這是《流暢的Python第二版》搶先版的讀書筆記。Python版本暫時用的是python3.8。為了使開發更簡單、快捷,本文使用了JupyterLab。
字典類型不僅廣泛地應用于我們的程序,而且是Pthon實現的基礎。類和實例的屬性、模型命名空間和函數的關鍵詞參數都是通過字典表示的。
正是因為字典這種重要的角色,Python字典是高度優化的。而哈希表(Hash talbes)是高性能的字典里面的引擎。
python基礎筆記、其他基于哈希表的內建類型是set和frozenset。
與第一版相比,本章的新內容為:
set中的使用開始解釋它。__dict__。dict.keys,dict.items,dict.values返回的視圖對象(Python3.0)collections.abc模塊提供了Mapping和MutableMappings抽象基類來描述字典和類似類型的接口。

python第一章總結,這些抽象基類的主要價值是記錄和形式化映射的標準接口,并作為代碼中 isinstance需要支持是否為映射的測試要求:
from collections import abc
from pprint import pprintmy_dict = {}
print(isinstance(my_dict, abc.Mapping)) # True
print(isinstance(my_dict, abc.MutableMapping)) # True
如果想要實現自定義映射,比較容易的方式是繼承collections.UserDict類,或通過組合模式封裝一個dict,而不是去繼承這些抽象基類。標準庫中的collections.UserDict類和所有具體的映射類都封裝了基本的字典,都是基于哈希表實現的。因此,它們都需要鍵是hashable(可哈希的)。
可哈希的是什么意思?
一個對象是可哈希的如果它有一個整個生命周期內都不會改變的哈希值,這需要實現
__hash__()方法;還需要能和其他對象比較,要實現__eq__()方法。當可哈>希的對象相等時必須有相同的哈希值。
python數據科學手冊。基于這些規則,你可以通過多種方式構建字典。
a = dict(one=1, two=2, three=3)
b = {'three': 3, 'two': 2, 'one': 1}
c = dict([('two', 2), ('one', 1), ('three', 3)])
d = dict(zip(['one', 'two', 'three'], [1, 2, 3]))
e = dict({'three': 3, 'one': 1, 'two': 2})a == b == c == d == e # True
所有上面字典的實例都是相等的,因為它們有相同的鍵值對,這里鍵值對的順序無關。
Python3.6開始支持保存鍵的插入順序,并作為一個Python3.7的特性。所以我們可以依賴這一點:

