1.硬盤的基礎知識
? ? 1.1 分區的概念:
? ? 分區從實質上說就是對硬盤的一種格式化。當我們創建分區時,就已經設置好了硬盤的各項物理參數,指定了硬盤主引導記錄(即 MasterBootRecord,一般簡稱為 MBR)和引導記錄備份的存放位置。而對于文件系統以及其他操作系統管理硬盤所需要的信息則是通過以后的高級格式化,即 Format 命令來實現。面、磁道和扇區硬盤分區后,將會被劃分為面(Side)、磁道(Track)和扇區(Sector)。需要注意的是,這些只是個虛擬的概念,并不是真正在硬盤上劃軌道。?
? ? 1.2 MBR簡介:
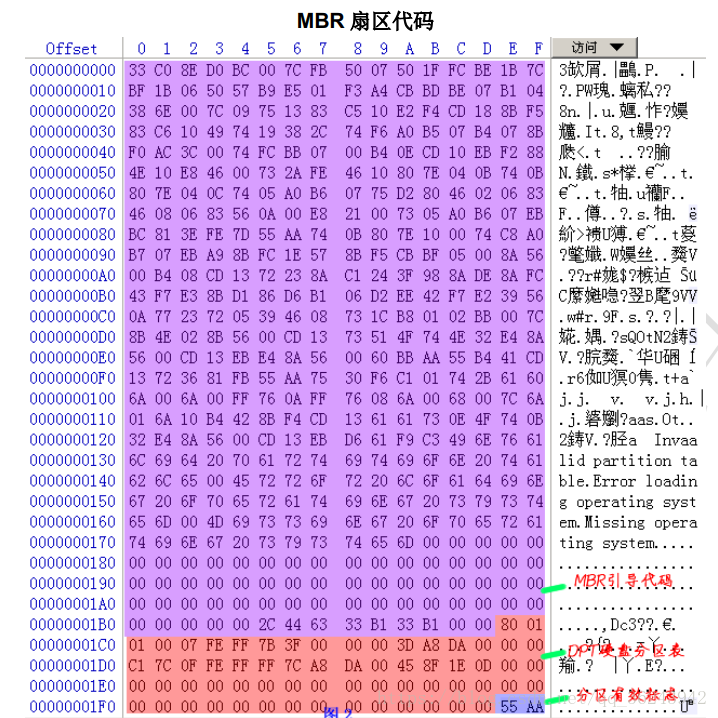
? ? MBR(Main Boot Record 主引記錄)位于整個硬盤的 0 磁道 0 柱面 1 扇區。不過,在總共 512 字節的主引導扇區中, MBR 只占用了其中的 446 個字節,另外的 64 個字節交給了DPT(Disk Partition Table 硬盤分區表),最后兩個字節“55, AA”是分區的結束標志。這個整體構成了硬盤的主引導扇區。
磁盤的文件系統結構已損壞?? ? 1.3 分區的原理:
? ? 主引導記錄由三部分組成:一部分是 446byte 的操作系統引導代碼(MBR),還有一部分是 64byte 的主分區表(DPT)。主分區表最多記錄四個主分區的分區信息.每個分區占用 16byte。分區就是修改分區表,它不影響硬盤上的存儲的數據。最后的 2 字節是結束標志。
? ? 擴展技術:需要將一塊硬盤分成更多的分區,超過 5 個以上的分區,可以將最多四個主分區中的一個分區類型改為擴展分區,然后在擴展分區中再建邏輯分區。邏輯分區的分區信息保存在擴展分區之中,叫做擴展分區表。理論上邏輯分區沒有個數的限制。擴展分區不能被直接使用,必須將其劃分為若干個邏輯分區。邏輯分區的起始位置的信息都寫在擴展分區表里面。邏輯分區的分區編號從 5 開始,如: /dev/hda5 是第一塊硬盤的第一個邏輯分區。
?
