分享一下我老师大神的人工智能教程!零基础,通俗易懂!http://blog.csdn.net/jiangjunshow
也欢迎大家转载本篇文章。分享知识,造福人民,实现我们中华民族伟大复兴!
这里重点介绍几个目录bin、conf及lib目录。
从入门到进阶,文件名称 | 说明 |
hadoop | 用于执行hadoop脚本命令,被hadoop-daemon.sh调用执行,也可以单独执行,一切命令的核心 |
hadoop-config.sh | Hadoop的配置文件 |
房屋入门步步高、hadoop-daemon.sh | 通过执行hadoop命令来启动/停止一个守护进程(daemon)。 该命令会被bin目录下面所有以“start”或“stop”开头的所有命令调用来执行命令,hadoop-daemons.sh也是通过调用hadoop-daemon.sh来执行优命令的,而hadoop-daemon.sh本身由是通过调用hadoop命令来执行任务。 |
hadoop-daemons.sh | 通过执行hadoop命令来启动/停止多个守护进程(daemons),它也是调用hadoop-daemon.sh来完成的。 |
rcc | fluent入门与进阶教程?The Hadoop record compiler |
slaves.sh | 该命令用于向所有的slave机器上发送执行命令 |
start-all.sh | 全部启动,它会调用start-dfs.sh及start-mapred.sh |
start-balancer.sh | 进阶版。启动balancer |
start-dfs.sh | 启动Namenode、Datanode及SecondaryNamenode |
start-jobhistoryserver.sh | 启动Hadoop任务历史守护线程,在需要执行历史服务的机器上执行该命令。 原文: 进入hadoop目录命令?Start hadoop job history daemons. Run this on node where history server need to run |
start-mapred.sh | 启动MapReduce |
stop-all.sh | 全部停止,它会调用stop-dfs.sh及stop-mapred.sh |
stop-balancer.sh | hadoop进入目录、停止balancer |
stop-dfs.sh | 停止Namenode、Datanode及SecondaryNamenode |
stop-jobhistoryserver.sh | 停止Hadoop任务历史守护线程 |
stop-mapred.sh | hadoop入门基础,停止MapReduce |
task-controller | 任务控制器,这不是一个文本文件,没有被bin下面的shell调用 |
文件名称 | 说明 |
hadoop零基础入门。capacity-scheduler.xml |
|
configuration.xsl |
|
core-site.xml | Hadoop核心全局配置文件,可以其它配置文件中引用该文件中定义的属性,如在hdfs-site.xml及mapred-site.xml中会引用该文件的属性。 hadoop权威指南第5版、该文件的模板文件存在于$HADOOP_HOME/src/core/core-default.xml,可将模板文件拷贝到conf目录,再进行修改。 |
fair-scheduler.xml |
|
hadoop-env.sh | Hadoop环境变量 |
hadoop-metrics2.properties | go语言从入门到进阶实战。 |
hadoop-policy.xml |
|
hdfs-site.xml | HDFS配置文件,该模板的属性继承于core-site.xml。 该文件的模板文件存在于$HADOOP_HOME/src/hdfs/hdfs-default.xml,可将模板文件拷贝到conf目录,再进行修改。 |
怎么进hadoop目录。log4j.properties | Log4j的日志属于文件 |
mapred-queue-acls.xml | MapReduce的队列 |
mapred-site.xml | MapReduce的配置文件,该模板的属性继承于core-site.xml。 hadoop返回上一级目录、该文件的模板文件存在于$HADOOP_HOME/src/mapred/mapredd-default.xml,可将模板文件拷贝到conf目录,再进行修改。 |
masters | 用于设置所有secondaryNameNode的名称或IP,每一行存放一个。如果是名称,那么设置的secondaryNameNode名称必须在/etc/hosts有ip映射配置。 |
slaves | 用于设置所有slave的名称或IP,每一行存放一个。如果是名称,那么设置的slave名称必须在/etc/hosts有ip映射配置。 |
ssl-client.xml.example | hadoop菜鸟入门、 |
ssl-server.xml.example |
|
taskcontroller.cfg |
|
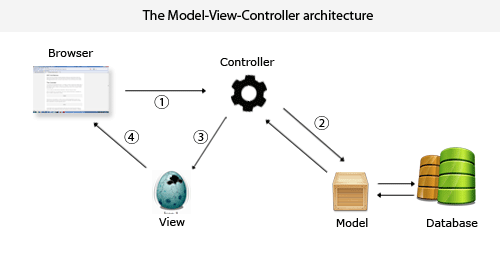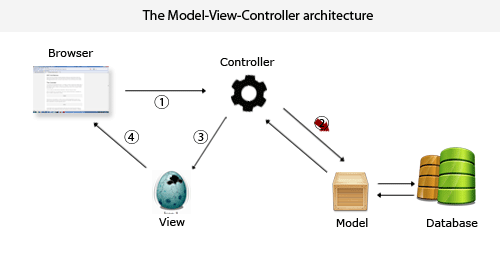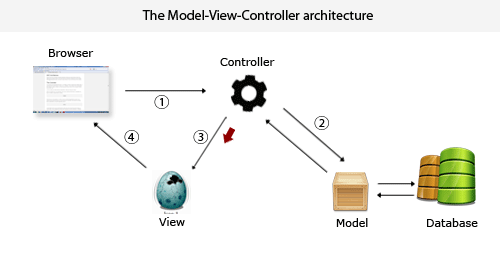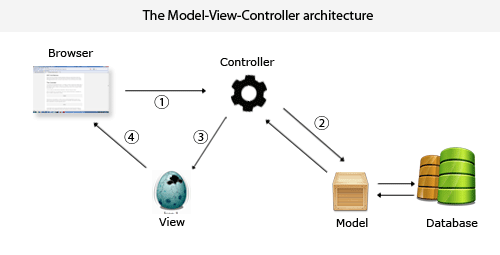
task-log4j.properties | Hadoop1.0的架构图? |
存放的是Hadoop运行时依赖的的jar包,Hadoop在执行的时候会把lib目录下面的jar全部加到classpath中。如果不想通过HADOOP_CLASSPATH指定自己的JAR文件所在路径,可以把计算需要用的jar全部都拷贝到lib目录中。

版权声明:本站所有资料均为网友推荐收集整理而来,仅供学习和研究交流使用。

工作时间:8:00-18:00
客服电话
电子邮件
admin@qq.com
扫码二维码
获取最新动态