在Python3.6之前,c.popitem()會返回任意的鍵值對,現在它總是返回最后的鍵值對。
話不多說,舉個例子:
# 一個鍵值對列表
dial_codes = [ (880, 'Bangladesh'),(55, 'Brazil'),(86, 'China'),(91, 'India'),(62, 'Indonesia'),(81, 'Japan'),(234, 'Nigeria'),(92, 'Pakistan'),(7, 'Russia'),(1, 'United States'),
]# 利用字典推導式構建字典
# 這里我們把country作為key, code作為value
country_dial = {country: code for code, country in dial_codes}
country_dial
{'Bangladesh': 880,'Brazil': 55,'China': 86,'India': 91,'Indonesia': 62,'Japan': 81,'Nigeria': 234,'Pakistan': 92,'Russia': 7,'United States': 1}
# 排序、把code作為key,country作為value、過濾
{code: country.upper() for country, code in sorted(country_dial.items())if code < 70}
{55: 'BRAZIL', 62: 'INDONESIA', 7: 'RUSSIA', 1: 'UNITED STATES'}
下面顯示了dict和兩個有用的變種的方法,defaultdict和OrderedDict。
| dict | defaultdict | OrderedDict | ||
|---|---|---|---|---|
d.clear() | ?? | ?? | ?? | 移除所有元素 |
d.__contains__(k) | ?? | ?? | ?? | k in d |
d.copy() | ?? | ?? | ?? | 淺復制 |
d.__copy__() | ?? | 用于支持 copy.copy | ||
d.default_factory | ?? | 被 __missing__函數調用,用以給未找到的元素設置值 | ||
d.__delitem__(k) | ?? | ?? | ?? | del d[k]—移除鍵為k的元素 |
d.fromkeys(it, [initial]) | ?? | ?? | ?? | 將迭代器 it 里的元素設置為映射里的鍵,如果有 initial 參數,就把它作為這鍵對應的值(默認是 None) |
d.get(k, [default]) | ?? | ?? | ?? | 返回k對應的值, 返貨 default 或 None 如果不存在k |
d.__getitem__(k) | ?? | ?? | ?? | 讓字典能用d[k]的形式返回k對應的值 |
d.items() | ?? | ?? | ?? | 返回d里所有鍵值對—(key, value) 對 |
d.__iter__() | ?? | ?? | ?? | 獲取鍵的迭代器 |
d.keys() | ?? | ?? | ?? | 獲取所有的鍵 |
d.__len__() | ?? | ?? | ?? | len(d) |
d.__missing__(k) | ?? | 當 __getitem__ 找不到k時被調用 | ||
d.move_to_end(k, [last]) | ?? | 移動 k到最前或最后 (last 默認為 True ) | ||
d.pop(k, [default]) | ?? | ?? | ?? | 移除并返回k對應的值,或default或None 如果k不存在 |
d.popitem() | ?? | ?? | ?? | 移除最后插入的鍵值對—— (key, value) |
d.__reversed__() | ?? | ?? | ?? | 返回倒序的鍵迭代器 |
d.setdefault(k, [default]) | ?? | ?? | ?? | 如果 k in d, 返回 d[k]; 否則設置 d[k] = default并返回 |
d.__setitem__(k, v) | ?? | ?? | ?? | d[k] = v |
d.update(m, [**kwargs]) | ?? | ?? | ?? | 從映射或可迭代的(key, value)對中更新 d |
d.values() | ?? | ?? | ?? | 返回字典里的所有制 |
當字典d執行d.update(m)時,Python會把參數m當成鴨子類型(duck type):首先會檢查m是否有keys方法,若有,假設它為一個映射。
否則,假設m是(key,value)鍵值對。
一個好用的映射方法是setdefault(),當字典元素的值可變時,它避免了冗余的鍵查找,并且可以原地修改它。
在Python的快速失敗哲學里,字典訪問d[k]會拋出異常當k不存在時。每個Python人都知道d.get(k,default)是d[k]的一種替代方法,當k不存在時,不是報錯,而是返回默認值default。然而,當我們想不存在即更新時,無論是d[k]還是get都不方便。
這段程序從索引中獲取單詞出現的頻率信息,并把它們寫進對應的列表里。
index0.py:
import re
import sysWORD_RE = re.compile(r'\w+')index = {}
with open(sys.argv[1], encoding='utf-8') as fp:for line_no, line in enumerate(fp, 1):for match in WORD_RE.finditer(line):word = match.group()column_no = match.start() + 1location = (line_no, column_no)# 這是一種不好的實現,這樣寫只是為了證明論點occurrences = index.get(word, []) # ①讀取word出現的列表,沒有則返回空列表occurrences.append(location) # ②把單詞新出現的位置添加到列表的后面index[word] = occurrences # ③把新的列表放回字典中,又涉及到一次查詢操作# 以字母順序打印結果
for word in sorted(index, key=str.upper): # 用sorted 函數的 key= 參數沒有調用 str.uppper,而是把這個方法的引用傳遞給 sorted 函數,這樣在排序的時候,單詞會被規范成統一格式。print(word, index[word])
zen.txt:
The Zen of Python, by Tim PetersBeautiful is better than ugly.
Explicit is better than implicit.
Simple is better than complex.
Complex is better than complicated.
Flat is better than nested.
Sparse is better than dense.
Readability counts.
Special cases aren't special enough to break the rules.
Although practicality beats purity.
Errors should never pass silently.
Unless explicitly silenced.
In the face of ambiguity, refuse the temptation to guess.
There should be one-- and preferably only one --obvious way to do it.
Although that way may not be obvious at first unless you're Dutch.
Now is better than never.
Although never is often better than *right* now.
If the implementation is hard to explain, it's a bad idea.
If the implementation is easy to explain, it may be a good idea.
Namespaces are one honking great idea -- let's do more of those!
以上面這個文件作為參數調用。
(py38) $ python index0.py zen.txt
a [(19, 48), (20, 53)]
Although [(11, 1), (16, 1), (18, 1)]
ambiguity [(14, 16)]
and [(15, 23)]
are [(21, 12)]
aren [(10, 15)]
at [(16, 38)]
bad [(19, 50)]
be [(15, 14), (16, 27), (20, 50)]
beats [(11, 23)]
Beautiful [(3, 1)]
better [(3, 14), (4, 13), (5, 11), (6, 12), (7, 9), (8, 11), (17, 8), (18, 25)]
break [(10, 40)]
by [(1, 20)]
cases [(10, 9)]
complex [(5, 23)]
Complex [(6, 1)]
complicated [(6, 24)]
counts [(9, 13)]
dense [(8, 23)]
do [(15, 64), (21, 48)]
Dutch [(16, 61)]
easy [(20, 26)]
enough [(10, 30)]
Errors [(12, 1)]
explain [(19, 34), (20, 34)]
Explicit [(4, 1)]
explicitly [(13, 8)]
face [(14, 8)]
first [(16, 41)]
Flat [(7, 1)]
good [(20, 55)]
great [(21, 28)]
guess [(14, 52)]
hard [(19, 26)]
honking [(21, 20)]
idea [(19, 54), (20, 60), (21, 34)]
If [(19, 1), (20, 1)]
implementation [(19, 8), (20, 8)]
implicit [(4, 25)]
In [(14, 1)]
is [(3, 11), (4, 10), (5, 8), (6, 9), (7, 6), (8, 8), (17, 5), (18, 16), (19, 23), (20, 23)]
it [(15, 67), (19, 43), (20, 43)]
let [(21, 42)]
may [(16, 19), (20, 46)]
more [(21, 51)]
Namespaces [(21, 1)]
nested [(7, 21)]
never [(12, 15), (17, 20), (18, 10)]
not [(16, 23)]
Now [(17, 1)]
now [(18, 45)]
obvious [(15, 49), (16, 30)]
of [(1, 9), (14, 13), (21, 56)]
often [(18, 19)]
one [(15, 17), (15, 43), (21, 16)]
only [(15, 38)]
pass [(12, 21)]
Peters [(1, 27)]
practicality [(11, 10)]
preferably [(15, 27)]
purity [(11, 29)]
Python [(1, 12)]
re [(16, 58)]
Readability [(9, 1)]
refuse [(14, 27)]
right [(18, 38)]
rules [(10, 50)]
s [(19, 46), (21, 46)]
should [(12, 8), (15, 7)]
silenced [(13, 19)]
silently [(12, 26)]
Simple [(5, 1)]
Sparse [(8, 1)]
Special [(10, 1)]
special [(10, 22)]
t [(10, 20)]
temptation [(14, 38)]
than [(3, 21), (4, 20), (5, 18), (6, 19), (7, 16), (8, 18), (17, 15), (18, 32)]
that [(16, 10)]
The [(1, 1)]
the [(10, 46), (14, 4), (14, 34), (19, 4), (20, 4)]
There [(15, 1)]
those [(21, 59)]
Tim [(1, 23)]
to [(10, 37), (14, 49), (15, 61), (19, 31), (20, 31)]
ugly [(3, 26)]
Unless [(13, 1)]
unless [(16, 47)]
way [(15, 57), (16, 15)]
you [(16, 54)]
Zen [(1, 5)]
index0.py中的①-③那三行可以用dict.setdfault一行來代替。如下所示:
index.py:
import re
import sysWORD_RE = re.compile(r'\w+')index = {}
with open(sys.argv[1], encoding='utf-8') as fp:for line_no, line in enumerate(fp, 1):for match in WORD_RE.finditer(line):word = match.group()column_no = match.start() + 1location = (line_no, column_no)index.setdefault(word, []).append(location) # 獲取單詞的出現情況列表,如果單詞不存在,把單詞和一個空列表放進映射,然后返回這個空列表,這樣就能在不進行第二次查找的情況下更新列表了。for word in sorted(index, key=str.upper):print(word, index[word])
總之,下面這行代碼的結果:
my_dict.setdefault(key, []).append(new_value)
和三行代碼的結果是一樣的:
if key not in my_dict:my_dict[key] = []
my_dict[key].append(new_value)
不過后者至少要進行兩次鍵查詢——如果鍵不存在的話,就是三次,用 setdefault 只需要一次查詢就可以完成整個操作。
有時候為了方便起見,就算某個鍵在映射里不存在,我們也希望在通過這個鍵讀取值的時候能得到一個默認值。有兩個途徑能幫我們達到這個
目的,一個是通過 defaultdict 這個類型而不是普通的 dict,另一個是繼承dict或任意映射類型,然后在子類中實現 __missing__ 方法。下面將介紹這兩種方法。
index_default.py:
import collections
import re
import sysWORD_RE = re.compile(r'\w+')index = collections.defaultdict(list) # 創建一個defaultdict實例,以list構造函數作為default_factory
with open(sys.argv[1], encoding='utf-8') as fp:for line_no, line in enumerate(fp, 1):for match in WORD_RE.finditer(line):word = match.group()column_no = match.start() + 1location = (line_no, column_no)index[word].append(location) # 如果 index 并沒有 word 的記錄,那么 default_factory 會被調用,為查詢不到的鍵創造一個值。這個值在這里是一個空的列表,然后# 這個空列表被賦值給 index[word],繼而被當作返回值返回,因此.append(location) 操作總能成功。for word in sorted(index, key=str.upper):print(word, index[word])
當實例化一個defaultdict時,需要給構造方法提供一個可調用對象,這個可調用對象會在 __getitem__碰到找不到的鍵的時候被調用,讓 __getitem__ 返回某種默認值。
像上面那樣,新建一個這樣的字典:dd = defaultdict(list),如果鍵new-key 在 dd 中還不存在的話,表達式 dd['new-key'] 會執行以下的步驟:
list() 來建立一個新列表。new-key 作為它的鍵,放到 dd 中。而這個用來生成默認值的可調用對象存放在名為 default_factory 的實例屬性里。如果沒有default_factory被提供,那么會報KeyError。
defaultdict中的defalut_factory只會為__getitem__提供默認值。比如,如果dd是defaultdict,k是一個不存在的鍵,dd[k]會調用default_factory去創建默認值,而dd.get(k)仍然返回None。
所有這一切背后的功臣其實是特殊方法 __missing__。它會在defaultdict 遇到找不到的鍵的時候調用 default_factory,而實際上這個特性是所有映射類型都可以選擇去支持的。
所有的映射類型在處理找不到的鍵的時候,都會牽扯到 __missing__方法。這也是這個方法稱作“missing”的原因。雖然基類 dict 并沒有定義這個方法,但是 dict 是知道有這么個東西存在的。也就是說,如果有一個類繼承了 dict,然后這個繼承類提供了 __missing__ 方法,那么在 __getitem__ 碰到找不到的鍵的時候,Python 就會自動調用它,而不是拋出一個 KeyError 異常。
__missing__方法只會被__getitem__調用。
有時候,你會希望在查詢的時候,映射類型里的鍵統統轉換成 str。
strkeydict0.py:
class StrKeyDict0(dict): # 繼承dictdef __missing__(self, key):if isinstance(key, str): # 如果缺失鍵本身就是str,則拋出KeyError異常raise KeyError(key)return self[str(key)] # 否則轉換為str再查找def get(self, key, default=None):try:return self[key] # self[key]把查找委托給__getitem__,這樣在宣布查找失敗之前,還能通過__missing__再給某個鍵一個機會except KeyError:return default # 如果拋出KeyError,那么說明__missing__也失敗了,于是返回默認值def __contains__(self, key):return key in self.keys() or str(key) in self.keys() # 先按照傳入鍵的原本值查找,如果沒找到,再用str()方法把鍵轉換成str再查找一次
當搜索非字符串鍵時,如果鍵不存在,StrKeyDict0將它轉換為str:
from strkeydict0 import StrKeyDict0d = StrKeyDict0([('2', 'two'), ('4', 'four')])

