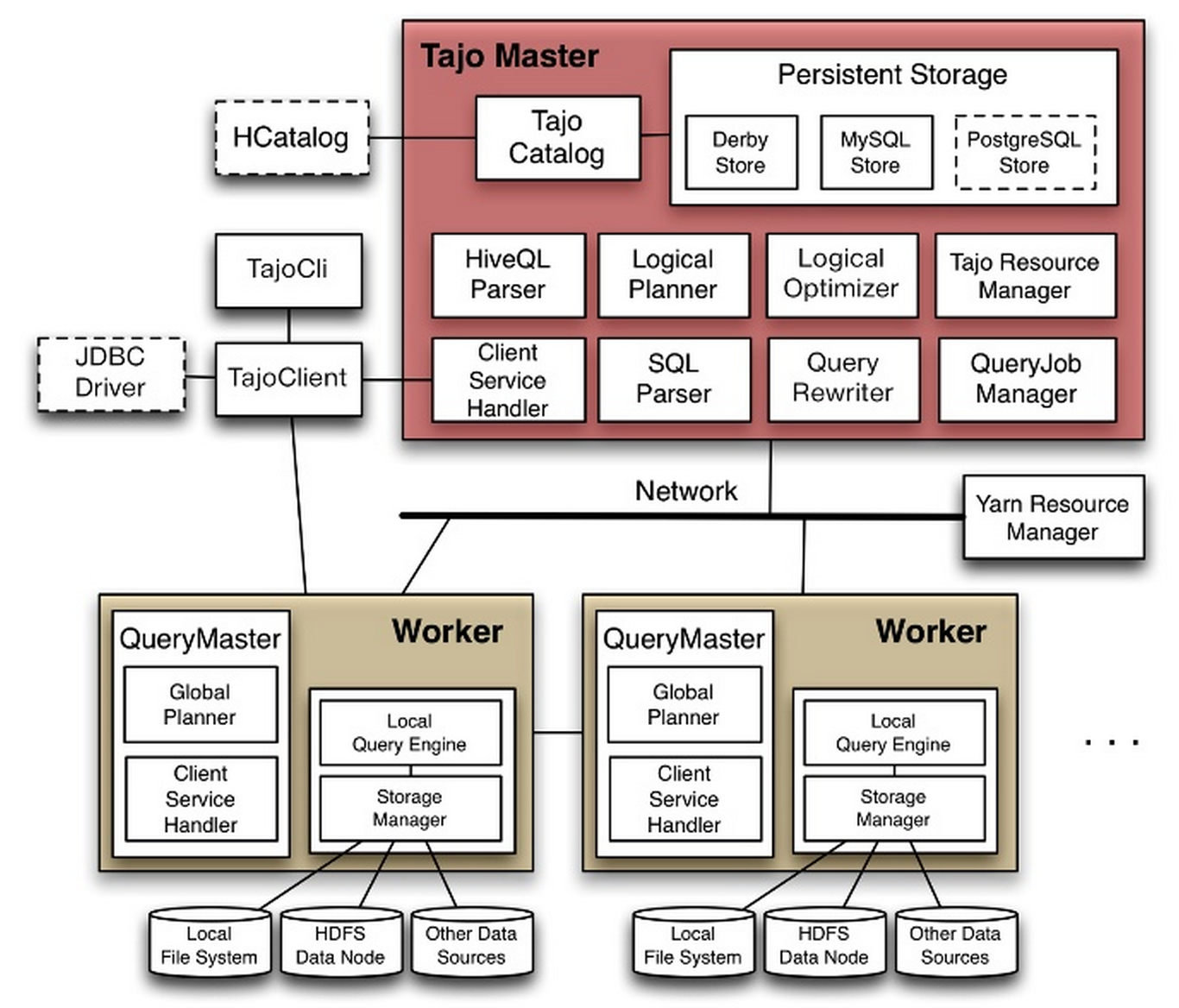
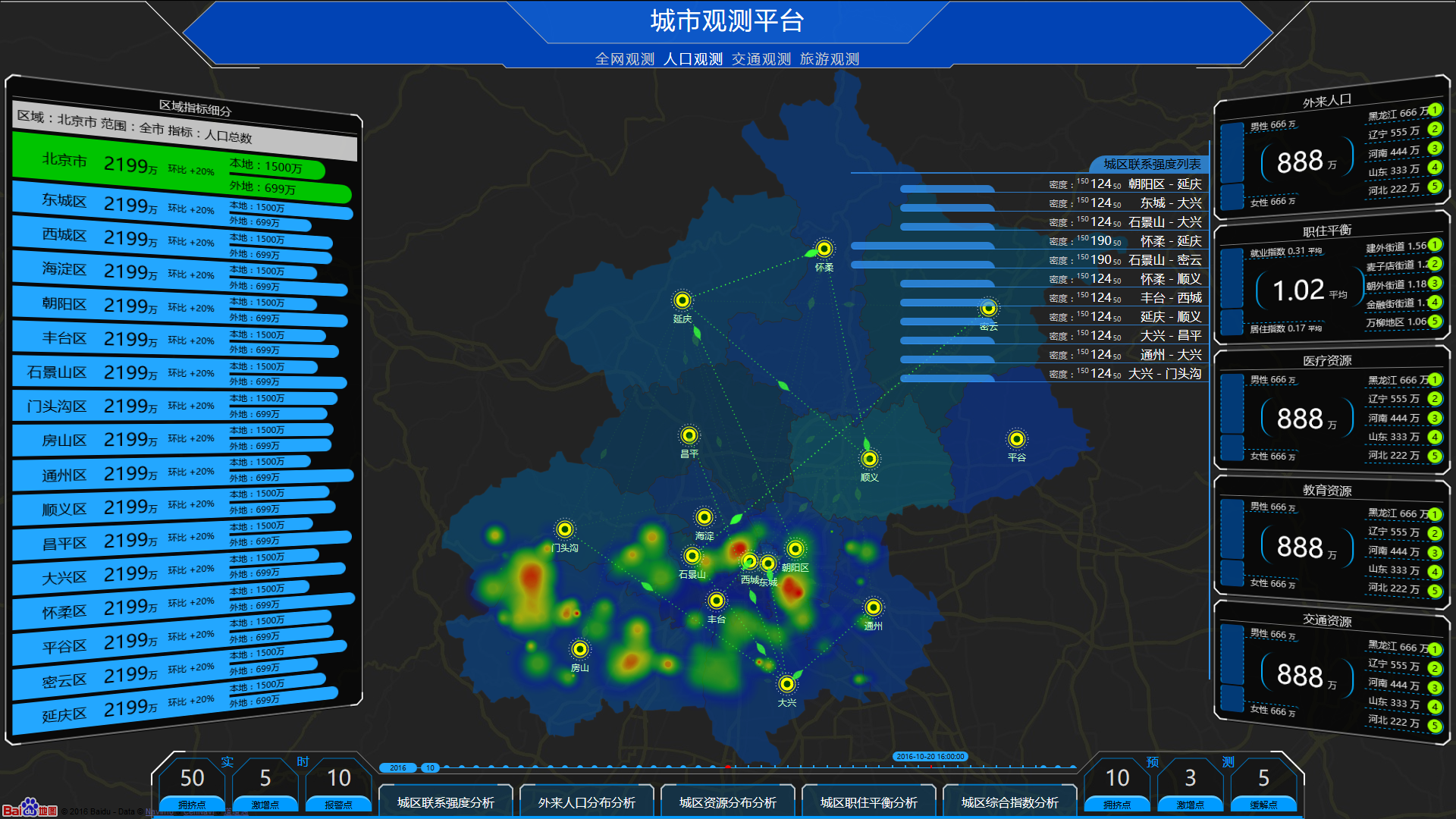
spark.read.load是加載數據的通用方法
對不同格式文件采用不同的format方式SparkSQL的默認數據源為Parquet格式,Parquet是一種能夠有效存儲嵌套數據的列示存儲格式。
hbase是海量數據的存儲方式,對于統計分析是非常便利的
數據源是Parquet的時候,SparkSQL可以方便的執行所有的操作,不需要使用format。修改配置項spark.sql.sources.default,可以修改默認數據源格式
版权声明:本站所有资料均为网友推荐收集整理而来,仅供学习和研究交流使用。

工作时间:8:00-18:00
客服电话
电子邮件
admin@qq.com
扫码二维码
获取最新动态