? ? 1.4 格式化原理:
LINUX和WINDOWS的區別、? ? 分好區的硬盤分區上面什么數據也沒有,操作系統也不能讀寫,為了讓操作系統能夠識別必須向分區中預寫入一定格式的數據。這個過程就稱之為格式化。在 Linux 中稱為創建文件系統。沒有分區的硬盤是不能格式化的,沒有格式化的分區是不能直接被使用的。所以分區和格式化往往都是同時進行的。
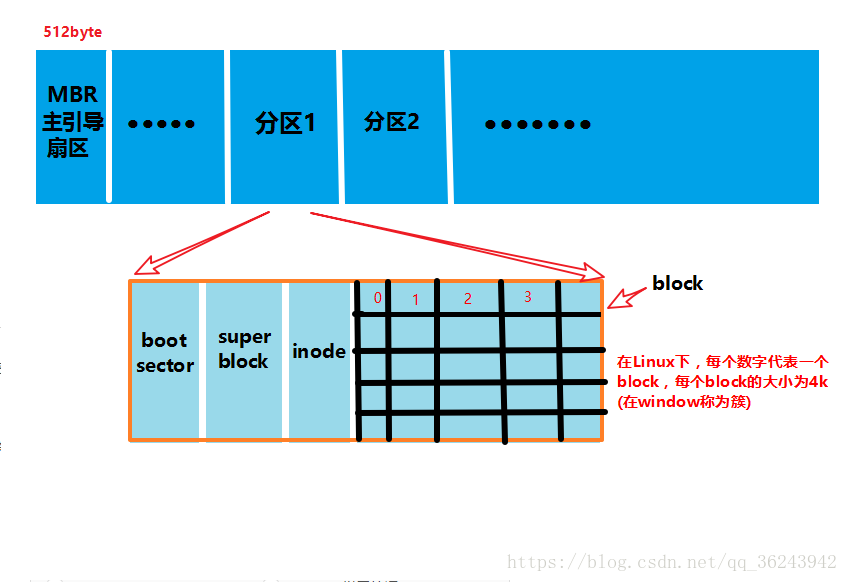
? ? 現在我們已經大概知道了一個硬盤的結構,當我們新買來一塊硬盤時,必須經過分區和格式化才能進行使用,下面用簡圖表示一下一個硬盤的結構:
- superblock:記錄此 filesystem?的整體信息,包括 inode/block? 的總量、使用量、剩余量, 以及文件系統的格式與相關信息等。
- inode:記錄文件的屬性,一個文件占用一個 inode,同時記錄此文件的數據所在的 block 號碼。
- block:實際記錄文件的內容,若文件太大時,會占用多個 block。
注意:
1.inode?與?block 都有編號,而每個文件都會占用一個 inode ,inode 內則有文件數據放置的block 號碼,如果能找到文件的inode?就可以找到文件。
2.在inode記錄一個文件需要128字節大小的內存。
ubuntu磁盤管理、?
2.Linux的EXT2文件系統(inode)
為什么需要使用EXT2文件系統?
如果我的文件系統高達數百 GB 時, 那么將所有的 inode?與?block 通通放置在一起將是不理智的決定,因為 inode 與 block 的數量太龐大,不容易管理。因此 Ext2 文件系統在格式化的時候基本上是區分為多個區塊群組 (block group)?的,每個區塊群組都有獨立的 inode/block/superblock 系統。
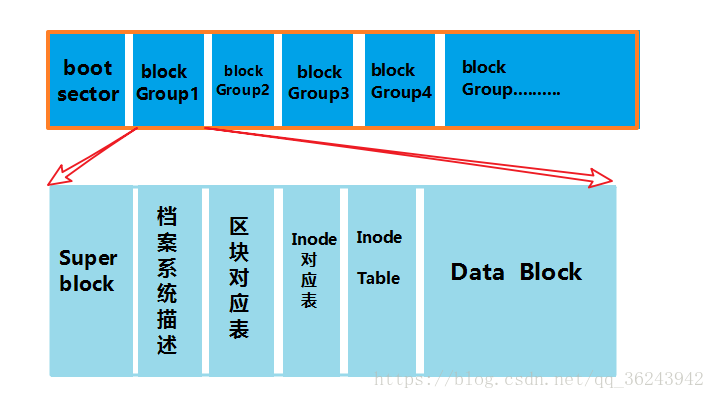
?