花點時間考慮為什么在__missing__實現中需要測試isinstance(key,str)。
沒有該測試,我們的__missing__方法對于任何鍵k,str或不是str。每當str(k)產生現有鍵時,可以正常工作。 但是,如果str(k)不是現有的鍵,我們會有無限的遞歸。
最后一行,self[str(key)]會調用__getitem__傳遞該str鍵,反過來會再次調用__missing__。
__contains__方法也是必須的,為了保持一致。這是因為k in d 這個操作會調用它,但是我們從 dict 繼承到的 __contains__方法不會在找不到鍵的時候調用 __missing__ 方法。__contains__里還有個細節,就是我們這里沒有用更具 Python 風格的方式——k in my_dict——來檢查鍵是否存在,因為那也會導致__contains__ 被遞歸調用。為了避免這一情況,這里采取了更顯式的方法,直接在這個self.keys() 里查詢。
collections.OrderedDict
OrderedDict 的 popitem 方法默認刪除并返回的是字典里的最后一個元素,但是如果像 my_odict.popitem(last=False) 這樣調用它,那么它刪除并返回第一個被添加進去的元素。自從Python3.6之后,內建的dict也有這個特性,因此使用這個類只是為了向前兼容。collections.ChainMap
collections.Counter
Counter 實現了 + 和 - 運算符用來合并記錄,還有像most_common([n]) 這類很有用的方法most_common([n]) 會按照次序返回映射里最常見的 n 個鍵和它們的計數。
下面這些映射類型不是用來直接實例化的,而是給我們繼承的,以創建自定義映射類型。
collections.UserDict : 一個純Python的實現,看起啦像標準的dict。collections.TypedDict : 這允許你使用類型提示來定義映射類型,以指定每個鍵的預期值類型。collections.UserDict 類的行為類似于 dict,但是它更慢,因為它是在 Python 中實現的,而不是在 C 中。
通常通過繼承UserDict而不是dict來創建一個新的映射類型,因為這更簡單。這體現正在,我們能夠改進上面定義的 StrKeyDict0 類,使得所有的鍵都存儲為字符串類型。
主要的原因是,內建的dict的某些方法在實現時走了一些捷徑,而我們繼承它時,不得不實現這些方法。但UserDict就不會存在這些問題。
另外一個值得注意的是,UserDict 并不是 dict 的子類,而是利用組合:它有一個叫作 data 的屬性,是 dict 的實例,這個屬性實際上是 UserDict 最終存儲數據的地方。這樣做的好處是,比起示例strkeydict0.py中UserDict 的子類就能在實現 __setitem__ 的時候避免不必要的遞歸,也可以讓 __contains__ 里的代碼更簡潔。
多虧了 UserDict,下面StrKeyDict 的代碼比StrKeyDict0 要短一些,功能卻更完善:它不但把所有的鍵都以字符串的形式存儲,還能處理一些創建或者更新實例時包含非字符串類型的鍵這類意外情況。
import collectionsclass StrKeyDict(collections.UserDict): # 繼承UserDictdef __missing__(self, key): # 和StrKeyDict0相同if isinstance(key, str):raise KeyError(key)return self[str(key)]def __contains__(self, key):return str(key) in self.data # __contains__ 則更簡潔些。這里可以放心假設所有已經存儲的鍵都是字符串。# 因此,只要在 self.data 上查詢就好了,并不需要像StrKeyDict0 那樣去麻煩 self.keys()。def __setitem__(self, key, item):self.data[str(key)] = item # __setitem__ 會把所有的鍵都轉換成字符串。由于把具體的實現委# 托給了 self.data 屬性,這個方法寫起來也不難。
因為 UserDict 繼承的是 MutableMapping,所以 StrKeyDict 里剩下的那些映射類型的方法都是從 UserDict、MutableMapping 和Mapping這些超類繼承而來的。
特別是最后的 Mapping 類,它雖然是一個抽象基類(ABC),但它卻提供了好幾個實用的方法。以下兩個方法值得關注。
MutableMapping.update
__init__ 里,讓構造方法可以利用傳入的各種參數(其他映射類型、元素是 (key,value) 對的可迭代對象和鍵值參數)來新建實例。因為這個方法在背后是用 self[key] = value 來添加新值的,所以它其實是在使用我們的 __setitem__ 方法。Mapping.get
StrKeyDict0中,我們不得不改寫 get 方法,好讓它的表現跟 __getitem__ 一致。而在StrKeyDict中就沒這個必要了,因為它繼承了 Mapping.get 方法,而 Python 的源碼中,這個方法的實現方式跟StrKeyDict0.get是一模一樣的。有時你需要不可變的映射類型。從 Python 3.3 開始,types 模塊中引入了一個封裝類名叫MappingProxyType。
如果給這個類一個映射,它會返回一個只讀的動態代理mappingproxy。這意味著如果對原映射做出了改動,我們通過這個mappingproxy可以觀察到,但是無法通過它對原映射做出修改
from types import MappingProxyTyped = {1: 'A'}
d_proxy = MappingProxyType(d)
d_proxy

