【注】該系列文章以及使用到安裝包/測試數據 可以在《傾情大奉送--Spark入門實戰系列》獲取
1、運行環境說明
1.1?硬軟件環境
l? 主機操作系統:Windows 64位,雙核4線程,主頻2.2G,10G內存
l? 虛擬軟件:VMware? Workstation 9.0.0 build-812388
l? 虛擬機操作系統:CentOS 64位,單核
l? 虛擬機運行環境:
?? JDK:1.7.0_55 64位
?? Hadoop:2.2.0(需要編譯為64位)
?? Scala:2.10.4
?? Spark:1.1.0(需要編譯)
?? Hive:0.13.1
1.2?機器網絡環境
集群包含三個節點,節點之間可以免密碼SSH訪問,節點IP地址和主機名分布如下:
| 序號 | 機器名 | 類型 | 核數/內存 | 用戶名 | 目錄 | |
| 1 | 192.168.0.61 | hadoop1 | NN/DN/RM Master/Worker | 1核/3G | hadoop | /app 程序所在路徑 /app/scala-... /app/hadoop /app/complied |
| 2 | 192.168.0.62 | hadoop2 | DN/NM/Worker | 1核/2G | hadoop | |
| 3 | 192.168.0.63 | hadoop3 | DN/NM/Worker | 1核/2G | hadoop |
2、Spark基礎應用
SparkSQL引入了一種新的RDD——SchemaRDD,SchemaRDD由行對象(Row)以及描述行對象中每列數據類型的Schema組成;SchemaRDD很象傳統數據庫中的表。SchemaRDD可以通過RDD、Parquet文件、JSON文件、或者通過使用hiveql查詢hive數據來建立。SchemaRDD除了可以和RDD一樣操作外,還可以通過registerTempTable注冊成臨時表,然后通過SQL語句進行操作。
值得注意的是:
lSpark1.1使用registerTempTable代替1.0版本的registerAsTable
lSpark1.1在hiveContext中,hql()將被棄用,sql()將代替hql()來提交查詢語句,統一了接口。
l使用registerTempTable注冊表是一個臨時表,生命周期只在所定義的sqlContext或hiveContext實例之中。基于docker的SQL在線實驗平臺。換而言之,在一個sqlontext(或hiveContext)中registerTempTable的表不能在另一個sqlContext(或hiveContext)中使用。
另外,Spark1.1提供了語法解析器選項spark.sql.dialect,就目前而言,Spark1.1提供了兩種語法解析器:sql語法解析器和hiveql語法解析器。
lsqlContext現在只支持sql語法解析器(SQL-92語法)
lhiveContext現在支持sql語法解析器和hivesql語法解析器,默認為hivesql語法解析器,用戶可以通過配置切換成sql語法解析器,來運行hiveql不支持的語法,如select 1。
l切換可以通過下列方式完成:
l在sqlContexet中使用setconf配置spark.sql.dialect
l在hiveContexet中使用setconf配置spark.sql.dialect
l在sql命令中使用 set spark.sql.dialect=value
SparkSQL1.1對數據的查詢分成了2個分支:sqlContext 和 hiveContext。至于兩者之間的關系,hiveSQL繼承了sqlContext,所以擁有sqlontext的特性之外,還擁有自身的特性(最大的特性就是支持hive)。POSTGRESQL。
2.1?啟動Spark shell
2.1.1?環境設置
使用如下命令打開/etc/profile文件:
sudo vi /etc/profile
![]()
設置如下參數:
export SPARK_HOME=/app/hadoop/spark-1.1.0
export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin
?
export HIVE_HOME=/app/hadoop/hive-0.13.1
export PATH=$PATH:$HIVE_HOME/bin
export CLASSPATH=$CLASSPATH:$HIVE_HOME/bin

2.1.2?啟動HDFS
$cd /app/hadoop/hadoop-2.2.0/sbin
$./start-dfs.sh

2.1.3?啟動Spark集群
$cd /app/hadoop/spark-1.1.0/sbin
$./start-all.sh

2.1.4?啟動Spark-Shell
在spark客戶端(在hadoop1節點),使用spark-shell連接集群
$cd /app/hadoop/spark-1.1.0/bin
$./spark-shell --master spark://hadoop1:7077 --executor-memory 1g

啟動后查看啟動情況,如下圖所示:

2.2?sqlContext演示
Spark1.1.0開始提供了兩種方式將RDD轉換成SchemaRDD:
l通過定義Case Class,使用反射推斷Schema(case class方式)
l通過可編程接口,定義Schema,并應用到RDD上(applySchema 方式)
前者使用簡單、代碼簡潔,適用于已知Schema的源數據上;后者使用較為復雜,但可以在程序運行過程中實行,適用于未知Schema的RDD上。
2.2.1?使用Case Class定義RDD演示
對于Case Class方式,首先要定義Case Class,在RDD的Transform過程中使用Case Class可以隱式轉化成SchemaRDD,然后再使用registerTempTable注冊成表。注冊成表后就可以在sqlContext對表進行操作,如select 、insert、join等。注意,case class可以是嵌套的,也可以使用類似Sequences 或 Arrays之類復雜的數據類型。
下面的例子是定義一個符合數據文件/sparksql/people.txt類型的case clase(Person),然后將數據文件讀入后隱式轉換成SchemaRDD:people,并將people在sqlContext中注冊成表rddTable,最后對表進行查詢,找出年紀在13-19歲之間的人名。sql入門新手教程、
第一步?? 上傳測試數據
在HDFS中創建/class6目錄,把配套資源/data/class5/people.txt上傳到該目錄上
$hadoop fs -mkdir /class6
$hadoop fs -copyFromLocal /home/hadoop/upload/class6/people.* /class6
$hadoop fs -ls /

第二步?? 定義sqlContext并引入包
//sqlContext演示
scala>val sqlContext=new org.apache.spark.sql.SQLContext(sc)
scala>import sqlContext.createSchemaRDD

第三步?? 定義Person類,讀入數據并注冊為臨時表
//RDD1演示
scala>case class Person(name:String,age:Int)
scala>val rddpeople=sc.textFile("hdfs://hadoop1:9000/class6/people.txt").map(_.split(",")).map(p=>Person(p(0),p(1).trim.toInt))
scala>rddpeople.registerTempTable("rddTable")

