首页
语法
变量
函数
技术动态
基础知识库
首页
/
hadoop概述
python hadoop,3.3 Spark概述
文章目錄 spark簡介1、什么是spark2、為什么要學習spark3、spark特點 spark生態參考 spark簡介 1、什么是spark 基于內存的計算引擎,它的計算速度非常快。但是僅僅只涉及到 數據的計算 \color{#70f3ff}{\boxed{\color{green}{\text{數據的計算}}}}
时间:2023-12-09 | 阅读:23
hdfs和hadoop的關系,大數據之-Hadoop之HDFS_HDFS的內容介紹---大數據之hadoop工作筆記0047
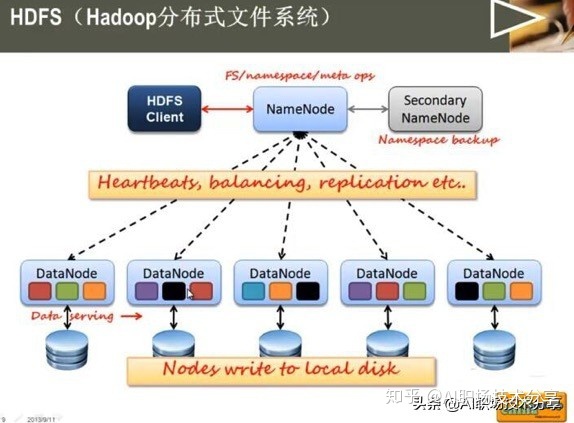
我們說hdfs,包含namenode和datanode和secondarynamenode hdfs和hadoop的關系、其中namenode是很重要,存了元數據,然后 secondarynamenode 相當于namenode的補充,當namenode掛了,secondarynamenode好補上去. 大數據平臺介紹,看看HDFS的介紹
时间:2023-10-07 | 阅读:15
當前的大數據背景是什么,大數據之-Hadoop之HDFS_HDFS產生背景以及定義---大數據之hadoop工作筆記0048
然后來看一下HDFS 的產生背景,其實就是一臺服務器,存不下,需要放到多個服務器,那么 當前的大數據背景是什么,讀取的時候怎么讀取? 需要一個文件管理系統,來管理多個服務器上存儲的這些文件. 關于大數據背景,HDFS只是一種文件管理系統,我們windows用的NTSF文件管理系統
时间:2023-10-07 | 阅读:16
hadoop应用开发技术..._Hadoop
Hadoop历史雏形开始于2002年的Apache的Nutch,Nutch是一个开源Java 实现的搜索引擎。它提供了我们运行自己的搜索引擎所需的全部工具。包括全文搜索和Web爬虫。hadoop环境。随后在2003年Google发表了一篇技术学术论文谷歌文件系统(GFS)。GFS也就是google
时间:2023-09-09 | 阅读:9
阅读排行
2708℃
1
如何防止应用程序泄密?
2522℃
2
linux中MySQL密码的恢复方...
2506℃
3
AlertDialog禁止返回键
2362℃
4
node.js当中net模块的简单...
2213℃
5
我的高质量软件发布心得
2144℃
6
从源码角度看Spark on yar...
2000℃
7
在linux云服务器上运行Jar...
1553℃
8
codevs1521 华丽的吊灯
猜你喜欢
新手教程——在Linux Mint 16中找到保存的WiFi密码
设置windows网络连接别名和linux网络连接别名
编写了一个文件编码转换器。
《从零开始学Swift》学习笔记(Day 40)——析构函数
朝鲜不小心泄漏了它的.kp域名DNS数据
23.多线程 实现的两种方式
网络地址转换实验
如何在Wireshark确定数据集?
从Softmax回归到Logistic回归
Nginx站点缓存设置
java 替换中文
【酷熊科技】工作积累 ----------- Unity3d中的Awake()、OnEnable()、Start()等默认函数的执行顺序和生命周期...
热门标签
python3
Spring boot
python有什么用
python和java
java
Springboot教程
python编程
Leetcode
python爬蟲教程
python菜鳥教程
Springboot注解
Mybatis
Springboot框架
Springboot
UNIXLINUX
SpringBootApplication
python为什么叫爬虫
qpython
我要关灯
我要开灯
客户电话
工作时间:8:00-18:00
客服电话
电子邮件
admin@qq.com
官方微信
扫码二维码
获取最新动态
返回顶部