数据访问顺序:根结点------->左孩子------->又孩子
使用了分治法:将一个大树向下一层层的分为多个小子树
/*** 先序遍历,使用递归,输出树中所有结点* @param rootNode 根结点*/public static void preOrder(TreeNode rootNode) {TreeNode moveNode = rootNode;if(moveNode != null) {System.out.print(moveNode.getData()+" ");preOrder(moveNode.getLeChild());preOrder(moveNode.getRiChild());}}
利用栈的特性:对每个小子树的根结点进行存储,使得访问左子树后,右子树的追踪不会丢失
数据在入栈时进行访问
/*** 使用栈来进行先序遍历* @param rootNode 根结点*/public static void stackPreOrder(TreeNode rootNode) {TreeNode moveNode = rootNode;//构造长度为10的栈TreeNode[] stack = new TreeNode[10];int i = 0;//栈不为空且还有数据while(moveNode != null || i != 0) {while(moveNode != null) {//遍历左子树入栈stack[i++] = moveNode;System.out.print(moveNode.getData()+" ");moveNode = moveNode.getLeChild();}while((moveNode = stack[--i].getRiChild()) == null) {if(i == 0) {//当栈空,还没有右子树,遍历结束return;}}} }
PS:在这里我使用循环嵌套,可能美观性有点不太好,但易于理解
数据访问顺序:左孩子------->根结点------->右孩子
二叉树的非递归遍历?大致和先序遍历相同
/*** 中序遍历,使用递归* @param rootNode 根结点*/public static void inOrder(TreeNode rootNode) {TreeNode moveNode = rootNode;if(moveNode != null) {inOrder(moveNode.getLeChild());System.out.print(moveNode.getData()+" ");inOrder(moveNode.getRiChild());}}
数据的输出位置发生变化,即在出栈位置进行访问
/*** 使用栈完成中序遍历* @param rootNode 根结点*/public static void stackInOrder(TreeNode rootNode) {TreeNode moveNode = rootNode;TreeNode[] stack = new TreeNode[10];int i = 0;//栈不为空,且还有数据while(moveNode != null || i != 0) {while(moveNode != null) {//遍历左子树入栈stack[i++] = moveNode;moveNode = moveNode.getLeChild();}//循环出栈,找出右子树未空的结点while((moveNode = stack[--i].getRiChild()) == null) {//若无右子树,直接输出当前结点值System.out.print(stack[i].getData()+" ");if(i == 0) {//当栈空,还没有右子树,遍历结束return;}}//输出有右子树的结点值System.out.print(stack[i].getData()+" ");}}
数据访问顺序:左孩子------->右孩子------->根结点
大致和先序遍历相同
/*** 后序遍历,使用递归* @param rootNode 根结点*/public static void postOrder(TreeNode rootNode) {TreeNode moveNode = rootNode;if(moveNode != null) {postOrder(moveNode.getLeChild());postOrder(moveNode.getRiChild());System.out.print(moveNode.getData()+" ");}}
由于后续遍历的特殊性,若子树根结点有右子树,则需先遍历子树的右子树,再输出子树根结点,此处需要对根结点进行二次访问(第一次得到右子树的入口,第二次访问数据)。若根结点直接出栈,会导致追踪丢失,因此设一个标记对子树根结点进行判断。
判断内容:是否为第一次访问
/*** 借用栈完成后序遍历* @param rootNode 根结点*/public static void stackPostOrder(TreeNode rootNode) {TreeNode moveNode = rootNode;//构造长度为10的栈TreeNode[] stack = new TreeNode[20];//设置标记数组,和栈同步操作,0为入栈,1为遇到一次int[] mark = new int[20];int i = 0;int j = 0;//将根归栈 //栈不为空时while(moveNode != null || i != 0) {if(moveNode != null) {stack[i++] = moveNode;mark[j++] = 0;moveNode = moveNode.getLeChild();}else {//无右子树,直接输出if(stack[i-1].getRiChild() == null) { System.out.print(stack[--i].getData()+" ");j--;moveNode = null;}else if(stack[i-1].getRiChild() != null && mark[j-1] != 1) {//若即将出栈结点有右子树且标记为0时,则不出栈只取值moveNode = stack[i-1].getRiChild();mark[i-1] = 1; //修改标记}else if(stack[i-1].getRiChild() != null && mark[j-1] == 1) {//在遍历完右子树之后,出栈,直接输出System.out.println(stack[--i]+" ");j--;moveNode = null;}}}}
PS:此处只使用了一个主循环,之前的遍历也可统一为一个主循环
栈中序非递归、测试树:

测试调用:
System.out.print("使用递归的先序遍历:");preOrder(rootNode);System.out.print("\r\n"+"使用递归的中序遍历:");inOrder(rootNode);System.out.print("\r\n"+"使用递归的后序遍历:");postOrder(rootNode);System.out.print("\r\n"+"使用栈的先序遍历:");stackPreOrder(rootNode);System.out.print("\r\n"+"使用栈的中序遍历:");stackInOrder(rootNode); System.out.print("\r\n"+"使用栈的后序遍历:");postOrder(rootNode);
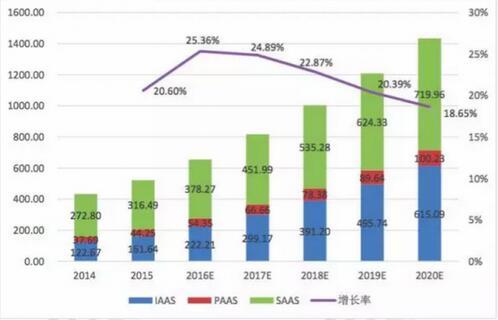
测试结果:
版权声明:本站所有资料均为网友推荐收集整理而来,仅供学习和研究交流使用。

工作时间:8:00-18:00
客服电话
电子邮件
admin@qq.com
扫码二维码
获取最新动态

![[vijos1162]波浪数](https://images.cnblogs.com/OutliningIndicators/ContractedBlock.gif)


![[转]Oracle修改监听口令](/upload/rand_pic/2-1144.jpg)