第四步?? 在查詢年紀在13-19歲之間的人員
scala>sqlContext.sql("SELECT name FROM rddTable WHERE age >= 13 AND age <= 19").map(t => "Name: " + t(0)).collect().foreach(println)
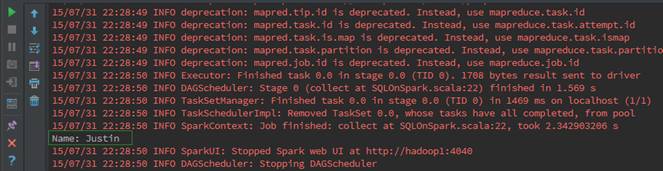
上面步驟均為trnsform未觸發action動作,在該步驟中查詢數據并打印觸發了action動作,如下圖所示:

通過監控頁面,查看任務運行情況:


2.2.2?使用applySchema定義RDD演示
applySchema 方式比較復雜,通常有3步過程:
l從源RDD創建rowRDD
l創建與rowRDD匹配的Schema
l將Schema通過applySchema應用到rowRDD
第一步?? 導入包創建Schema
//導入SparkSQL的數據類型和Row
scala>import org.apache.spark.sql._
//創建于數據結構匹配的schema
scala>val schemaString = "name age"
scala>val schema =
? StructType(
??? schemaString.split(" ").map(fieldName => StructField(fieldName, StringType, true)))

第二步?? 創建rowRDD并讀入數據
//創建rowRDD
scala>val rowRDD = sc.textFile("hdfs://hadoop1:9000/class6/people.txt").map(_.split(",")).map(p => Row(p(0), p(1).trim))
//用applySchema將schema應用到rowRDD
scala>val rddpeople2 = sqlContext.applySchema(rowRDD, schema)
scala>rddpeople2.registerTempTable("rddTable2")

第三步?? 查詢獲取數據
scala>sqlContext.sql("SELECT name FROM rddTable2 WHERE age >= 13 AND age <= 19").map(t => "Name: " + t(0)).collect().foreach(println)

通過監控頁面,查看任務運行情況:


2.2.3?parquet演示
同樣得,sqlContext可以讀取parquet文件,由于parquet文件中保留了schema的信息,所以不需要使用case class來隱式轉換。sqlContext讀入parquet文件后直接轉換成SchemaRDD,也可以將SchemaRDD保存成parquet文件格式。
第一步?? 保存成parquest格式文件
// 把上面步驟中的rddpeople保存為parquet格式文件到hdfs中
scala>rddpeople.saveAsParquetFile("hdfs://hadoop1:9000/class6/people.parquet")


第二步?? 讀入parquest格式文件,注冊表parquetTable
//parquet演示
scala>val parquetpeople = sqlContext.parquetFile("hdfs://hadoop1:9000/class6/people.parquet")
scala>parquetpeople.registerTempTable("parquetTable")

第三步?? 查詢年齡大于等于25歲的人名
scala>sqlContext.sql("SELECT name FROM parquetTable WHERE age >= 25").map(t => "Name: " + t(0)).collect().foreach(println)

2.2.4?json演示
sparkSQL1.1.0開始提供對json文件格式的支持,這意味著開發者可以使用更多的數據源,如鼎鼎大名的NOSQL數據庫MongDB等。sqlContext可以從jsonFile或jsonRDD獲取schema信息,來構建SchemaRDD,注冊成表后就可以使用。
ljsonFile - 加載JSON文件目錄中的數據,文件的每一行是一個JSON對象
ljsonRdd - 從現有的RDD加載數據,其中RDD的每個元素包含一個JSON對象的字符串
第一步?? 上傳測試數據
 ?
?
第二步?? 讀取數據并注冊jsonTable表
//json演示
scala>val jsonpeople = sqlContext.jsonFile("hdfs://hadoop1:9000/class6/people.json")
jsonpeople.registerTempTable("jsonTable")

第三步?? 查詢年齡大于等于25的人名
scala>sqlContext.sql("SELECT name FROM jsonTable WHERE age >= 25").map(t => "Name: " + t(0)).collect().foreach(println)

2.2.5?sqlContext中混合使用演示
在sqlContext或hiveContext中來源于不同數據源的表在各自生命周期中可以混用,即sqlContext與hiveContext之間表不能混合使用
//sqlContext中來自rdd的表rddTable和來自parquet文件的表parquetTable混合使用
scala>sqlContext.sql("select a.name,a.age,b.age from rddTable a join parquetTable b on a.name=b.name").collect().foreach(println)


2.3?hiveContext演示
使用hiveContext之前首先要確認以下兩點:
l使用的Spark是支持hive
lHive的配置文件hive-site.xml已經存在conf目錄中
前者可以查看lib目錄下是否存在以datanucleus開頭的3個JAR來確定,后者注意是否在hive-site.xml里配置了uris來訪問Hive Metastore。docker hadoop,
2.3.1?啟動hive
在hadoop1節點中使用如下命令啟動Hive
$nohup hive --service metastore > metastore.log 2>&1 &

2.3.2?在SPARK_HOME/conf目錄下創建hive-site.xml
?在SPARK_HOME/conf目錄下創建hive-site.xml文件,修改配置后需要重新啟動Spark-Shell
【注】如果在第6課《SparkSQL(二)--SparkSQL簡介》配置,
<configuration>?
? <property>
? ? <name>hive.metastore.uris</name>
??? <value>thrift://hadoop1:9083</value>
??? <description>Thrift URI for the remote metastore. Used by metastore client to connect to remote metastore.</description>
? </property>
</configuration>

2.3.3?查看數據庫表
要使用hiveContext,需要先構建hiveContext:
scala>val hiveContext = new org.apache.spark.sql.hive.HiveContext(sc)

然后就可以對Hive數據進行操作了,下面我們將使用Hive中的銷售數據,首先切換數據庫到hive并查看有幾個表:
//銷售數據演示
scala>hiveContext.sql("use hive")
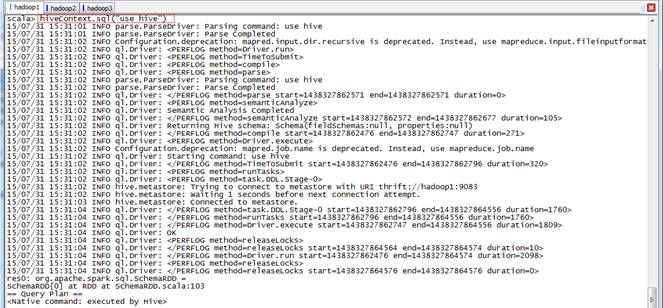
scala>hiveContext.sql("show tables").collect().foreach(println)