字典實例方法.keys(),.values(),.items()相應地返回了dict_keys,dict_values,dict_items的類實例。這些字典視圖字典內部數據結構的只讀投影。
它們避免了等效的 Python 2方法的內存開銷,這些方法返回的列表復制了目標 dict 中已有的數據,它們還替換了返回迭代器的舊方法。

如果源字典更新了,你能馬上觀察到現存視圖內容的更新。

類dict_key、dict_values和dict_items是內部的:它們不能通過內建或任何標準模塊獲取,甚至如果你獲取到它們的一個引用,也無法用來創建新的視圖。
values_class = type({}.values())
v = values_class()
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
<ipython-input-45-f3d02f8dd591> in <module>1 values_class = type({}.values())
----> 2 v = values_class()TypeError: cannot create 'dict_values' instances
集合并不是Python中的新事物,但仍然是未充分利用的。set 和它的不可變類型 frozenset 直到 Python 2.3 才首次以模塊的形式出現,然后在 Python 2.6 中它們升級成為內置類型。
集合本質是許多唯一對象的聚集。大家都知道可以用來去重:
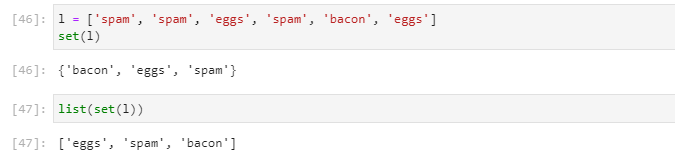
集合中的元素必須是可哈希的,set 類型本身是不可哈希的,所以你不能創建一個元素是set的set。
但是frozenset是可哈希的,所以可以創建一個包含不同 frozenset 的 set。
除了保證唯一性,集合還實現了很多基礎的中綴運算符。
給定兩個集合a 和b,a | b 返回的是它們的合集,a & b 得到的是交集,而 a - b得到的是差集。
例如,我們有一個電子郵件地址的集合(haystack),還要維護一個較小的電子郵件地址集合(needles),然后求出 needles 中有多少地
址同時也出現在了 heystack 里。借助集合操作,我們只需要一行代碼就可以了。
found = len(needles & haystack)
這種方式很快,但是需要它們都是集合。如果不是集合,你也可以很快地構造。
found = len(set(needles) & set(haystack))
# 或
found = len(set(needles).intersection(haystack))
除了極快的成員檢測(基于哈希表實現的),內建的集合類型還提供了豐富的API來創建或修改集合。
除空集之外,集合的字面量——{1}、{1, 2},等等——看起來跟它的數學形式一模一樣。如果是空集,那么必須寫成 set() 的形式。
如果寫
{},創建的是空字典,而不是空集合。

