分享一篇今天新出的重要文章:Scaled-YOLOv4: Scaling Cross Stage Partial Network,作者出自 YOLOv4 的原班人馬,其聚焦于針對 YOLOv4 的模型縮放(model scale)。
該文作者信息:

論文地址:https://arxiv.org/2011.08036
scaled yolov4?代碼地址: https://github.com/WongKinYiu/ScaledYOLOv4
旗下重要的三個模型:
YOLOv4-CSP(面向普通GPU):
https://github.com/WongKinYiu/ScaledYOLOv4/tree/yolov4-csp
YOLOv4-tiny(面向低端GPU):
https://github.com/WongKinYiu/ScaledYOLOv4/tree/yolov4-tiny
神經網絡求最大值?YOLOv4-large(面向高端GPU):
https://github.com/WongKinYiu/ScaledYOLOv4/tree/yolov4-large
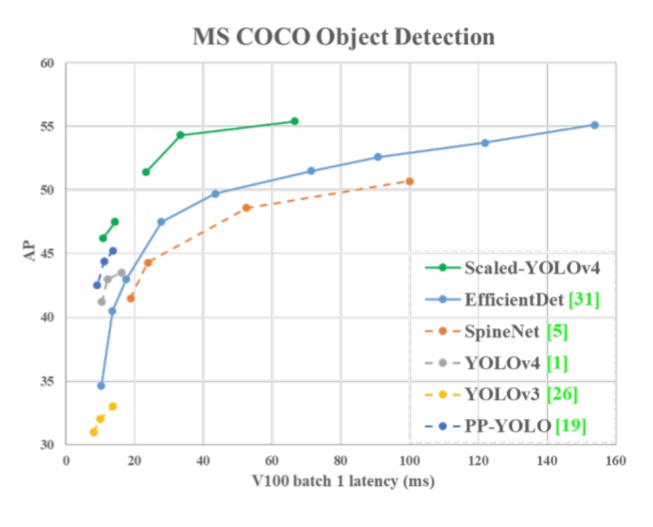
1)其開發的 YOLOv4-large 在COCO 數據集達到 SOTA 精度: 55.4% AP(73.3% AP50) 并以以15 fps 在 Tesla V100 運行, 而如果加上測試階段數據增強方法后,YOLOv4-large 達到 55.8% AP (73.2 AP50。 作者稱這一精度是所有已公開文獻的最高精度。
2)另外其 YOLOv4-tiny 模型在 COCO 數據集達到 22.0% AP (42.0% AP50) , ~443 FPS 在 RTX 2080Ti 運行, 當使用 TensorRT 做推理, batch size = 4 和 FP16 推斷時, YOLOv4-tiny 甚至可達到 1774 FPS!
首先我們要搞清楚這篇文章作者的本意,其本不是沖著提高檢測精度而來的。其主要考慮的是在深度學習技術應用領域不斷擴大的今天,面向實際工程部署,往往需要的不是一個模型而是一套模型。
yolov3是什么語言。部署在云端,也許你有高端大氣上檔次的V100 ,部署在個人電腦有大量的消費級GPU可選如2080TI(當然還是略貴~),部署在嵌入式平臺可以選擇TX2 、Jetson NANO等“弱機”。
模型縮放即希望一個算法衍生出多個模型,對計算和存儲的需求不同(精度當然也不同),以滿足部署在不同平臺的需求。其實這當然不是什么新概念,EfficientNet、EfficientDet即是一個算法的一系列模型。
作為工業界寵愛的 YOLOv4, 需要模型縮放。
正如之前跟大家分享過 YOLOv4 論文一樣,作者們依然采用了極其工程化的方法設計 Scaled-YOLOv4 ,沒有發明什么新思想、新路徑,而是“博采眾長”,“努力調優”。
以往模型縮放,如 EfficientDet 無非是首先選擇網絡基礎模塊,它往往又好又快,然后針對影響目標檢測的重要參數如:網絡寬度 w、深度 d、輸入圖像分辨率size等進行(滿足一定條件下按照一定規律)調參。
