行Jar...
1605℃
8
codevs1521 华丽的吊灯
猜你喜欢
如何从rpm包中提取文件
SQL存储过程和函数
Android开发(1):随机绘制彩色实心圆
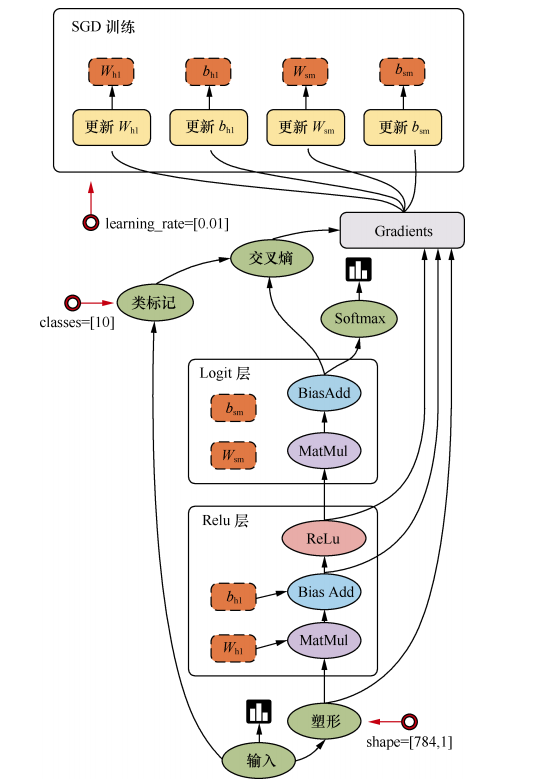
Tensorflow 相关概念
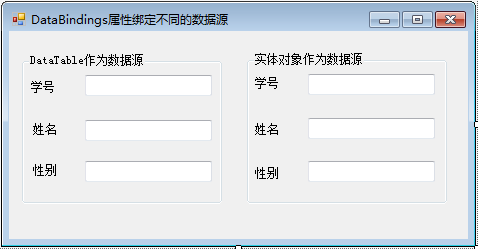
TextBox控件的DataBindings属性
java类成员方法(成员函数)的初步介绍
CODEVS 3269 混合背包
洛谷——P1164 小A点菜
javascript--DOM概念
2017年国内开源镜像站点汇总
关于docker部署javaweb应用的问题
Request 部分功能
热门标签
python3
Spring boot
python有什么用
python和java
java
Springboot教程
python编程
Leetcode
python爬蟲教程
python菜鳥教程
Springboot注解
Mybatis
Springboot框架
Springboot
UNIXLINUX
SpringBootApplication
python为什么叫爬虫
qpython
我要关灯
我要开灯
客户电话
工作时间:8:00-18:00
客服电话
电子邮件
admin@qq.com
官方微信
扫码二维码
获取最新动态
返回顶部