集合字面量像{1,2,3}不僅比調用構造函數的形式(如set([1,2,3]))更可讀,而且速度更快。
沒有特殊的語法來表示frozenset的字面量,因此,只能通過構造函數構建。
frozenset(range(10))
frozenset({0, 1, 2, 3, 4, 5, 6, 7, 8, 9})
from unicodedata import name
{chr(i) for i in range(32, 256) if 'SIGN' in name(chr(i),'')} # 把編碼在 32~255 之間的字符的名字里有“SIGN”單詞的挑出來,放到一個集合里。
{'#','$','%','+','<','=','>','¢','£','¤','¥','§','?','?','?','°','±','μ','?','×','÷'}
下圖列出了可變和不可變集合所擁有的方法的概況,其中不少是運算符重載的特殊方法。

下表則包含了數學里集合的各種操作在 Python 中所對應的運算符和方法。
| Math symbol | Python operator | Method | Description |
|---|---|---|---|
| S ∩ Z | s & z | s.__and__(z) | s 和 z的交集 |
z & s | s.__rand__(z) | 反向與(&)操作 | |
s.intersection(it, …) | 把可迭代的 it 和其他所有參數 轉化為集合,然后求它們與 s 的交集 | ||
s &= z | s.__iand__(z) | 把 s 更新為 s 和 z 的交集 | |
s.intersection_update(it, …) | 把可迭代的 it 和其他所有參數 轉化為集合,然后求得它們與 s 的交集,然后把 s 更新成這 個交集 | ||
| S ∪ Z | s | z | s.__or__(z) | s 和 z的并集 |
z | s | s.__ror__(z) | |的反向操作 | |
s.union(it, …) | 把可迭代的 it 和其他所有參數 轉化為集合,然后求它們和 s 的并集 | ||
s |= z | s.__ior__(z) | 把 s 更新為 s 和 z 的并集 | |
s.update(it, …) | 把可迭代的 it 和其他所有參數 轉化為集合,然后求它們和 s 的并集,并把 s 更新成這個并 集 | ||
| S \ Z | s - z | s.__sub__(z) | s 和 z 的差集,或者叫作相對補集 |
z - s | s.__rsub__(z) | - 的反向操作 | |
s.difference(it, …) | 把可迭代的 it 和其他所有參數 轉化為集合,然后求它們和 s 的差集 | ||
s -= z | s.__isub__(z) | 把 s 更新為它與 z 的差集 | |
s.difference_update(it, …) | 把可迭代的 it 和其他所有參數 轉化為集合,求它們和 s 的差 集,然后把 s 更新成這個差集 | ||
s.symmetric_difference(it) | 求 s 和 set(it) 的對稱差集 | ||
| S ? Z | s ^ z | s.__xor__(z) | 求 s 和 z 的對稱差集 |
z ^ s | s.__rxor__(z) | ^ 的反向操作 | |
s.symmetric_difference_update(it, …) | 把可迭代的 it 和其他所有參數 轉化為集合,然后求它們和 s 的對稱差集,最后把 s 更新成 該結果 | ||
s ^= z | s.__ixor__(z) | 把 s 更新成它與 z 的對稱差集 |
集合的比較運算符,返回值是布爾類型:
| Math symbol | Python operator | Method | Description |
|---|---|---|---|
s.isdisjoint(z) | 查看 s 和 z 是否不相交(沒有共同元 素) | ||
| e ∈ S | e in s | s.__contains__(e) | 元素 e 是否屬于 s |
| S ? Z | s <= z | s.__le__(z) | s 是否為 z 的子集 |
s.issubset(it) | 把可迭代的 it 轉化為集合,然后查看 s 是否為它的子集 | ||
| S ? Z | s < z | s.__lt__(z) | s 是否為 z 的真子集 |
| S ? Z | s >= z | s.__ge__(z) | s 是否為 z 的父集 |
s.issuperset(it) | 把可迭代的 it 轉化為集合,然后查看 s 是否為它的父集 | ||
| S ? Z | s > z | s.__gt__(z) | s 是否為 z 的真父集 |
除了跟數學上的集合計算有關的方法和運算符,集合類型還有一些為了實用性而添加的方法:
| set | frozenset | ||
|---|---|---|---|
s.add(e) | ?? | 把元素 e 添加到 s 中 | |
s.clear() | ?? | 移除掉 s 中的所有元素 | |
s.copy() | ?? | ?? | 對 s 淺復制 |
s.discard(e) | ?? | 如果 s 里有 e 這個元素的話,把它移除 | |
s.__iter__() | ?? | ?? | 返回 s 的迭代器 |
s.__len__() | ?? | ?? | len(s) |
s.pop() | ?? | 從 s 中移除一個元素并返回它的值,若 s 為空,則拋 出 KeyError 異常 | |
s.remove(e) | ?? | 從 s 中移除 e 元素,若 e 元素不存在,則拋出 KeyError 異常 |
到這里,我們差不多把集合類型的特性總結完了。
正如在字典視圖中提到的,我們現在來看這兩個字典視圖類型表現得多像frozenset。
下表顯示了集合方法:.keys()、.items()返回的視圖對象與frozenset有多相似:
| frozenset | dict_keys | dict_items | Description | |
|---|---|---|---|---|
s.__and__(z) | ?? | ?? | ?? | s & z |
s.__rand__(z) | ?? | ?? | ?? | 反向& |
s.__contains__() | ?? | ?? | ?? | e in s |
s.copy() | ?? | 對 s 淺復制 | ||
s.difference(it, …) | ?? | 把可迭代的 it 和其他所有參數 轉化為集合,然后求它們和 s 的差集 | ||
s.intersection(it, …) | ?? | 把可迭代的 it 和其他所有參數 轉化為集合,然后求它們與 s 的交集 | ||
s.isdisjoint(z) | ?? | ?? | ?? | 查看 s 和 z 是否不相交(沒有共同元 素) |
s.issubset(it) | ?? | 把可迭代的 it 轉化為集合,然后查看 s 是否為它的子集 | ||
s.issuperset(it) | ?? | 把可迭代的 it 轉化為集合,然后查看 s 是否為它的父集 | ||
s.__iter__() | ?? | ?? | ?? | 返回 s 的迭代器 |
s.__len__() | ?? | ?? | ?? | len(s) |
s.__or__(z) | ?? | ?? | ?? | s | z |
s.__ror__() | ?? | ?? | ?? | |的反向操作 |
s.__reversed__() | ?? | ?? | 返回 s 的逆序迭代器 | |
s.__rsub__(z) | ?? | ?? | ?? | - 的反向操作 |
s.__sub__(z) | ?? | ?? | ?? | s - z |
s.symmetric_difference(it) | ?? | 求 s 和 set(it) 的對稱差集 | ||
s.union(it, …) | ?? | 把可迭代的 it 和其他所有參數 轉化為集合,然后求它們和 s 的并集 | ||
s.__xor__() | ?? | ?? | ?? | 求 s 和 z 的對稱差集 |
s.__rxor__() | ?? | ?? | ?? | ^ 的反向操作 |
特別地,dict_keys 和 dict_items 實現了支持強大的集合運算符 & (交集)、 | (并集)、-(差集)和 ^ (對稱差)的特殊方法。
這意味著,例如,找到出現在兩個字典中的鍵就像這樣簡單:
d1 = dict(a=1, b=2, c=3, d=4)
d2 = dict(b=20, d=40, e=50)
d1.keys() & d2.keys()
{'b', 'd'}
注意,& 的返回值是一個集合。更好的是: 字典視圖中的 set 操作符與 set 實例兼容。看看這個:
s = {'a', 'e', 'i'}
d1.keys() & s
{'a'}
d1.keys() | s
{'a', 'b', 'c', 'd', 'e', 'i'}
現在我們換個話題來討論如何使用哈希表實現集合和字典。
想要理解 Python 里字典和集合類型的長處和弱點,它們背后的哈希表是繞不開的一環。
這一節將會回答以下幾個問題。
dict 和 set 的效率有多高?dict 的鍵或 set 里的元素?dict 的鍵和 set 元素的順序是跟據它們被添加的次序而定的?set中的元素順序看起來像隨機的?哈希表是一個精彩的發明, 我們看看當插入元素到集合時,哈希表是如何使用的。
假設我們有一個工作日縮寫的集合:
workdays = {'Mon', 'Tue', 'Wed', 'Thu', 'Fri'}
workdays
{'Fri', 'Mon', 'Thu', 'Tue', 'Wed'}
Python集合的核心數據結構就是哈希表,它至少有8行。通常,哈希表中的行叫作桶(bucket),所有的行叫作buckets。
一個存有工作日集合的哈希表如下所示:

每個桶有兩個字段:哈希碼(hash code)和指向元素值的指針。空桶的哈希碼為-1,順序看起來是隨機的。
因為存儲桶的大小是固定的,所以對單個桶的訪問是通過偏移量完成的。
內置的 hash() 方法可以用于所有的內置類型對象。如果是自定義對象調用hash() 的話,實際上運行的是自定義的 __hash__。
如果兩個對象在比較的時候是相等的,那它們的哈希碼必須相等,否則哈希表就不能正常運行了。例如,如果 1 == 1.0 為真,那么hash(1) == hash(1.0) 也必須為真,但其實這兩個數字(整型和浮點)的內部結構是完全不一樣的。
為了讓哈希碼能夠勝任哈希表索引這一角色,它們必須在索引空間中盡量分散開來。這意味著在最理想的狀況下,越是相似但不相等
的對象,它們哈希碼的差別應該越大。下面是一段代碼輸出,這段代碼被用來比較哈希碼的二進制表達的不同。
注意其中 1和 1.0 的哈希碼是相同的,而 1.0001、1.0002 和 1.0003 的哈希碼則非常不同。
32-bit Python build
1 00000000000000000000000000000001!= 0
1.0 00000000000000000000000000000001
------------------------------------------------
1.0 00000000000000000000000000000001! !!! ! !! ! ! ! ! !! !!! != 16
1.0001 00101110101101010000101011011101
------------------------------------------------
1.0001 00101110101101010000101011011101!!! !!!! !!!!! !!!!! !! ! != 20
1.0002 01011101011010100001010110111001
------------------------------------------------
1.0002 01011101011010100001010110111001! ! ! !!! ! ! !! ! ! ! !!!! != 17
1.0003 00001100000111110010000010010110
------------------------------------------------
在64位的CPython中,一個哈希碼是一個64位的數字,即有2642^{64}264可能值,它超過101910^{19}1019。但是大多數 Python 類型可以表示更多不同的值。例如,一個由10個可打印字符組成的字符串有10010100^{10}10010個可能的值——超過2662^{66}266個。因此,對象的哈希碼的信息通常少于實際對象值。這意味著不同的對象可能具有相同的哈希碼。
當不同的對象具有相同的哈希碼,被稱為哈希沖突。
我們首先關注集合的內部實現,后面再探討字典。