2.3.4?計算所有訂單中每年的銷售單數、銷售總額
//所有訂單中每年的銷售單數、銷售總額
//三個表連接后以count(distinct a.ordernumber)計銷售單數,sum(b.amount)計銷售總額
scala>hiveContext.sql("select c.theyear,count(distinct a.ordernumber),sum(b.amount) from tbStock a join tbStockDetail b on a.ordernumber=b.ordernumber join tbDate ?c on a.dateid=c.dateid group by c.theyear order by c.theyear").collect().foreach(println)
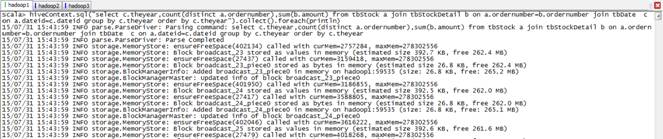
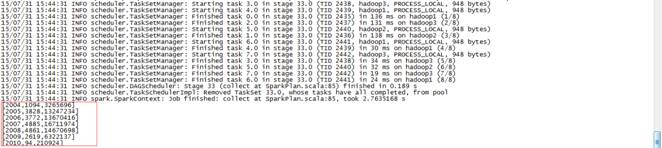
結果如下:
[2004,1094,3265696]
[2005,3828,13247234]
[2006,3772,13670416]
[2007,4885,16711974]
[2008,4861,14670698]
[2009,2619,6322137]
[2010,94,210924]
通過監控頁面,查看任務運行情況:
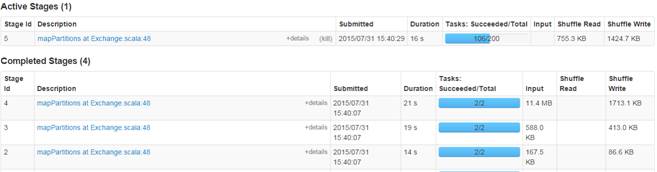
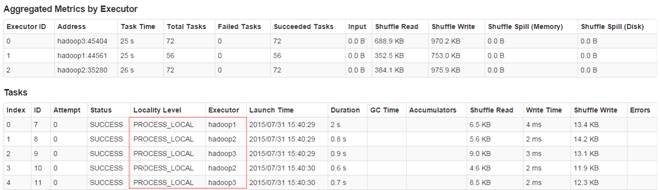
2.3.5?計算所有訂單每年最大金額訂單的銷售額
第一步?? 實現分析
所有訂單每年最大金額訂單的銷售額:
1、先求出每份訂單的銷售額以其發生時間
select a.dateid,a.ordernumber,sum(b.amount) as sumofamount from tbStock a join tbStockDetail b on a.ordernumber=b.ordernumber group by a.dateid,a.ordernumber
2、以第一步的查詢作為子表,和表tbDate 連接,求出每年最大金額訂單的銷售額
select c.theyear,max(d.sumofamount) from tbDate ?c join (select a.dateid,a.ordernumber,sum(b.amount) as sumofamount from tbStock a join tbStockDetail b on a.ordernumber=b.ordernumber group by a.dateid,a.ordernumber ) d? on c.dateid=d.dateid group by c.theyear sort by c.theyear
第二步?? 實現SQL語句
scala>hiveContext.sql("select c.theyear,max(d.sumofamount) from tbDate ?c join (select a.dateid,a.ordernumber,sum(b.amount) as sumofamount from tbStock a join tbStockDetail b on a.ordernumber=b.ordernumber group by a.dateid,a.ordernumber ) d? on c.dateid=d.dateid group by c.theyear sort by c.theyear").collect().foreach(println)
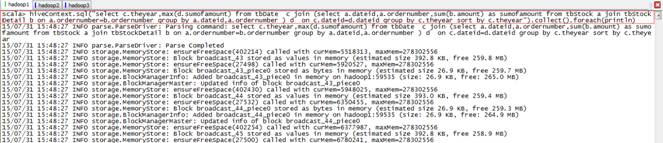

結果如下:
[2010,13063]
[2004,23612]
[2005,38180]
[2006,36124]
[2007,159126]
[2008,55828]
[2009,25810]
第三步?? 監控任務運行情況
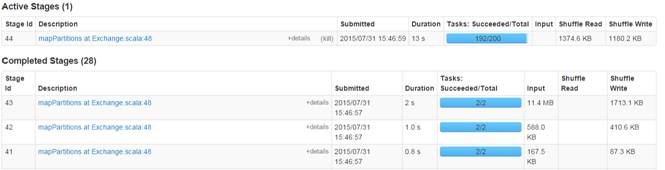
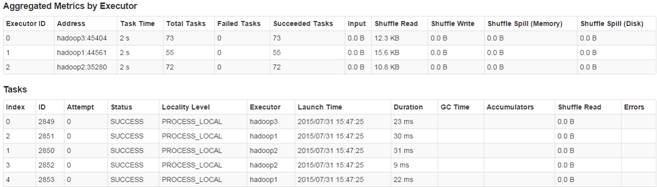
2.3.6?計算所有訂單中每年最暢銷貨品
第一步?? 實現分析
所有訂單中每年最暢銷貨品:
1、求出每年每個貨品的銷售金額
scala>select c.theyear,b.itemid,sum(b.amount) as sumofamount from tbStock a join tbStockDetail b on a.ordernumber=b.ordernumber join tbDate ?c on a.dateid=c.dateid group by c.theyear,b.itemid
2、求出每年單品銷售的最大金額
scala>select d.theyear,max(d.sumofamount) as maxofamount from (select c.theyear,b.itemid,sum(b.amount) as sumofamount from tbStock a join tbStockDetail b on a.ordernumber=b.ordernumber join tbDate ?c on a.dateid=c.dateid group by c.theyear,b.itemid) d group by d.theyear
3、求出每年與銷售額最大相符的貨品就是最暢銷貨品
scala>select distinct? e.theyear,e.itemid,f.maxofamount from (select c.theyear,b.itemid,sum(b.amount) as sumofamount from tbStock a join tbStockDetail b on a.ordernumber=b.ordernumber join tbDate ?c on a.dateid=c.dateid group by c.theyear,b.itemid) e join (select d.theyear,max(d.sumofamount) as maxofamount from (select c.theyear,b.itemid,sum(b.amount) as sumofamount from tbStock a join tbStockDetail b on a.ordernumber=b.ordernumber join tbDate ?c on a.dateid=c.dateid group by c.theyear,b.itemid) d group by d.theyear) f on (e.theyear=f.theyear and e.sumofamount=f.maxofamount) order by e.theyear
第二步?? 實現SQL語句
scala>hiveContext.sql("select distinct? e.theyear,e.itemid,f.maxofamount from (select c.theyear,b.itemid,sum(b.amount) as sumofamount from tbStock a join tbStockDetail b on a.ordernumber=b.ordernumber join tbDate ?c on a.dateid=c.dateid group by c.theyear,b.itemid) e join (select d.theyear,max(d.sumofamount) as maxofamount from (select c.theyear,b.itemid,sum(b.amount) as sumofamount from tbStock a join tbStockDetail b on a.ordernumber=b.ordernumber join tbDate ?c on a.dateid=c.dateid group by c.theyear,b.itemid) d group by d.theyear) f on (e.theyear=f.theyear and e.sumofamount=f.maxofamount) order by e.theyear").collect().foreach(println)

