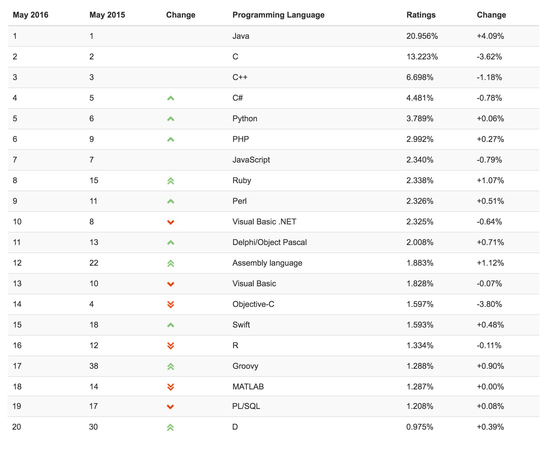
1 . 传统单机服务
概念 : 所有的功能模块全部写在一起 , 打到一个war包里进行发布 , 除了容器(Tomcat等)以外基本没有其他依赖 . 它的结构图如下 :

单机服务中 , 一个模块包含了UI展示/业务处理/数据交互等所有的内容 . 它主要适用于初创团队或规模不大的公司进行的中小项目 . 主要有以下优势 :
- 开发简单直接 , 单个项目集中式管理
- 所有的功能业务都在一块 , 基本不会有重复作业
- 功能都在一台服务器上 , 没有分布式的管理和调用开销
相对而言 , 它的缺点也很明显 . 尤其是对项目达到一定规模 , 或是当前互联网公司要求的敏捷开发情境中 .
- 开发效率低 ; 所有开发人员都在一个项目上作业 , 提交代码相互等待 , 代码冲突频繁
- 代码维护难 ; 代码模块全都耦合在一起 , 新人不知道何从下手
- 部署不灵活 ; 构建时间长 , 任何小修改都必须重新构建整个项目 , 相对应的时长增加
- 稳定性不佳 ; 任何模块的一个状况(死锁/死循环/内存泄露等) , 就可能导致整个应用挂掉
- 扩展性不足 ; 无法满足高并发情况下的定制需求(例如单独扩展某个模块的话 , 就很难实现)
2 . 微服务
微服务架构一般迭代速度比较慢?为了解决单机服务中存在的上述种种问题 , 微服务的架构就应运而生了 . 首先来看一下微服务的架构图 :

简单来讲 , 微服务就是将应用进行有效的拆分 , 实现敏捷开发和部署
微服务的优势 :
- 便于开发 , 降低复杂度 ; 各个团队分别维护各自服务 , 不会出现等待的无用功间隙 ; 并且新人接手的时候 , 不必再学习整个项目的业务代码 , 只需关注所负责的模块即可
- 代码解耦 ; 各个服务间通过协议通信 , 代码没有强耦合性 , 互不干扰
- 独立部署 ; 每个模块都可以作为一个服务单独部署 , 所以在上线新功能时 , 只需要发布相应的模块即可 . 减少了测试的工作量 , 也降低了服务发布的风险(单机服务下 , 新增需求可能就得把整个流程与项目进行回归测试 , 一旦上线失败整个项目都要回滚 . 而微服务只需要回滚相应的模块即可)
- 稳定性高 ; 单个模块出现问题 , 其他模块仍可继续服务 . (例如电商系统中 , 如果订单模块故障 , 那用户还可以通过商品模块来实现商品浏览)
- 扩展性强 ; 可以根据不同的流量和压力 , 进行差异化个性部署(再如电商系统中 , 商品浏览量高 , 而下单量低 . 单机服务如果要部署两套的话 , 就得每个模块都有两套 . 而微服务可以部署两个商品模块 , 一个订单模块 , 比较灵活)
当然 , 微服务中也不是完美的 . 目前而言它存在着如下问题 :
- 维护成本增加 ; 需要部署/管理N个项目
- 问题追踪难度增加 ; 需要分析整个请求的调用链 , 逐步查看各个模块的日志
- 内容重复 ; 对部分业务 , 流程大致一致时 , 不能很方便的将代码封装 , 就导致在多个模块中有高度重复的代码 . 但如果将这些代码封装成一个公用模块供其他模块调用的调用的话 , 又违反了解耦的要求(即一方修改需求变动代码 , 另一方也会受到牵连) . 除此外还有日志重复 , 一个调用链可能要调用N个模块 , 每个模块可能都要记录下必要的参数响应等信息 . 这样就导致了日志的体积增大
- 增加开支 ; 标准的微服务部署方案 , 应做到服务隔离 , 即每个服务部署一个服务器器 , 这样的话就需要很多服务器 . 成本压力增加 . 当前主流方案是采用docker , 利用单服务器做多镜像隔离 . 但是docker不同于传统虚拟机的高度资源隔离 , 它仍然需要共享一些东西 . 就导致如果其中一个docker内核崩溃或占用共享资源 , 其他容器也会收到影响
3 . 理想与现实的差距
docker微服务架构实战,理想中的调用链 :