我們一步步看Python是如何構建集合{'Mon', 'Tue', 'Wed', 'Thu', 'Fri'}的。該算法通過上面的流程圖展示。
Step 0:實例化哈希表
正如前面提到的,一個集合的哈希表從8個空桶開始。在添加元素時,Python 會確保至少有13\frac{1}{3}31?個桶是空的,在需要更多空間時將哈希表的大小增加一倍。每個 bucket 的哈希碼字段用-1初始化,這意味著“沒有哈希碼”。
Step 1:計算元素的哈希碼
給定文本{'Mon', 'Tue', 'Wed', 'Thu', 'Fri'} ,Python 獲得第一個元素'Mon'的哈希碼。例如,這里有一個實際的 'Mon' 的哈希碼,你可能會得到一個不同的結果,因為 Python 加隨機鹽來計算字符串的哈希碼:
hash('Mon') # 4199492796428269555 因為每次計算hash都加鹽了,導致每次啟動Python得到的結果都不一樣,但是在每次Python運行期間內都是一樣的。 為了簡單,這里假設得到的哈希碼和原文中一樣。
Step 2:用哈希碼計算的索引來探測哈希表
計算哈希碼對哈希表大小取模的結果,作為索引。這里表大小為8,結果為:
4199492796428269555 % 8 # 3
探測包括從哈希碼計算索引,然后查看哈希表中相應的桶。在這種情況下,Python 查看位于偏移量3的 bucket,然后在哈希碼字段找到值-1,說明這是一個空桶。
Step 3:將元素放到空桶內
Python存儲新元素的哈希嗎,4199492796428269555,偏移量為3的bucket中,還存儲一個指向字符串對象'Mon'的指針到元素字段。下圖顯示了當前的哈希表狀態。

對于待插入集合內第二個元素,重復Step1,2,3。'Tue'的哈希碼為2414279730484651250,索引為2。
2414279730484651250 % 8 # 2
位于哈希表中索引2的桶依舊是空桶,放入其中,現在哈希表如下:

當添加'Wed'到集合中,Python計算得哈希碼為-5145319347887138165 索引為3。Python檢測索引3的桶,發現已經被用了。但是存儲在該桶中的哈希碼不同。這是索引沖突。Python然后探測下一個空桶。所以'Wed'最終放入索引4,如下:

添加下一個元素,'Thu',沒有沖突,它放入索引7。
添加最后一個元素'Fri',它的哈希碼為7021641685991143771 ,索引為3,它已經被'Wed'占用了。下面的索引4也被占用了,最終放入索引為5的位置:

最終哈希表的狀態如上圖所示。
這種在索引沖突后,增加索引值的方法叫做線性尋址法。
這個過程還有一種情況沒有說明,當新插入的元素的哈希碼和待插入位置處的哈希碼相同時,還需要比較元素是否相等。因為不同的對象仍然有可能有相同的哈希碼。
如果還有一個新元素要插入到我們例子中的哈希表,那么總元素個數會超過23\frac{2}{3}32?,這會增加索引沖突的可能。
Python此時會進行擴容操作,分配一個具有16個桶的哈希表,并把舊表中的元素全部插入。
給定下面的set,當插入整數1時會發生什么
s = {1.0, 2.0, 3.0}
s.add(1)
此時集合中有多少元素?整數1替換了1.0嗎?我們來看一下:


考慮上面的哈希表。我們想要知道’Sat’是否在表中。下面是最簡單的檢測Sat是否在其中的執行路徑:
hash('Sat')得到哈希碼,假設為49100126467909141664910012646790914166 % 8 = 6Sat并不在集合中,返回False。下面考慮集合中存在的元素,假設是’Thu’:
hash('Thu')得到哈希碼,假設為61660476093482675256166047609348267525 % 8 = 5True。Set 和 frozenset 類型都是通過哈希表實現的,哈希表具有以下特性:
__hash__ 和 __eq__ 方法。自從2012,字典類型的實現有兩個主要優化來減少內存占用。第一個是共享鍵字典(Key-Sharing Dictionary),第二是叫作壓縮字典(compact dict)。
考慮工作日->報名游泳人數的字典:
swimmers = {'Mon': 14, 'Tue': 12, 'Wed': 14, 'Thu': 11}
在進行壓縮字典優化之前,swimmers字典下面的哈希表如下圖所示。如你所見,在64位 Python 中,每個 bucket 包含三個64位字段: 鍵的哈希碼、鍵對象的指針和值對象的指針。也就是每個桶24個字節。

前兩個字段在集合的實現中起著相同的作用。為了找到key,Python 計算key的哈希碼,得到索引,然后探測哈希表,找到具有匹配哈希碼和匹配key對象的 bucket。第三個字段提供了 dict 的主要特性: 將鍵映射到任意值。key必須是一個可哈希的對象,哈希表算法確保它在字典中是唯一的。但它的值可以是任何對象———它不需要是可哈希的或唯一的。
Raymond Hettinger 提出,如果引入稀疏的索引數組,那么可以節省大量資源。具體來說,將哈希碼和指向鍵和值的指針保持在一個沒有空行的條目數組entries中。而實際的哈希表成了一個小得多的只保存索引的數組indices。這些索引指向的是entries數組中的元素。索引數組indices中桶的寬度從8位開始,因為2**8 = 256,但為了特殊用途保留負值(比如-1代表空,-2代表刪除),即仍然能對128個條目進行索引。