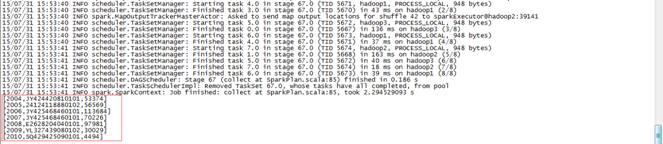
結果如下:
[2004,JY424420810101,53374]
[2005,24124118880102,56569]
[2006,JY425468460101,113684]
[2007,JY425468460101,70226]
[2008,E2628204040101,97981]
[2009,YL327439080102,30029]
[2010,SQ429425090101,4494]
第三步?? 監控任務運行情況
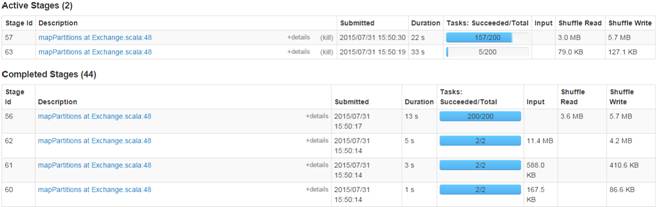
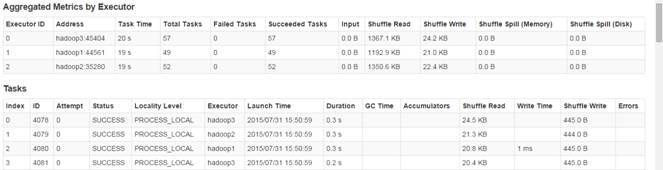
2.3.7?hiveContext中混合使用演示
第一步?? 創建hiveTable從本地文件系統加載數據
//創建一個hiveTable并將數據加載,注意people.txt第二列有空格,所以age取string類型
scala>hiveContext.sql("CREATE TABLE hiveTable(name string,age string) ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' LINES TERMINATED BY '\n' ")

scala>hiveContext.sql("LOAD DATA LOCAL INPATH '/home/hadoop/upload/class6/people.txt' INTO TABLE hiveTable")
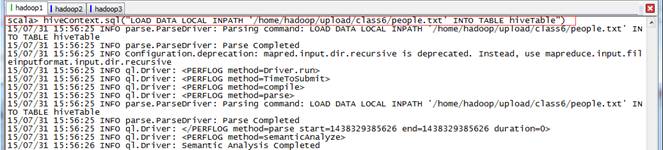
第二步?? 創建parquet表,從HDFS加載數據
//創建一個源自parquet文件的表parquetTable2,然后和hiveTable混合使用
scala>hiveContext.parquetFile("hdfs://hadoop1:9000/class6/people.parquet").registerTempTable("parquetTable2")

第三步?? 兩個表混合使用
scala>hiveContext.sql("select a.name,a.age,b.age from hiveTable a join parquetTable2 b on a.name=b.name").collect().foreach(println)
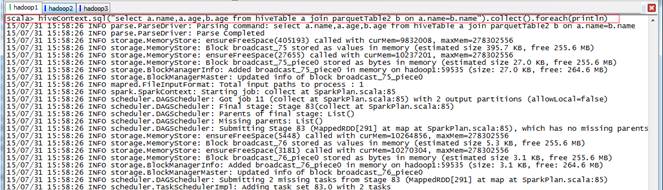

2.4?Cache使用
sparkSQL的cache可以使用兩種方法來實現:
lCacheTable()方法
lCACHE TABLE命令
千萬不要先使用cache SchemaRDD,然后registerAsTable;使用RDD的cache()將使用原生態的cache,而不是針對SQL優化后的內存列存儲。
第一步?? 對rddTable表進行緩存
//cache使用
scala>val sqlContext=new org.apache.spark.sql.SQLContext(sc)
scala>import sqlContext.createSchemaRDD
scala>case class Person(name:String,age:Int)
scala>val rddpeople=sc.textFile("hdfs://hadoop1:9000/class6/people.txt").map(_.split(",")).map(p=>Person(p(0),p(1).trim.toInt))
scala>rddpeople.registerTempTable("rddTable")
?
scala>sqlContext.cacheTable("rddTable")
scala>sqlContext.sql("SELECT name FROM rddTable WHERE age >= 13 AND age <= 19").map(t => "Name: " + t(0)).collect().foreach(println)
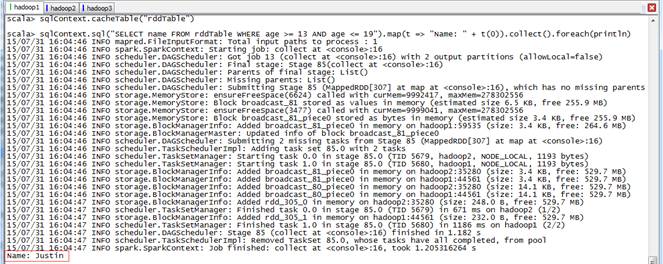
在監控界面上看到該表數據已經緩存