雖然神經架構搜索也常被用于設計不同平臺的一系列不同模型,但 EfficientDet 已經證明上述方法其實是很有效。
yolov4速度,作者針對不同的 GPU 設計不同模型。思路依然是尋找基礎模塊,然后調整網絡寬度 w、深度d、輸入圖像分辨率 size。
作者認為之前的工作沒有系統性分析各個網絡因素的影響,而作者進行了系統分析。
這里CV君不再跟大家分享作者的分析細節,只上結論。
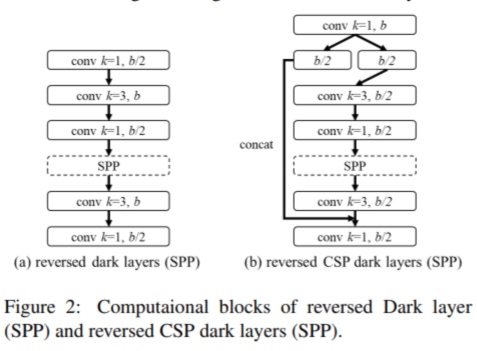
針對普通 GPU,對應 YOLOv4-CSP,作者選擇了 CSPNet (CVPR 2020 Workshop 論文)啟發下的 CSP-ized(CSP化的)模型作為基礎結構。作為后來者,相比 EfficientDet,設計 Scaled-YOLOv4 能選擇的網絡結構更多,當然是有優勢的。
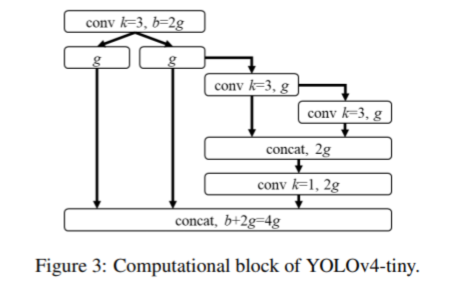
針對嵌入式等平臺上的弱 GPU,對應 YOLOv4-tiny ,除了考慮計算量,作者尤其提到要考慮內存訪問速度、內存帶寬、DRAM 速度的影響,作者選擇了 OSANet 作為整體結構,并依然進行了 CSP 化,即 CSPOSANet 。CV君覺得這是搞工程化的人最值得參考的地方。
神經網絡參數量計算、
對于高端 GPU,對應 YOLOv4-Large,首要考慮的是追求高精度,所以作者在提高輸入圖像分辨率和增加 stage 上下功夫,因為這直接影響不同分辨率目標和算法感受野,輸入分辨率高、算法感受野大能檢測到更多目標。
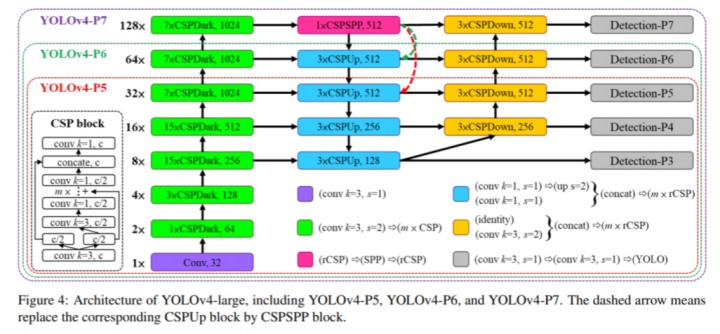
作者在 COCO 數據集上進行了測試,未使用預訓練權重,從頭開始訓練。
盡管 Scaled-YOLOv4 并不單純追求精度高,但跟 SOTA 算法相比依然很能打。
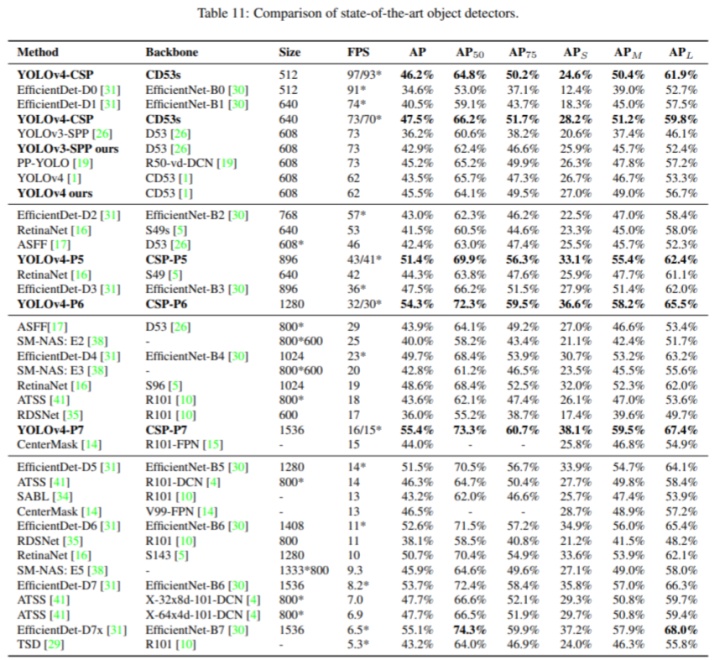
yolov4網絡結構。請注意,表中的 YOLOv4 -CSP、P5、P6、P7 依然都是實時算法,針對幀率 15fps(v100 GPU上測試),當然 YOLOv4-P7 也取得了最高的精度,但相比相同輸入分辨率的EfficientDet-D7x 也并未出現碾壓的架勢,在 Large 目標上 EfficientDet-D7x 是最優秀的,YOLOv4-P7 對小目標檢測更好。
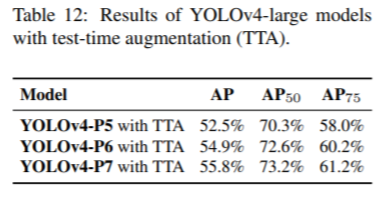
YOLOv4-Large 加上測試時圖像增強(TTA,這時在工程應用時經常做的)后,精度獲得了小幅提升:
YOLOv4-tiny同樣很優秀,相比其他主打小模型計算量小的算法,取得了速度和精度的雙優。

盡管在算法設計上,該文并沒有帶來重要亮點,但從工程應用的角度講, Scaled-YOLOv4 無疑是極其優秀的選擇!尤其是 YOLOv4-tiny,其設計不僅考慮到計算量和參數量還考慮到內存訪問,感謝作者團隊的開源!
版权声明:本站所有资料均为网友推荐收集整理而来,仅供学习和研究交流使用。

工作时间:8:00-18:00
客服电话
电子邮件
admin@qq.com
扫码二维码
获取最新动态