现实中的调用链 :

微服务设计的拆分纬度 , 服务粒度等都是很关键很重要的因素 , 如果没有一个好的架构设计 , 那后期微服务的维护成本 , 甚至会比单机服务更高更困难 .
4 . 微服务中的雪崩效应
微服务雪崩效应、如下图所示 , A为服务提供者 , B为A的消费者 , C是B的消费者

当A服务不可用时 , 导致B服务的不可用 , 并将不可用逐渐蔓延到C , 就发生了微服务中的"雪崩"现象
雪崩产生的过程 :
- 正常情况 , 一个请求进入C , C会从线程池中申请一个线程处理 , 然后请求B , 同时线程等待 ; B服务收到请求同样申请线程然后请求A , A处理完成返程结果并归还释放A自身的线程 , 然后BC依次完成响应并归/释放还线程
- A故障后 , B的线程请求A后 , 迟迟未得响应 , 线程阻塞等待
- C继续接收大量请求并传给B , 导致B大量阻塞线程等待 , 直到线程资源耗尽 , 无法接收新的请求 . B服务故障
- 故障继续蔓延 , C的线程资源耗尽后 , 一个请求再也不能完成 . 整个微服务当机
导致雪崩产生的原因 :
- 硬件故障 ; 服务器主机死机 , 或网络硬件故障导致服务提供者无法及时处理和相应
- 程序故障 ; 缓存击穿 , 缓存应用重启或故障导致所有缓存被清空 , 或者大量缓存同时过期 , 导致大量请求直击后端(文件或数据库) , 造成服务提供者超负荷运行导致瘫痪 ; 高并发请求 , 在某些场景下 , 例如秒杀和大促销之前 , 如果没有做好应对措施 , 用户的大量请求也会导致服务故障
- 用户重试 ; 用户忍不了界面上的一直加载或等待 , 频繁刷新页面或提交表单 , 这是在秒杀场景下的常规操作
- 代码逻辑重试 , 在消费者服务中存在大量不合理的重试逻辑 , 比如各种异常的重试机制等
- 大量的等待线程占用系统资源 , 一旦资源被耗尽 , 消费者这边也会发生连锁反应 , 然后会导致故障向下蔓延
深度解锁SpringCloud、雪崩的应对策略
- 网关限流 , 例如nginx等 , 防止大量请求进入系统
- 用户交流限流 , 改进用户等待页面的效果 , 提高用户等待时长 , 以及对提交按钮限制点击频率
- 缓存预加载 ; 对集中添加并且过期时间一致的缓存 , 适当的随机分配一些过期时长 , 防止集中过期
- 通过软件对服务监控 , 到达上限自动扩容
- 在特定场景下提前增加服务器
- 对调用服务提供者的线程进行隔离 , 单独开辟出一个线程池 . 即使这个线程池全部占用了 , 对其他请求的服务有限 ; 例如 , 一个商品页面 , 要展示商品信息 , 和评论信息 , 及购买记录等 , 那对每个服务的线程池都单独开辟 , 这样即使获取不到评论信息 , 那不耽误用户正常浏览商品的一些内容
- 对依赖服务进行分类优化 ; 强依赖服务(必须请求上级并获得结果) , 强制中断该业务 , 引导重试或返回错误 , 弱依赖服务(可以不获取上级结果 , 不影响整体业务) , 跳过故障服务 , 或做个标识后续执行补救措
- 对不可用的服务快速调用失败 . 即断路器降级方法 , 释放线程资源 , 确保服务稳定