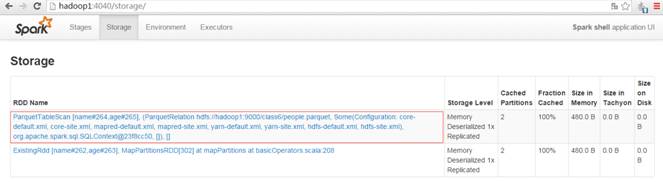
第二步?? 對parquetTable表進行緩存
scala>val parquetpeople = sqlContext.parquetFile("hdfs://hadoop1:9000/class6/people.parquet")
scala>parquetpeople.registerTempTable("parquetTable")
?
scala>sqlContext.sql("CACHE TABLE parquetTable")
scala>sqlContext.sql("SELECT name FROM parquetTable WHERE age >= 13 AND age <= 19").map(t => "Name: " + t(0)).collect().foreach(println)



在監控界面上看到該表數據已經緩存
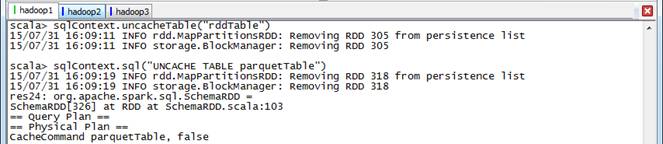
第三步?? 解除緩存
//uncache使用
scala>sqlContext.uncacheTable("rddTable")
scala>sqlContext.sql("UNCACHE TABLE parquetTable")

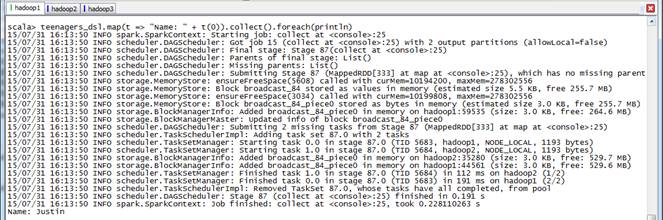
2.5?DSL演示
SparkSQL除了支持HiveQL和SQL-92語法外,還支持DSL(Domain Specific Language)。在DSL中,使用Scala符號'+標示符表示基礎表中的列,Spark的execution engine會將這些標示符隱式轉換成表達式。另外可以在API中找到很多DSL相關的方法,如where()、select()、limit()等等,詳細資料可以查看Catalyst模塊中的DSL子模塊,下面為其中定義幾種常用方法:
//DSL演示
scala>import sqlContext._
scala>val teenagers_dsl = rddpeople.where('age >= 10).where('age <= 19).select('name)
scala>teenagers_dsl.map(t => "Name: " + t(0)).collect().foreach(println)