centos 磁盤管理、 在整體的劃劃當中,文件系統前面有一個啟動扇區(boot sector),這個啟動扇區可以安裝開機管理程序, 這是個非常重要的設計,因為如此一來我們就能夠將不同的開機管理程序安裝到個別的文件系統最前端,而不用覆蓋整塊硬盤唯一的MBR, 這樣也能夠制作出多重引導的環境。至于每一個區塊群組(block group)的六個主要內容說明如下:
Data Block:用來放置檔案內容數據地方,在 Ext2 文件系統中所支持的 block 大小有 1K, 2K 及 4K三種而已。在格式化時 block?的大小就固定了,且每個 block 都有編號,以方便 inode的記錄。
Inode Table:主要記錄文件的屬性以及該文件實際數據放置的block號。

?
Superblock (超級區塊):Superblock(大小為1024byte)是記錄整個 filesystem 相關信息的地方,它記錄的信息有如下:
- block與inode的總量
- 未使用和已經使用的inode/block的數量
- block 和 inode 的大小(inode?固定為128byte,block可選,1k,2k,4k)
- 記錄最近文件系統創建時間,操作時間的詳細信息
- 記錄此文件系統書否被掛載,vaild bit數值為1表示未掛載,0表示掛載。
磁盤分區文件系統類型?Filesystem Description (檔案系統描述說明)
- 記錄每個block group從開始到結束的block的號碼
- 說明每個區段 (superblock,bitmap, inodemap, data block) 分別位于哪一個 block 號碼之間
Block Bitmap (區塊對照表):
- 就像是一張表記錄的是,使用和未使用的block,以便系統調用,如果一個檔案刪除,它所占的block的區對照表也會被清除,這樣block就會空出來。
Inode Bitmap (inode 對照表):
- 記錄使用和未使用的inode號碼。
3.與目錄樹的關系
每一個文件(不管是一般文件還是目錄文件)都會占用一個inode,目錄的內容記錄文件名,一般文件記錄實際數據內容。目錄與文件在文件系統中如何記錄數據呢?
- 目錄:Linux 下的文件系統建立一個目錄時,文件系統會分配一個 inode 與至少一塊 block 給該目錄。其中,inode 記錄該目錄的相關權限與屬性,并可記錄分配到的 block 號碼; 而 block 則是記錄在這個目錄下的文件名與該文件名占用的 inode 號碼數據。?
? ? ? ? ? ? ? ? ?使用 ls -li 命令查看文件的inode 號碼
磁盤和文件系統管理。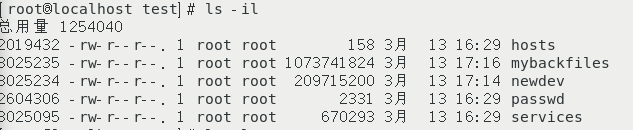
?
- 文件:在 Linux 下的 ext2 建立一個一般文件時, ext2 會分配一個 inode 與相對于該文件大小的 block 數量給該文件。
- 目錄樹讀取:inode 本身并不記錄文件名,文件名的記錄是在目錄的 block 當中,所以 新增/刪除/更名文件名與目錄的 w 權限有關。 當我們要讀取某個文件時,就務必會經過目錄的 inode 和 block,然后才能夠找到那個待讀取文件的 inode 號碼,最終才會讀到正確的文件的 block 內的數據。由于目錄樹是由根目錄開始讀起,因此系統透過掛載的信息可以找到掛載點的 inode 號碼,此時就能夠得到根目錄的 inode 內容,并依據該 inode 讀取根目錄的 block 內的文件名數據,再一層一層的往下讀到正確的文件名。

讀取 /etc/passed 文件的流程:?