(因為是搶先版,這里感覺圖片和原文中計算壓縮字典共用104字節的結果都有問題。)
以swimmers字典為例,它的存儲狀態可能如上圖所示。
假設基于64位的 CPython,我們的4個元素的swimmers詞典在舊的方案中將占用192字節的內存: 每桶24字節,乘以8。
而等效的壓縮字典總共使用160個字節: 條目數組占96個字節(24 * 4) ,加上8個索引數組中的桶,每個桶占8字節,即64字節(8 * 8)。
Step 0: 構建索引數組indices
索引數組由有符號字節構成,初始8個桶,每個桶初始化為-1表示空桶。但最多只有5個桶會存有值,留下13\frac{1}{3}31?的空桶。
另一個數組entries會存儲鍵值對數組,和傳統的字典一樣有3個字段,但以插入順序存儲。
Step 1: 計算鍵的哈希碼
要插入鍵值對('Mon', 14)到swimmers字典,還是首先調用hash('Mon')得到哈希碼。
Step 2: 在索引數組中探測
計算hash('Mon') % len(indices),在我們的例子中,得到3。索引3位置的值是-1,代表空桶。
Step 3: 將鍵值對放入條目數組,并更新索引數組
條目數組此時是空的,所以條目數組中下一個可用的偏移量為0。Python把該偏移量0保存到索引數組中索引為3的位置,然后存儲鍵的哈希碼、指向鍵對象'Mon'的指針、指向值整數值14的指針到偏移量為0的條目數組中。

即索引數組保存的是條目數組中對應的偏移量。
要添加('Tue', 12):
'Tue'的哈希碼hash('Tue') % len(indices),這里是2。同時indices[2] == -1,此時還沒有沖突。1存入索引數組中的indices[2],然后存儲條目到條目數組entries[1]。
現在狀態如上,注意到條目數組保存了條目的插入順序信息。
'Wed'的哈希碼hash('Wed') % len(indices) == 3。而indices[3] == 0,指向了存在的條目。然后查看entries[0]處的哈希碼,它是'Mon'計算得到的哈希碼,假設和'Wed'得到的哈希碼不同。此時產生了沖突,則探測下一個索引:indices[4],它的值為-1,所以是可用的。indices[4] = 2,因為2是條目數組中下一個可用的偏移量,然后像之前那樣填充條目數組。
回想一下,索引數組中的 bucket 最初是8個帶符號字節,足以為最多5個條目保留偏移量,只留下13\frac{1}{3}31?個 bucket 為空。當第6項被添加到字典時,索引數組被重新分配到16個桶——足夠保存10個項。索引數組的大小根據需要加倍,同時仍然保留有符號字節,直到需要添加地129個元素到字典。此時,索引數組有256個8位桶。但是,一個有符號字節不足以保持128項以后的偏移量,因此重新構建索引數組以保存256個16位桶,以保存有符號整數——其寬度足以表示條目表中32,768行的偏移量。
下一次調整大小發生在第171次插入,當索引數組將存有超過23\frac{2}{3}32?。然后,索引數組中桶的數量增加了一倍,達到512個,但每個桶仍然是16位寬的。總之,索引數組的增長是通過將桶的數量加倍來實現的,而且通過將每個桶的寬度增加一倍來容納條目中越來越多的行,增長的頻率也會降低。
用戶定義類的實例通常將它們的屬性保存在 __dict__ 屬性中,它是一種常規字典。在實例 __dict__中,鍵值對中的鍵是屬性名稱,值是屬性值。大多數情況下,所有實例具有相同的屬性和不同的值。此時,條目表中每個實例的3個字段中有2個具有完全相同的內容: 屬性名稱的哈希碼和指向屬性名稱的指針。只有指向屬性值的指針是不同的。
在 PEP 412 — Key-Sharing Dictionary 中,Mark Shannon 提出了將鍵(與哈希碼)和值的存儲分離,鍵與哈希碼可以被多個字典實例共享。
給定一個 Movie 類,其中所有實例都具有相同的屬性,分別命名為"title"、“release”、“directors"和"actors”,下圖顯示了在一個拆分字典(split dictionary)中鍵共享的安排——也是用新的壓縮布局實現的。

PEP 412引入了術語 combined-table 來描述舊的布局以及用split-table描述新布局。
當使用字面語法或調用 dict ()創建 dict 時,默認使用combined-talbe。當某個類的第一個實例被創建時,一個split-table被創建來填充這個實例的特殊屬性__dict__。然后將 keys 表(見上圖)緩存到類對象中,這利用了大多數面向對象的 Python 代碼在 __init__ 方法中分配所有實例屬性的事實。
第一個實例(以及之后的所有實例)將只保存自己的value 數組(value arrays)。如果一個實例獲得了一個在共享鍵表(keys 表)中沒有找到的新屬性,那么該實例的
__dict__ 被轉換為combined-table格式。但是,如果這個實例是它所屬類唯一的實例,那么 __dict__ 將被轉換回split-table。因此假定新的實例將具有相同的屬性集,然后共享鍵是有用的。
在 CPython 源代碼中表示 dict 的 PyDictObject 結構對于combined-table和split-table字典是相同的。當 dict 從一個布局轉換到另一個布局時,在其他內部數據結構的幫助下,可以在PyDictObject字段中發生改變。
__hash__和__eq__方法。entries表中。__init__方法外創建實例屬性。如果所有的實例屬性都在__init__方法中創建,那么你類的實例的__dict__屬性會使用split-talbe布局,可以共享該類存儲的索引數組(indices)和鍵條目數組(key entries array)。版权声明:本站所有资料均为网友推荐收集整理而来,仅供学习和研究交流使用。

工作时间:8:00-18:00
客服电话
电子邮件
admin@qq.com
扫码二维码
获取最新动态


![centsos7修改主机名 [root@st152 ~]# cat /etc/hostname](http://static.blog.csdn.net/images/save_snippets.png)