3、Spark綜合應用
Spark之所以萬人矚目,除了內存計算還有其ALL-IN-ONE的特性,實現了One stack rule them all。下面簡單模擬了幾個綜合應用場景,不僅使用了sparkSQL,還使用了其他Spark組件:
lSQL On Spark:使用sqlContext查詢年紀大于等于10歲的人名
lHive On Spark:使用了hiveContext計算每年銷售額
l店鋪分類,根據銷售額對店鋪分類,使用sparkSQL和MLLib聚類算法
lPageRank,計算最有價值的網頁,使用sparkSQL和GraphX的PageRank算法
以下實驗采用IntelliJ IDEA調試代碼,最后生成LearnSpark.jar,然后使用spark-submit提交給集群運行。SQL自學。
3.1?SQL On Spark
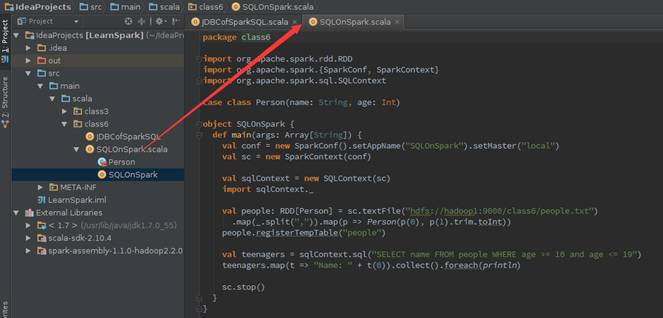
3.1.1?實現代碼
在src->main->scala下創建class6包,在該包中添加SQLOnSpark對象文件,具體代碼如下:
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.sql.SQLContext
?
case class Person(name: String, age: Int)
?
object SQLOnSpark {
? def main(args: Array[String]) {
??? val conf = new SparkConf().setAppName("SQLOnSpark")
??? val sc = new SparkContext(conf)
?
??? val sqlContext = new SQLContext(sc)
??? import sqlContext._
?
??? val people: RDD[Person] = sc.textFile("hdfs://hadoop1:9000/class6/people.txt")
????? .map(_.split(",")).map(p => Person(p(0), p(1).trim.toInt))
??? people.registerTempTable("people")
?
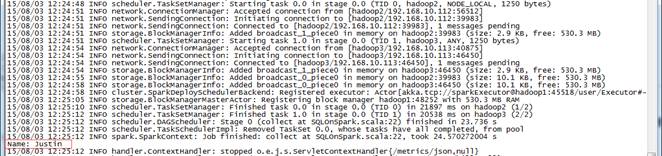
??? val teenagers = sqlContext.sql("SELECT name FROM people WHERE age >= 10 and age <= 19")
??? teenagers.map(t => "Name: " + t(0)).collect().foreach(println)
?
??? sc.stop()
? }
}
3.1.2?IDEA本地運行
先對該代碼進行編譯,然后運行該程序,需要注意的是在IDEA中需要在SparkConf添加setMaster("local")設置為本地運行。運行時可以通過運行窗口進行觀察:
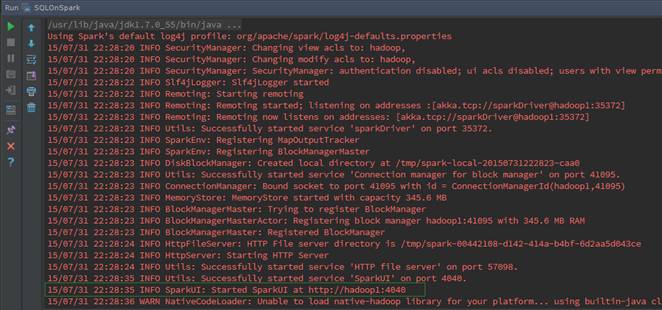
打印運行結果
3.1.3?生成打包文件
【注】可以參見第3課《Spark編程模型(下)--IDEA搭建及實戰》進行打包
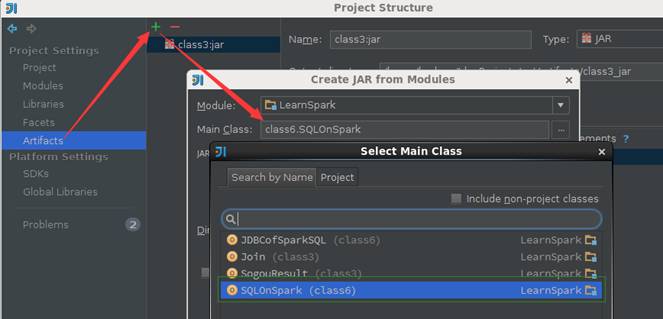
第一步?? 配置打包信息
在項目結構界面中選擇"Artifacts",在右邊操作界面選擇綠色"+"號,選擇添加JAR包的"From modules with dependencies"方式,出現如下界面,在該界面中選擇主函數入口為SQLOnSpark:
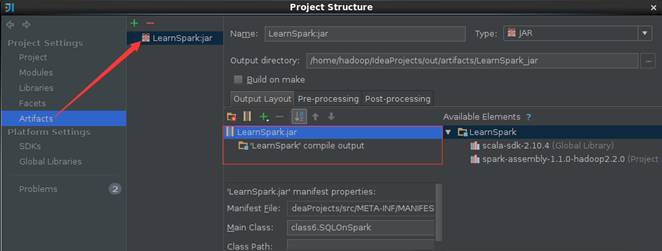
第二步?? 填寫該JAR包名稱和調整輸出內容
打包路徑為/home/hadoop/IdeaProjects/out/artifacts/LearnSpark_jar
【注意】的是默認情況下"Output Layout"會附帶Scala相關的類包,由于運行環境已經有Scala相關類包,所以在這里去除這些包只保留項目的輸出內容
第三步?? 輸出打包文件
點擊菜單Build->Build Artifacts,彈出選擇動作,選擇Build或者Rebuild動作
第四步?? 復制打包文件到Spark根目錄下
cd /home/hadoop/IdeaProjects/out/artifacts/LearnSpark_jar
cp LearnSpark.jar /app/hadoop/spark-1.1.0/
ll /app/hadoop/spark-1.1.0/
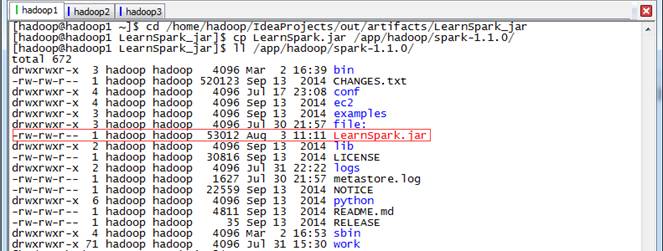
3.1.4?運行查看結果
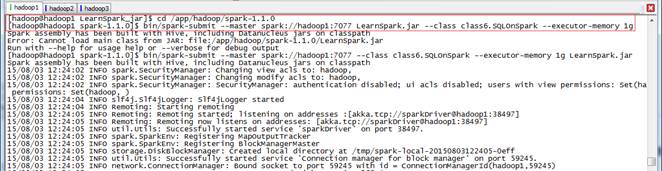
通過如下命令調用打包中的SQLOnSpark方法,運行結果如下:
cd /app/hadoop/spark-1.1.0
bin/spark-submit --master spark://hadoop1:7077 --class class6.SQLOnSpark --executor-memory 1g LearnSpark.jar
3.2?Hive On Spark
3.2.1?實現代碼
在class6包中添加HiveOnSpark對象文件,具體代碼如下:
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.sql.hive.HiveContext
?
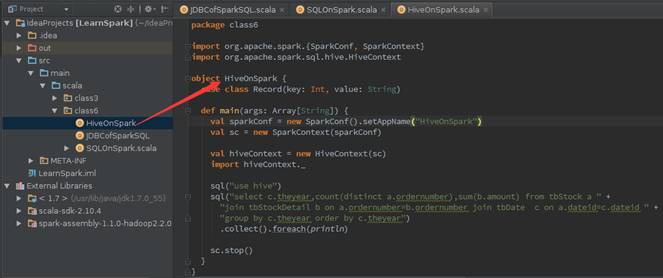
object HiveOnSpark {
? case class Record(key: Int, value: String)
?
? def main(args: Array[String]) {
??? val sparkConf = new SparkConf().setAppName("HiveOnSpark")
??? val sc = new SparkContext(sparkConf)
?
??? val hiveContext = new HiveContext(sc)
??? import hiveContext._
?
??? sql("use hive")
sql("select c.theyear,count(distinct a.ordernumber),sum(b.amount) from tbStock a join tbStockDetail b on a.ordernumber=b.ordernumber join tbDate ?c on a.dateid=c.dateid group by c.theyear order by c.theyear")
????? .collect().foreach(println)
?
??? sc.stop()
? }
}
3.2.2?生成打包文件
按照3.1.3SQL On Spark方法進行打包
3.2.3?運行查看結果
【注】需要啟動Hive服務,參見2.3.1
通過如下命令調用打包中的SQLOnSpark方法,運行結果如下:
cd /app/hadoop/spark-1.1.0
bin/spark-submit --master spark://hadoop1:7077 --class class6.HiveOnSpark --executor-memory 1g LearnSpark.jar

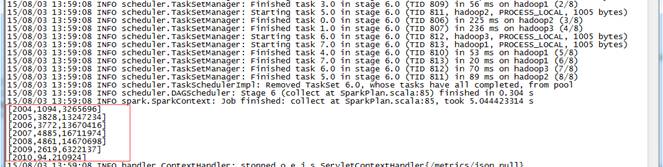
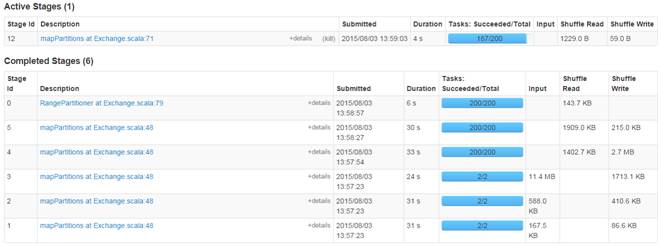
通過監控頁面看到名為HiveOnSpark的作業運行情況:

3.3?店鋪分類
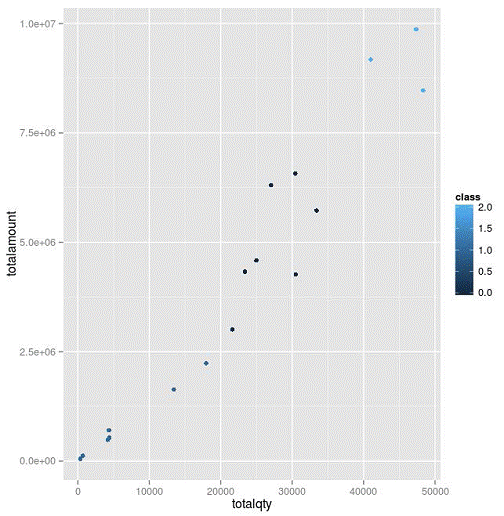
分類在實際應用中非常普遍,比如對客戶進行分類、對店鋪進行分類等等,對不同類別采取不同的策略,可以有效的降低企業的營運成本、增加收入。機器學習中的聚類就是一種根據不同的特征數據,結合用戶指定的類別數量,將數據分成幾個類的方法。下面舉個簡單的例子,按照銷售數量和銷售金額這兩個特征數據,進行聚類,分出3個等級的店鋪。
3.3.1?實現代碼
import org.apache.log4j.{Level, Logger}
import org.apache.spark.sql.catalyst.expressions.Row
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.sql.hive.HiveContext
import org.apache.spark.mllib.clustering.KMeans
import org.apache.spark.mllib.linalg.Vectors
?
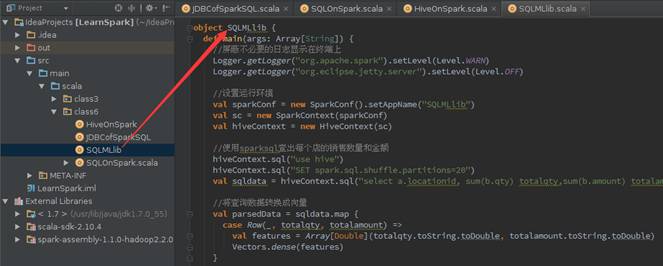
object SQLMLlib {
? def main(args: Array[String]) {
??? //屏蔽不必要的日志顯示在終端上
??? Logger.getLogger("org.apache.spark").setLevel(Level.WARN)
??? Logger.getLogger("org.eclipse.jetty.server").setLevel(Level.OFF)
?
??? //設置運行環境
??? val sparkConf = new SparkConf().setAppName("SQLMLlib")
??? val sc = new SparkContext(sparkConf)
??? val hiveContext = new HiveContext(sc)
?
??? //使用sparksql查出每個店的銷售數量和金額
??? hiveContext.sql("use hive")
??? hiveContext.sql("SET spark.sql.shuffle.partitions=20")
??? val sqldata = hiveContext.sql("select a.locationid, sum(b.qty) totalqty,sum(b.amount) totalamount from tbStock a join tbStockDetail b on a.ordernumber=b.ordernumber group by a.locationid")
?
??? //將查詢數據轉換成向量
??? val parsedData = sqldata.map {
????? case Row(_, totalqty, totalamount) =>
??????? val features = Array[Double](totalqty.toString.toDouble, totalamount.toString.toDouble)
??????? Vectors.dense(features)
??? }
?
??? //對數據集聚類,3個類,20次迭代,形成數據模型
??? //注意這里會使用設置的partition數20
??? val numClusters = 3
??? val numIterations = 20
??? val model = KMeans.train(parsedData, numClusters, numIterations)
?
??? //用模型對讀入的數據進行分類,并輸出
??? //由于partition沒設置,輸出為200個小文件,可以使用bin/hdfs dfs -getmerge 合并下載到本地
??? val result2 = sqldata.map {
????? case Row(locationid, totalqty, totalamount) =>
??????? val features = Array[Double](totalqty.toString.toDouble, totalamount.toString.toDouble)
??????? val linevectore = Vectors.dense(features)
??????? val prediction = model.predict(linevectore)
??????? locationid + " " + totalqty + " " + totalamount + " " + prediction
??? }.saveAsTextFile(args(0))
?
??? sc.stop()
? }
}
3.3.2?生成打包文件
按照3.1.3SQL On Spark方法進行打包
3.3.3?運行查看結果
通過如下命令調用打包中的SQLOnSpark方法:
cd /app/hadoop/spark-1.1.0
bin/spark-submit --master spark://hadoop1:7077 --class class6.SQLMLlib --executor-memory 1g LearnSpark.jar /class6/output1
運行過程,可以發現聚類過程都是使用20個partition:
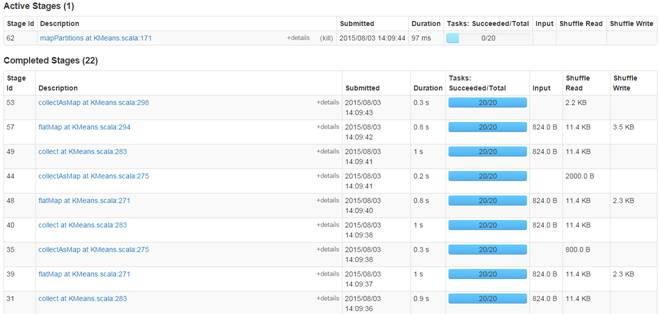
查看運行結果,分為20個文件存放在HDFS中
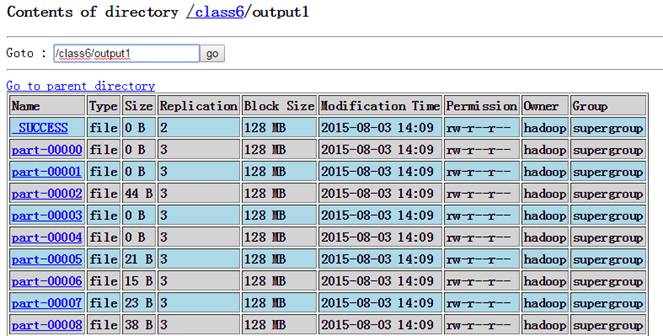
使用getmerge將結果轉到本地文件,并查看結果:
cd /home/hadoop/upload
hdfs dfs -getmerge /class6/output1 result.txt
最后使用R做示意圖,用3種不同的顏色表示不同的類別。從入門到實戰、
3.4?PageRank
PageRank,即網頁排名,又稱網頁級別、Google左側排名或佩奇排名,是Google創始人拉里·佩奇和謝爾蓋·布林于1997年構建早期的搜索系統原型時提出的鏈接分析算法。目前很多重要的鏈接分析算法都是在PageRank算法基礎上衍生出來的。PageRank是Google用于用來標識網頁的等級/重要性的一種方法,是Google用來衡量一個網站的好壞的唯一標準。在揉合了諸如Title標識和Keywords標識等所有其它因素之后,Google通過PageRank來調整結果,使那些更具“等級/重要性”的網頁在搜索結果中令網站排名獲得提升,從而提高搜索結果的相關性和質量。
Spark GraphX引入了google公司的圖處理引擎pregel,可以方便的實現PageRank的計算。c項目開發實戰入門?
3.4.1?創建表
下面實例采用的數據是wiki數據中含有Berkeley標題的網頁之間連接關系,數據為兩個文件:graphx-wiki-vertices.txt和graphx-wiki-edges.txt ,可以分別用于圖計算的頂點和邊。把這兩個文件上傳到本地文件系統/home/hadoop/upload/class6目錄中(注:這兩個文件可以從該系列附屬資源/data/class6中獲取)
第一步?? 上傳數據