- / 的 inode 號碼:通過掛載點信息找到根目錄 inode號碼(64),且 inode 具有的權限讓我們可以讀取該block的內容(r與x);
- / 的 block 號碼:經過上述步驟取得 block 號碼,并找到該內容中 etc/ 目錄的 inode 號碼(6777281);
- etc/ 的 inode 號碼:讀取 6777281 號 inode 得知具有 r 與 x 的權限,因此可以讀取 etc/ 的 block 內容;
- etc/ 的 block 號碼:經過上個步驟取得 block 號碼,并找到該內容有 passwd 文件的 inode 號碼(7931015);
- passwd 的 inode 號碼:讀取 7931015 號 inode 得知具有 r 的權限,因此可以讀取 passed 的block 內容;
- passwd 的 block 號碼: 最后將該 block 內容的數據讀出來。
4. EXT2/EXT3/EXT4 文件的存取與日志式文件系統的功能
新建一個文件時,文件系統的行為是:
- 先確定用戶對于欲增文件的目錄是否具有 w 和 x 權限,若有才能新增
- 根據 inode bitmap 找到沒有使用的idode 號碼,并將新文件的權限、屬性寫入
- 根據 block bitmap 找到沒有使用中的 block 號碼,并將實際的數據寫入 block 中,且更新 inode 的 block 指向數據
- 將剛剛寫入的 inode 與 block 數據同步更新 inode bitmap 與 block bitmap,并更新 superblock 的內容?
inode table 與 data block 稱為數據存放區域,superblock、 block bitmap 與 inode bitmap 等區段就被稱為 metadata (中間數據) ,因為 superblock, inode bitmap 及 block bitmap 的數據是經常變動的,每次新增、移除、編輯時都可能會影響到這三個部分的數據,因此才被稱為中間數據。
linux用哪種文件系統。 數據的不一致 (Inconsistent) 狀態
文件在寫入文件系統時,因為不知名原因導致系統中斷(例如突然的停電、 系統核心發生錯誤發生時),所以寫入的數據僅有 inode table 及 data block,最后一個同步更新中間數據的步驟并沒有做完,此時就會發生 metadata 的內容與實際數據存放區產生不一致 (Inconsistent) 的情況。?
在早期的 Ext2 文件系統中,如果發生這個問題, 那么系統在重新啟動的時候,就會由 Superblock 當中記錄的 valid bit (是否有掛載) 與 filesystem state (clean 與否) 等狀態來判斷是否強制進行數據一致性的檢查,檢查整個磁盤,耗時長,于是出現了日志式文件系統。
日志式文件系統 (Journaling filesystem)
在filesystem 當中規劃出一個區塊,該區塊專門在記錄寫入或修訂文件時的步驟:
- 預備:當系統要寫入一個文件時,會先在日志記錄區塊中紀錄某個文件準備要寫入的信息
- 實際寫入:開始寫入文件的權限與數據;開始更新 metadata 的數據
- 結束:完成數據與 metadata 的更新后,在日志記錄區塊當中完成該文件的紀錄
5. Linux 文件系統的運作
常用磁盤文件系統, 由于磁盤寫入的速度要比內存慢很多,在編輯保存文件時效率較低,為了解決這個問題Linux使用異步處理 (asynchronously) :當系統加載一個文件到內存后,如果該文件沒有被動過,則在內存區段的文件數據會被設定為干凈 (clean)的。 但如果內存中的文件數據被更改過了(例如你用 nano 去編輯過這個文件),此時該內存中 的數據會被設定為臟的 (Dirty)此時所有的動作都還在內存中執行,并沒有寫入到磁盤中! 系統會不定時的將內存中設定為『Dirty』的數據寫回磁盤,以保持磁盤與內存數據的一致性。 也可以使用sync 指令來動寫入磁盤。
- 系統會將常用的文件數據放置到主存儲器的緩沖區,以加速文件系統的讀/寫,因此 Linux 的物理內存最后都會被用光!這是正常的情況!可加速系統效能
- 可以手動使用 sync 來強迫內存中設定為 Dirty 的文件回寫到磁盤中
- 若正常關機時,關機指令會主動呼叫 sync 來將內存的數據回寫入磁盤,若不正常關機(如跳電、當機或其他不明原因),由于數據尚未回寫到磁盤內, 因此重新啟動后可能會花 很多時間在進行磁盤檢驗,甚至可能導致文件系統的損毀(非磁盤損毀)
6. 掛載點的意義 (mount point)
每個 filesystem 都有獨立的 inode / block / superblock 等信息,這個文件系統要能夠鏈接到目錄樹才能被我們使用。 將文件系統與目錄樹結合的動作我們稱為掛載。掛載點一定是目錄,該目錄為進入該文件系統的入口。
原文地址:
https://blog.csdn.net/qq_36243942/article/details/82820056