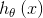相对于开发人员(也要写测试代码),测试开发人员在测试方面" alt="潘在亮:给业务开发提供黑科技装备的“测试Q博士”">潘在亮:给业务开发提供黑科技装备的“测试Q博士”
工作时间:8:00-18:00
客服电话
电子邮件
admin@qq.com
扫码二维码
获取最新动态






![在ASP.NET中防止注入攻击[翻译]](https://www.cnblogs.com/Images/OutliningIndicators/None.gif)


![BZOJ 3450: Tyvj1952 Easy [DP 概率]](/upload/rand_pic/2-1512.jpg)