第二步?? 啟動SparkSQL
參見第6課《SparkSQL(一)--SparkSQL簡介》3.2.3啟動SparkSQL
$cd /app/hadoop/spark-1.1.0
$bin/spark-sql --master spark://hadoop1:7077 --executor-memory 1g

第三步?? 定義表并加載數據
創建vertices和edges兩個表并加載數據:
spark-sql>show databases;
spark-sql>use hive;
spark-sql>CREATE TABLE vertices(ID BigInt,Title String) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' LINES TERMINATED BY '\n'; LOAD DATA LOCAL INPATH '/home/hadoop/upload/class6/graphx-wiki-vertices.txt' INTO TABLE vertices;
spark-sql>CREATE TABLE edges(SRCID BigInt,DISTID BigInt) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' LINES TERMINATED BY '\n'; LOAD DATA LOCAL INPATH '/home/hadoop/upload/class6/graphx-wiki-edges.txt' INTO TABLE edges;
查看創建結果
spark-sql>show tables;

3.4.2?實現代碼
import org.apache.log4j.{Level, Logger}
import org.apache.spark.sql.hive.HiveContext
import org.apache.spark.{SparkContext, SparkConf}
import org.apache.spark.graphx._
import org.apache.spark.sql.catalyst.expressions.Row
?
object SQLGraphX {
? def main(args: Array[String]) {
??? //屏蔽日志
??? Logger.getLogger("org.apache.spark").setLevel(Level.WARN)
??? Logger.getLogger("org.eclipse.jetty.server").setLevel(Level.OFF)
?
??? //設置運行環境
??? val sparkConf = new SparkConf().setAppName("PageRank")
??? val sc = new SparkContext(sparkConf)
??? val hiveContext = new HiveContext(sc)
?
??? //使用sparksql查出每個店的銷售數量和金額
??? hiveContext.sql("use hive")
?? ?val verticesdata = hiveContext.sql("select id, title from vertices")
??? val edgesdata = hiveContext.sql("select srcid,distid from edges")
?
??? //裝載頂點和邊
??? val vertices = verticesdata.map { case Row(id, title) => (id.toString.toLong, title.toString)}
?? ?val edges = edgesdata.map { case Row(srcid, distid) => Edge(srcid.toString.toLong, distid.toString.toLong, 0)}
?
??? //構建圖
??? val graph = Graph(vertices, edges, "").persist()
?
??? //pageRank算法里面的時候使用了cache(),故前面persist的時候只能使用MEMORY_ONLY
??? println("**********************************************************")
??? println("PageRank計算,獲取最有價值的數據")
??? println("**********************************************************")
??? val prGraph = graph.pageRank(0.001).cache()
?
??? val titleAndPrGraph = graph.outerJoinVertices(prGraph.vertices) {
????? (v, title, rank) => (rank.getOrElse(0.0), title)
??? }
?
??? titleAndPrGraph.vertices.top(10) {
????? Ordering.by((entry: (VertexId, (Double, String))) => entry._2._1)
??? }.foreach(t => println(t._2._2 + ": " + t._2._1))
?
??? sc.stop()
? }
}
3.4.3?生成打包文件
按照3.1.3SQL On Spark方法進行打包
3.4.4?運行查看結果
通過如下命令調用打包中的SQLOnSpark方法:
cd /app/hadoop/spark-1.1.0
bin/spark-submit --master spark://hadoop1:7077 --class class6.SQLGraphX --executor-memory 1g LearnSpark.jar

運行結果:
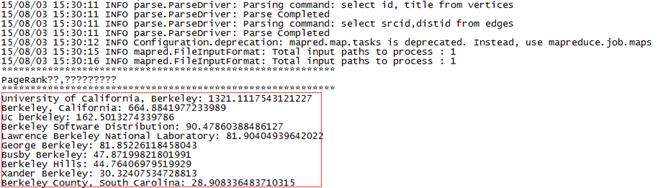
3.5?小結
在現實數據處理過程中,這種涉及多個系統處理的場景很多。通常各個系統之間的數據通過磁盤落地再交給下一個處理系統進行處理。對于Spark來說,通過多個組件的配合,可以以流水線的方式來處理數據。從上面的代碼可以看出,程序除了最后有磁盤落地外,都是在內存中計算的。JAVA從入門到、避免了多個系統中交互數據的落地過程,提高了效率。這才是spark生態系統真正強大之處:One stack rule them all。另外sparkSQL+sparkStreaming可以架構當前非常熱門的Lambda架構體系,為CEP提供解決方案。也正是如此強大,才吸引了廣大開源愛好者的目光,促進了Spark生態的高速發展。

![Cisco IOS Unicast NAT 工作原理 [一]](http://blog.51cto.com/attachment/201009/201009301285776510901.jpg)